AI video dubbing or translation has surged in popularity, breaking down language barriers and enabling communication across diverse cultures. While many paid services offer video dubbing, they often rely on proprietary black-box models outside your control. What if you could deploy a fully customizable, open-source video dubbing pipeline tailored to your needs?
With the right open-source models stitched together, you can translate videos on your terms. This blog walks through how users of Union can tweak parameters, scale resources based on input, reproduce results if needed, and leverage caching to optimize costs. This flexible, transparent approach gives you full command over quality, performance, and spend.
I dubbed a 16-second video for an estimated $0.50 using an AWS T4 instance. Enabling caching can further reduce costs. For example, if you need to update lip sync parameters, only the lip sync task needs to be re-executed, while other task outputs, such as voice cloning and text translation, are read from the cache. If you want to dub to a different language, the speech-to-text transcription won’t be re-executed as the task output for the previously dubbed language will remain the same.
Building your own video dubbing pipeline is easier than you think. I’ll show you how to assemble best-in-class open-source models into a single pipeline, all ready to run on the Union platform.
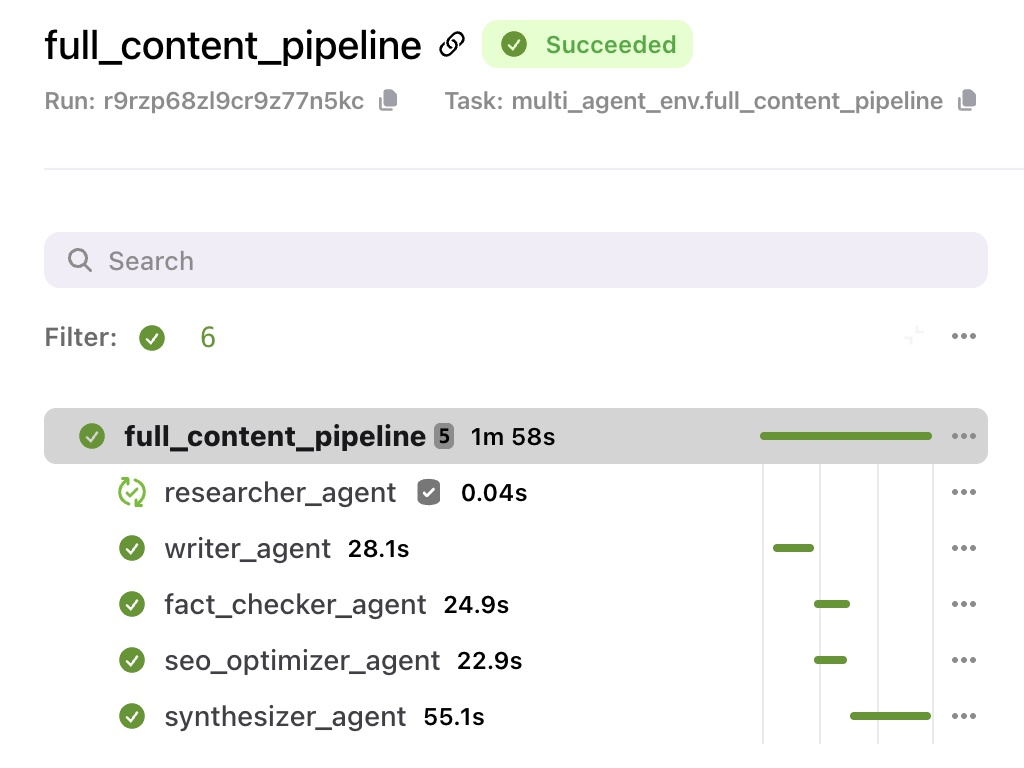
Before diving into the details, let's take a sneak peek at the workflow.
When you run this workflow on Union, it triggers a sequence of steps to translate your video:
- The pipeline starts by fetching the audio and image components from your input video file for further processing.
- Using Whisper, the audio is transcribed into text, enabling translation.
- The transcribed text is fed into the M2M100 model, translating it into your desired target language.
- Coqui XTTS clones the original speaker's voice in the target language.
- Finally, Sad Talker lip-syncs the translated audio to the original video, producing a complete translated clip with accurate lip movements.
Audio & image extraction
To enable transcription and translation, we need to extract audio from the video file, and for the lip sync model, we require a frame from the video. While the model typically selects at random, choosing the most representative keyframe using the Katna library could yield better results.
The `ImageSpec` utility captures all the dependencies, while the `ucimage` builder automatically builds the image remotely when you launch a remote execution.
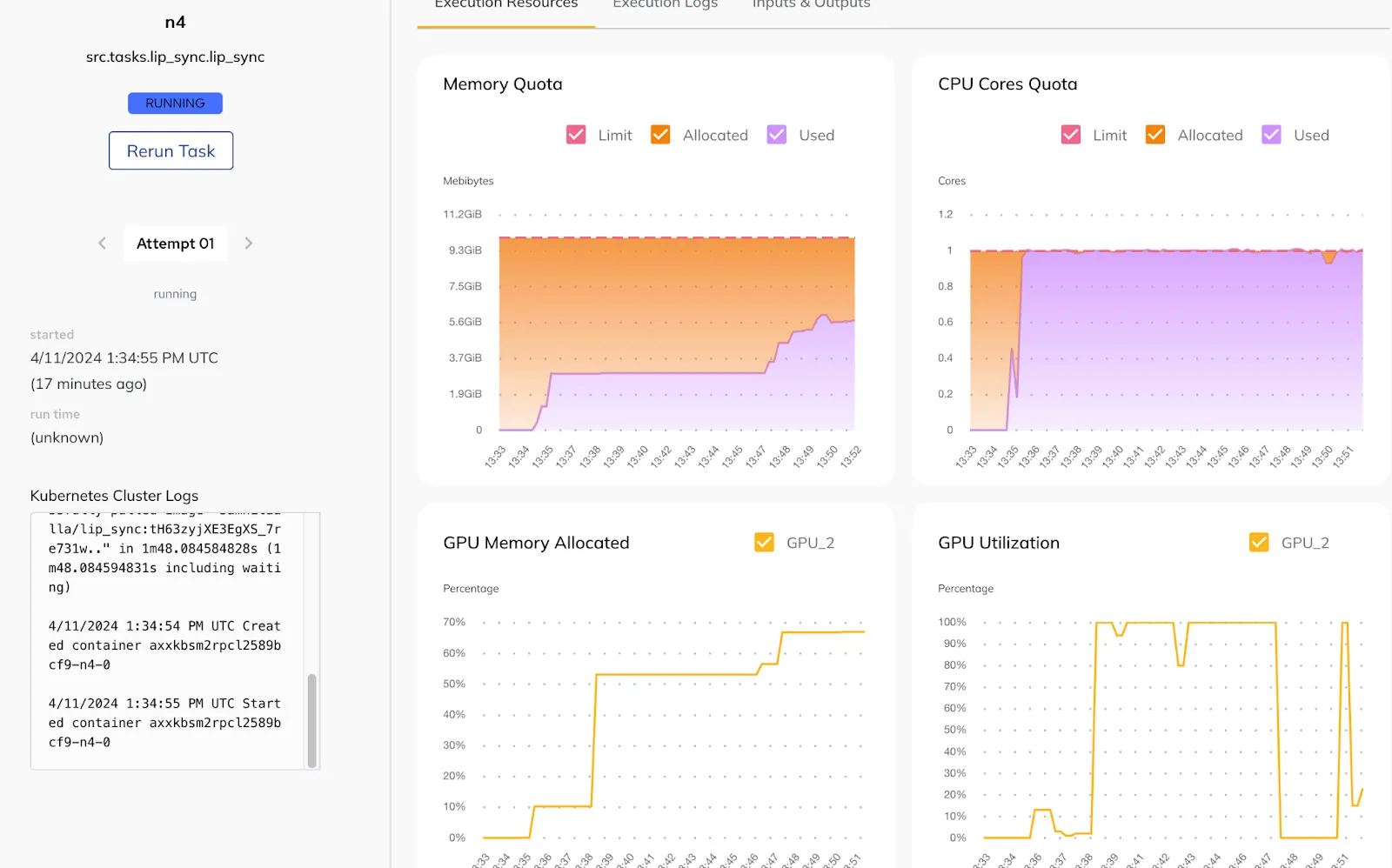
The `resources` parameter in the task decorator allows you to specify the necessary resources to run the task. You can also adjust the resources based on the task's consumption, as observed in the Union UI.
Speech-to-text transcription
The audio must then be transcribed to enable translation in the subsequent task. The automatic speech recognition (ASR) task enables transcribing speech audio recordings into text.
The `checkpoint` can refer to the Whisper model (for example, Whisper Large v2), but in reality, it can be any speech-to-text model. You can configure it to run on a GPU to speed up execution, and you can use an accelerator to select the GPU on which you want the transcription to run.
Text translation
The M2M100 1.2B model by Meta enables text translation. When executing the workflow, both the source and target languages need to be provided as inputs.
This task doesn’t require a GPU.
Voice cloning
The translated text is used to clone the speaker’s voice. Coqui XTTS clones the voice based on the provided text, target language, and the speaker’s audio.
The XTTS model supports the following languages for voice cloning, making them potential target languages for video dubbing as well:
If another voice cloning model supports a larger set of languages, you can also use that.
Lip syncing
Sad Talker model generates head videos based on an image and audio input. The model allows for adjusting various parameters such as pose style, face enhancement, background enhancement, expression scale, and more. The following code snippet outlines the inputs that the lip sync task accepts:
You can find the end-to-end video dubbing workflow on GitHub.
Running the pipeline
Note: Starting with Union is simple. Explore the unionai SDK to run workflows on the platform!
To run the workflow on Union, use the following command:
Once registered, you can trigger the workflow in the Union UI to translate your videos!
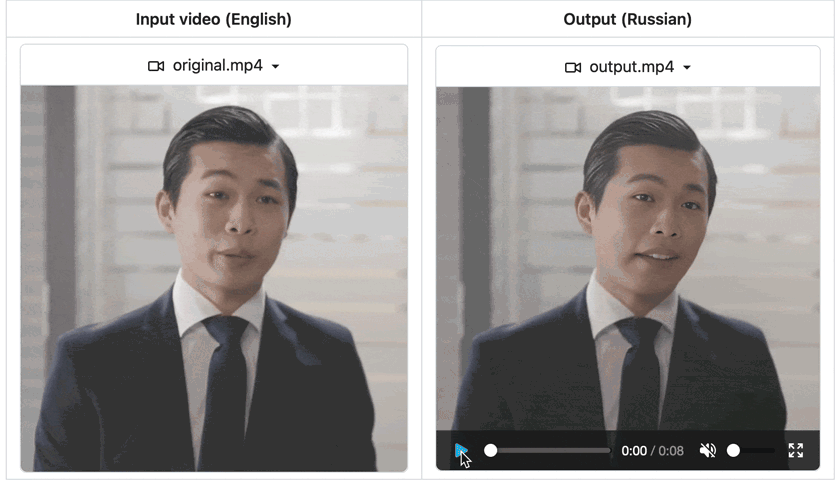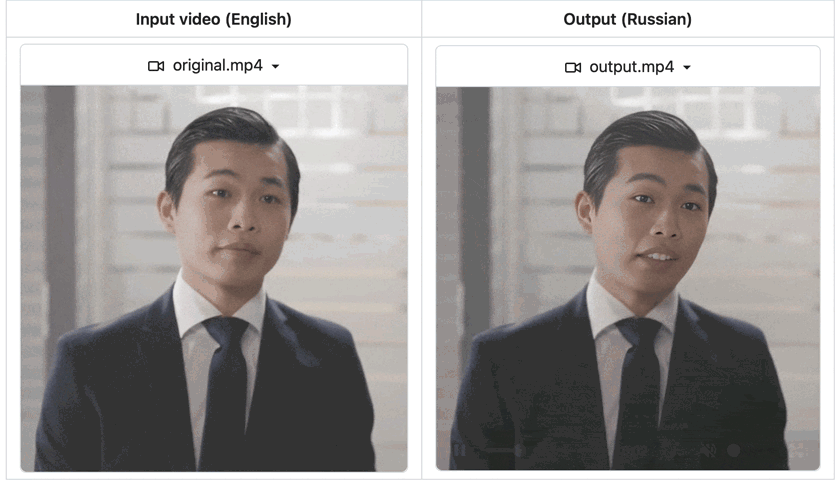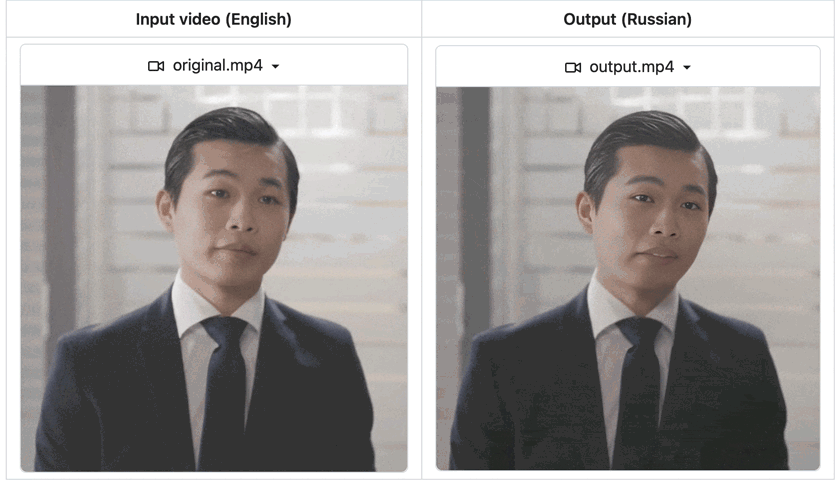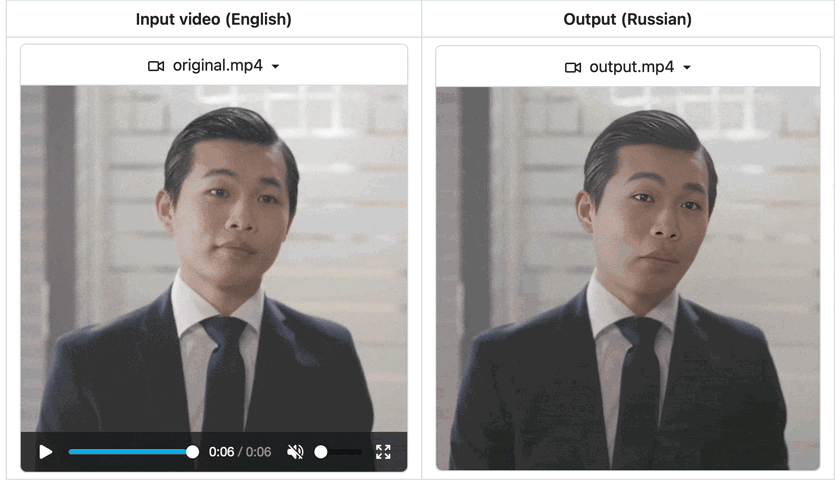
Outputs of our video dubbing application. The `still` parameter in the workflow is set to `True` because the Sad Talker model supports head motions. You can set it to `False` if `preprocess` is set to `crop`.
Key takeaways
What exactly does this video dubbing pipeline unlock?
- Each task has an associated `ImageSpec`, eliminating the need for a single bloated image containing all dependencies. You can also use different Python versions or install CUDA libraries to run on GPUs, providing a new level of dependency isolation. This reduces the chances of dealing with “dependency hell”!
- Within a single workflow, tasks can run on both CPUs and GPUs, and you can adjust resources based on the requirements of each task.
- You can easily swap out existing libraries with other open-source alternatives. The transparent pipeline lets you fine-tune parameters for optimal performance.
- The versioning and caching features of Union enable you to roll back to a previous execution with ease and avoid re-running executions that have already been completed, respectively.
- Reproducibility is the low-hanging fruit of Union that accelerates the iteration velocity while developing workflows.
- If you have Flyte up and running, you can also “self-host” this pipeline without relying on third-party video dubbing libraries.
Contact the Union team if you’re interested in implementing end-to-end AI solutions!