The AI development layer of your tech stack.
Build, ship, and scale AI faster than ever before.
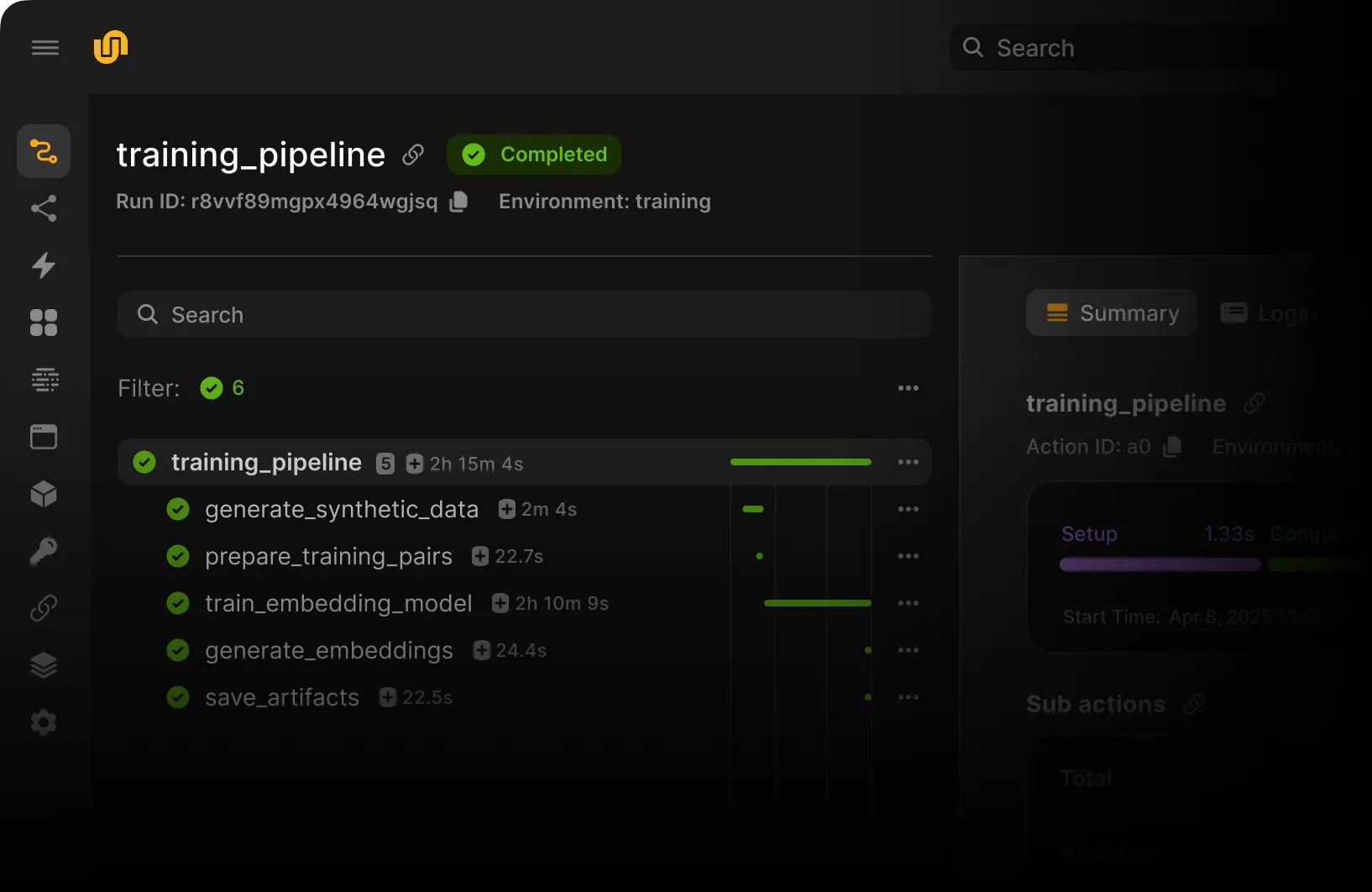
The AI development cycle, unified.
Accelerate AI/ML workflows and agents from experiment to production. Provision and scale resources on-demand.
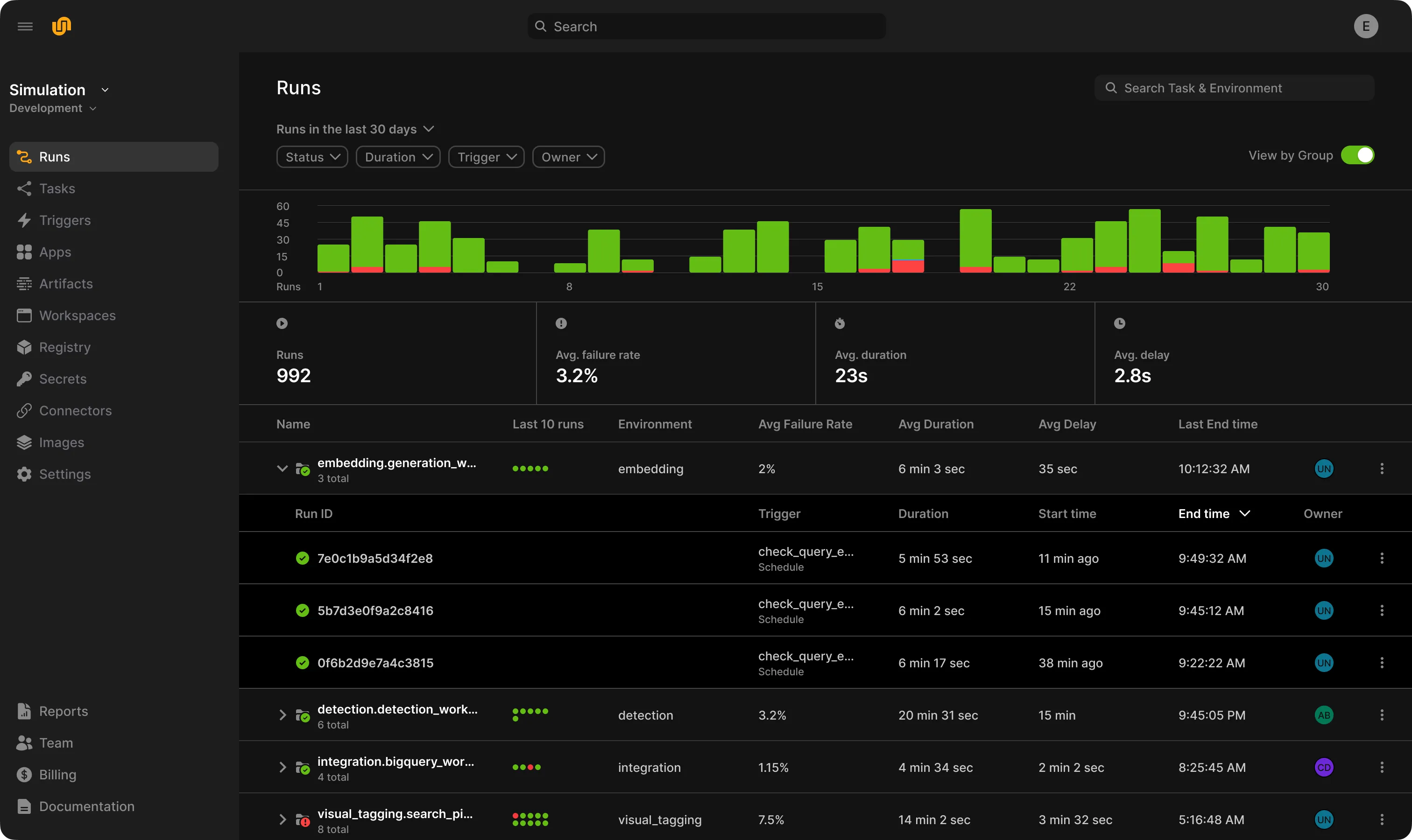
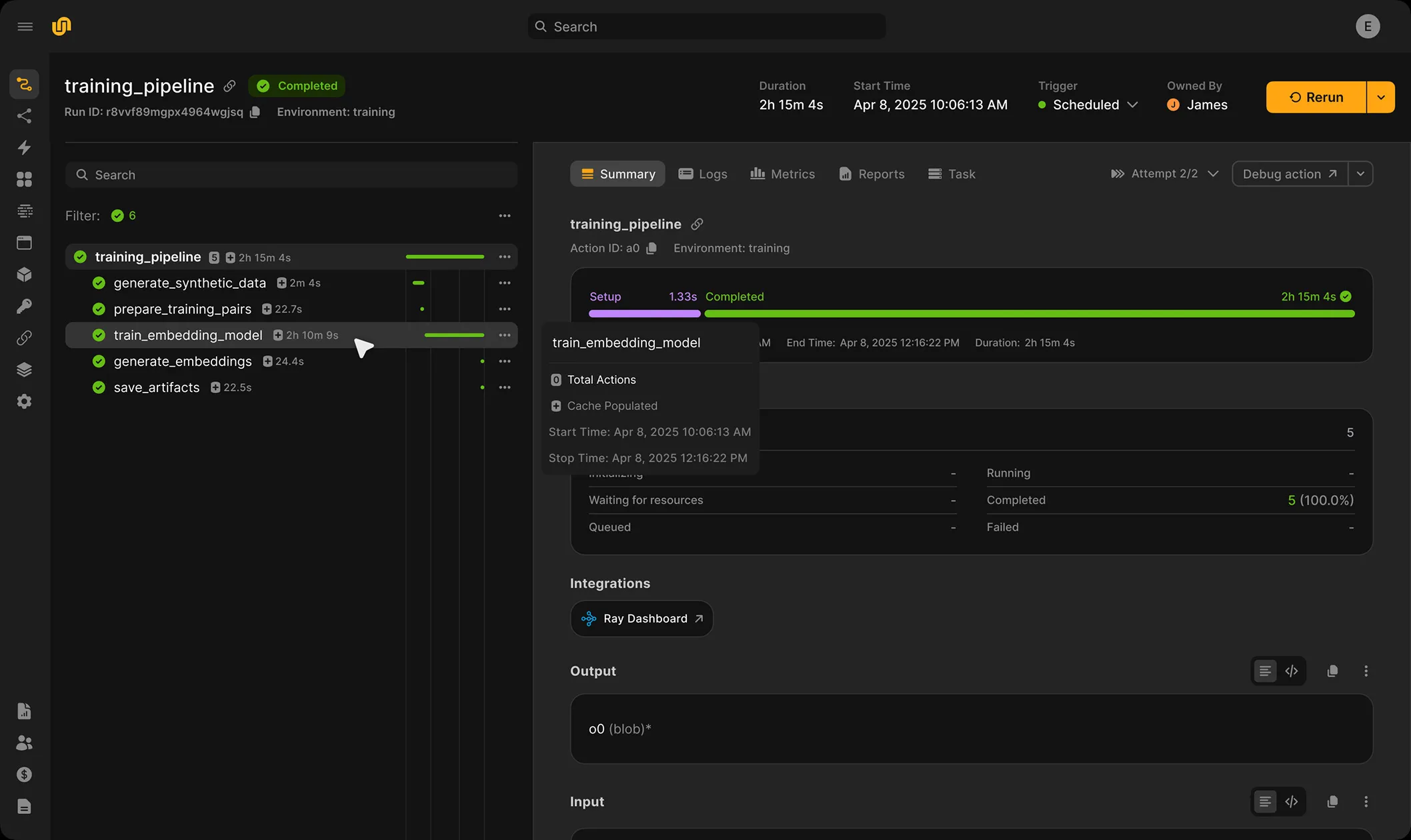
Scale model training effortlessly across clusters with automatic caching and reproducibility.
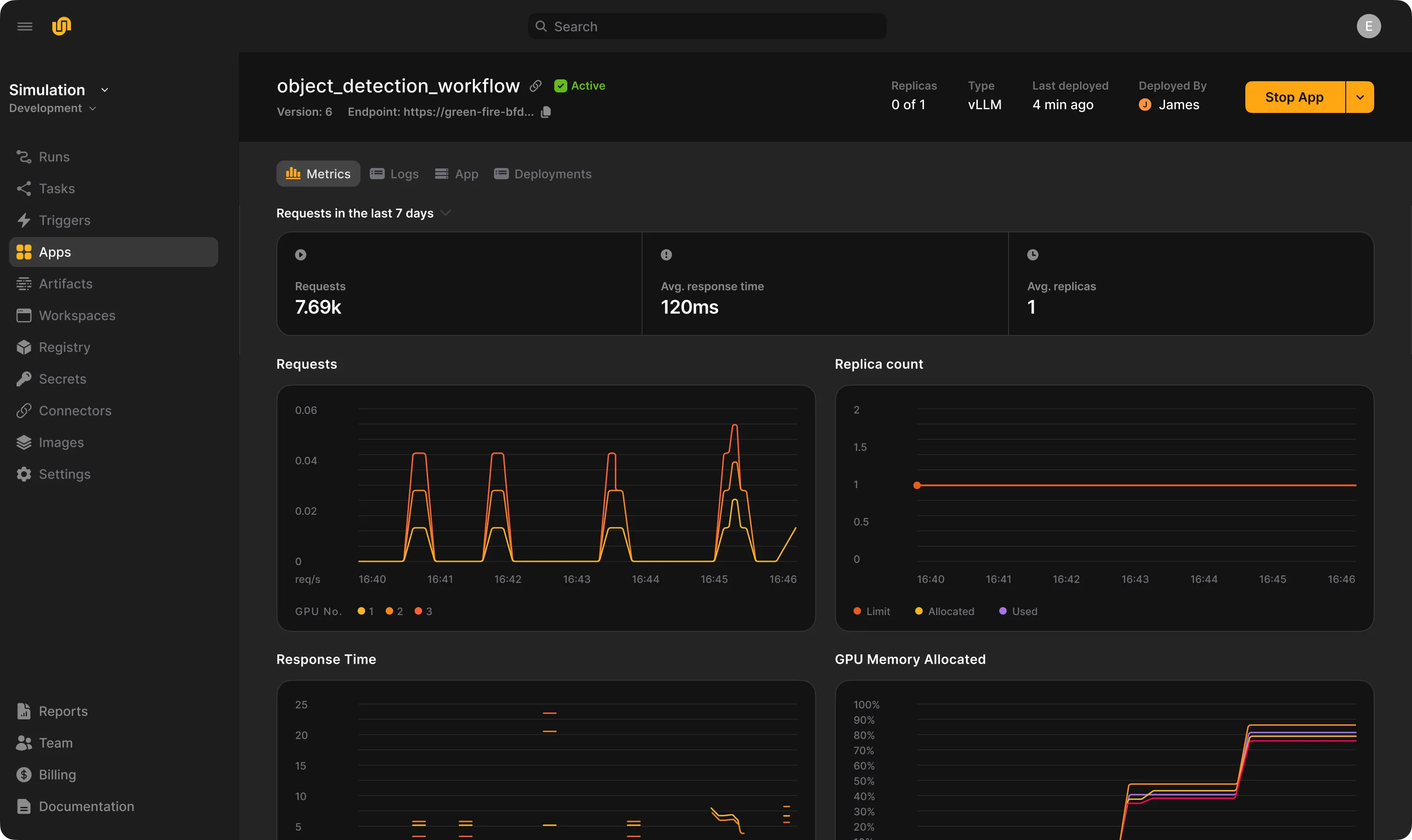
Perform real-time inference with ultra low latency on the same platform you use to train and orchestrate.
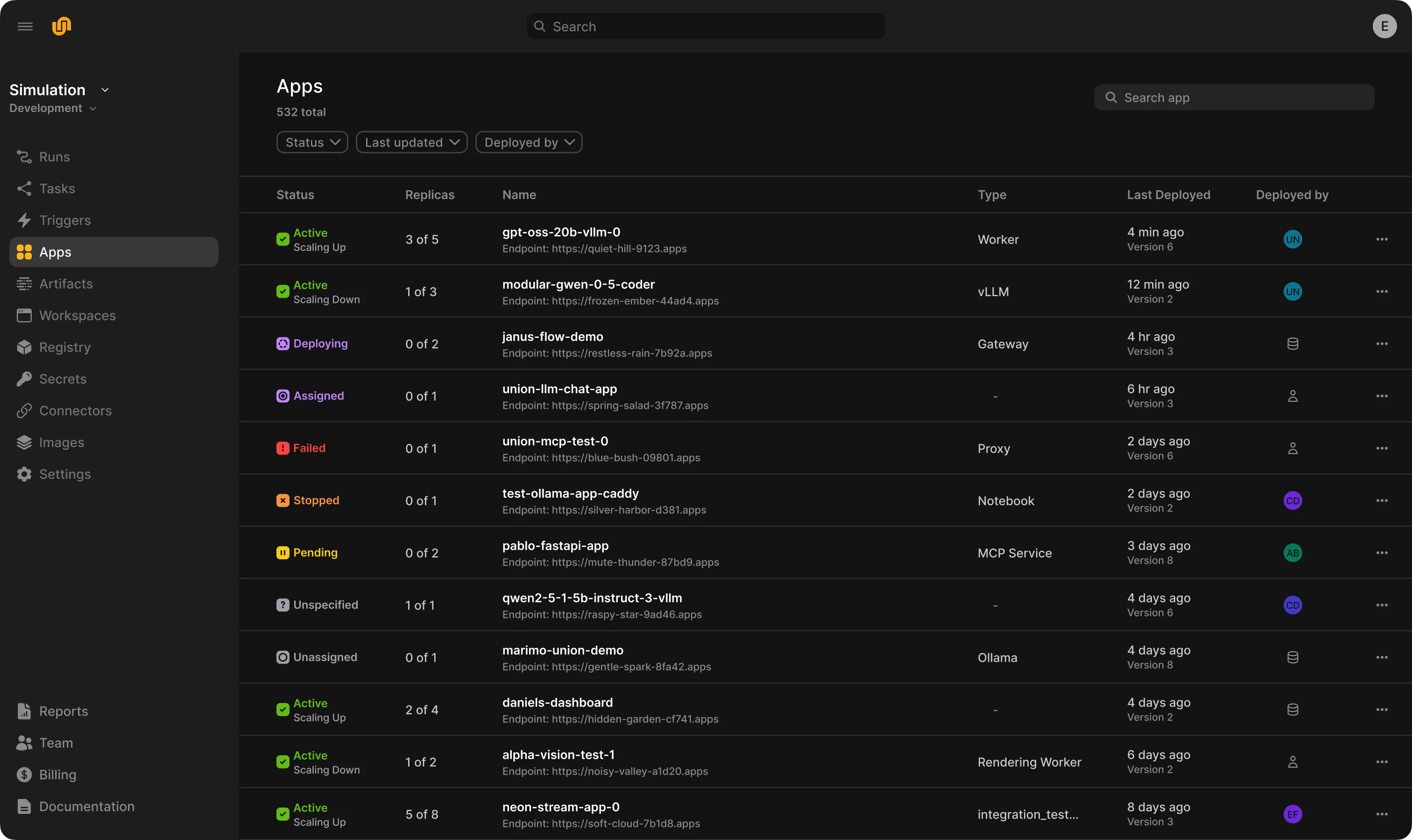
Gain visibility across the development cycle. Cost and usage allocation dashboards. Easily discoverable logs and failures.
Integrate deeply with data, models, and compute to build faster.
True agency for AI/ML workflows at runtime
Author in pure Python and enable custom branching, looping, and automatic retries at runtime with dynamic decision-making.
iteration time
actions/run
latency

Make workflows feel invincible
Build durable workflows that recover from failure automatically. Monitor and debug with logs streamed to the UI.
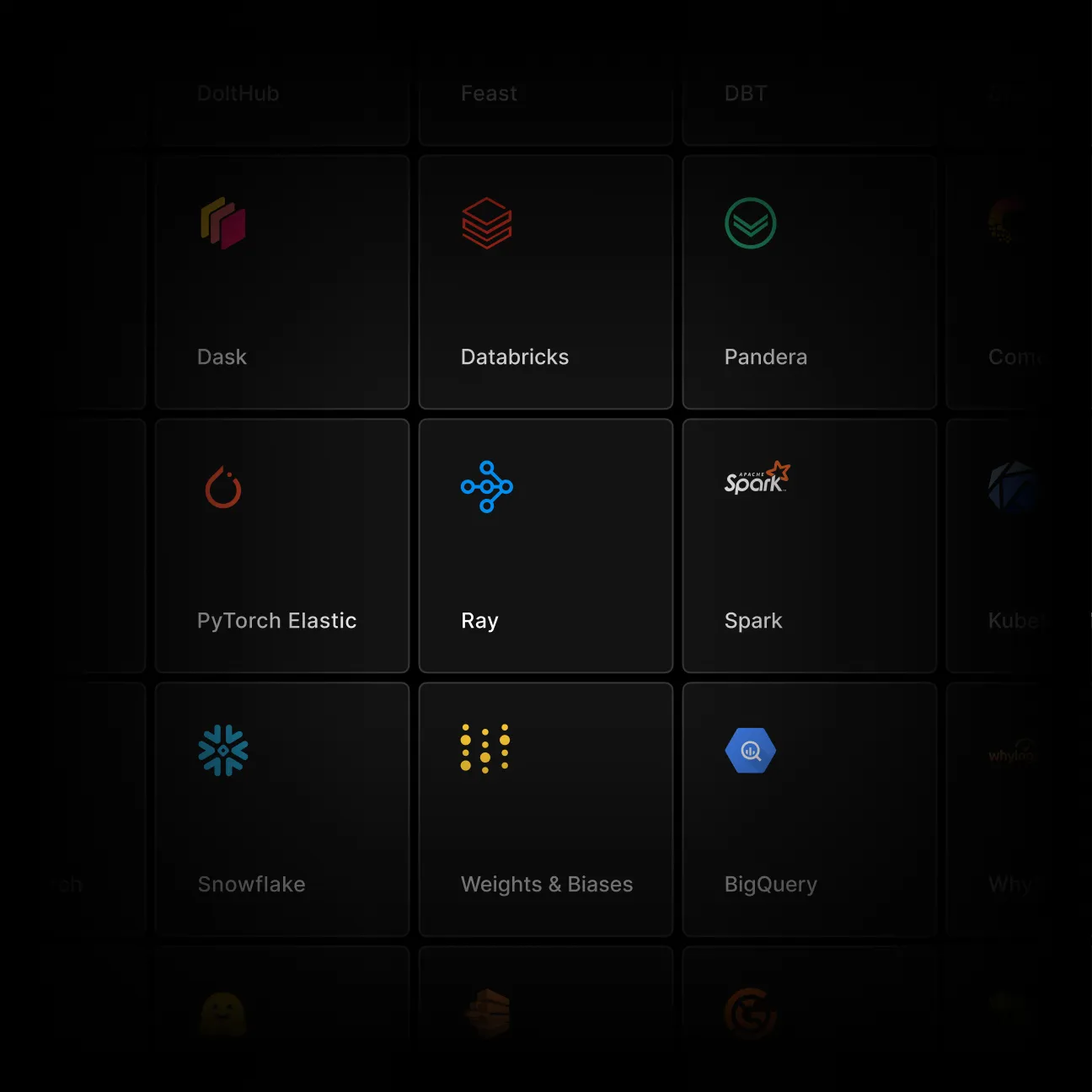
Integrate with the tools you love, no lock-in
Any cloud, any model, unstructured data. Spark, Ray, Dask, PyTorch, and hundreds more integrations.
“We want to simplify and not have to think about different technology stacks. We want to write everything in a Union workflow and have one platform for orchestrating these jobs; that’s awesome and less stuff for us to worry about.”

Thomas Busath
Machine Learning Engineer, Porch
Built for AI builders.
Accelerate engineers with tools to make their lives easier.
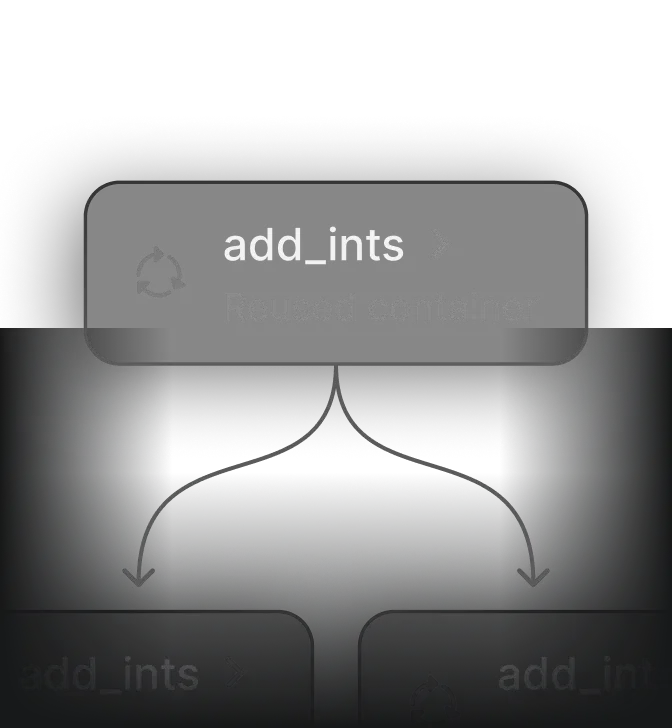
Reuse containers for <100ms task startup time
Use one warm-start, reusable container for all similar tasks.
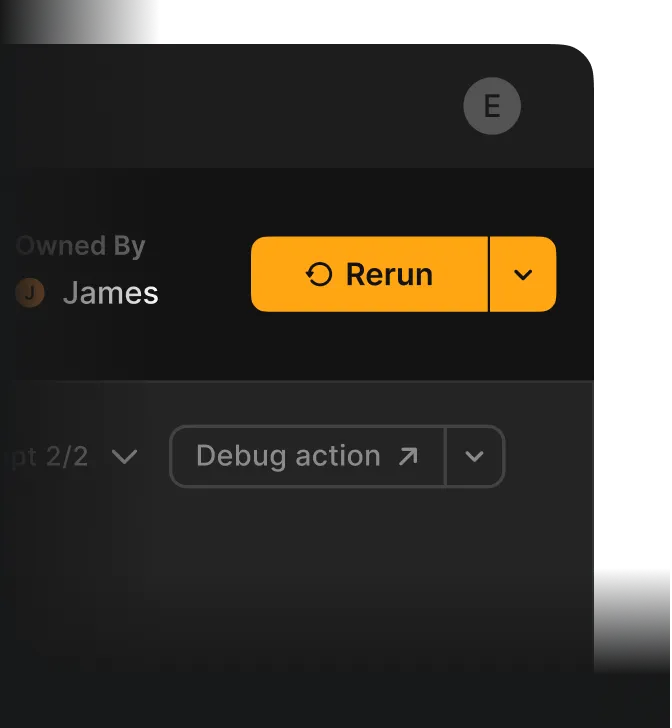
Debug button
Debug remote tasks you run, line-by-line, on the actual infrastructure where your tasks run.

Secure, private, and compliant by design
Protect data with enterprise-grade security and fine-grained access control.