Flyte 2 is dynamic, self-healing AI orchestration. Today, we're releasing two more major milestones on our path to a fully open source Flyte 2, and making them available at flyte.org.
Two more milestones on the journey to Flyte 2
Today, we're announcing two more major milestones in our journey to fully open source Flyte 2:
- A full Flyte 2 backend, installable as a devbox
- A completely reimagined Flyte UI
You can now run the full Flyte 2 backend on a single machine, explore the reimagined Flyte 2 UI, and discover the architecture that will power Flyte 2 for production.
When we released Flyte 2 for local execution in March, we gave you the SDK with…
- Pure Python authoring
- Durable agent workflows
- Terminal UI
- Async I/O, local caching, and local serving
- Observability
All this ran on your laptop without a cluster. That was the starting point.
Today's release is the next step: a real backend, a production-grade UI, and a much clearer picture of what Flyte 2 looks like at scale.
Flyte 2 Backend Devbox
With `flyte start devbox`, you can now spin up a mini Flyte cluster on your laptop or an EC2 instance and experience the full Flyte 2 workflow lifecycle. This ships with the complete backend, frontend, and object storage, all running on Docker containers. Full cloud deployment docs are coming soon.
We’re making this available now because we want you alongside every major step of our journey to make Flyte 2 the standard for OSS AI orchestration. It's designed to run on a single machine without having to deal with deployment manifests. But you get a real environment to build against, with actual scheduling, persistence, and the full API surface. Think of it as a self-contained Flyte 2 backend you can run anywhere.
What you can do with the devbox
- Run real workflows end-to-end: agentic, ML, and data workflows on a lightweight orchestration platform with full durability and observability.
- Build against the real architecture: the devbox runs the same backend that will power production Flyte 2, so the code you write today carries forward.
- Iterate locally, deploy with confidence: test workflows in a real cluster environment without provisioning cloud infrastructure.
The Flyte Devbox is a chance for you to demo the truest representation of Flyte 2 in open source yet. It previews what it means to use dynamic, self-healing AI orchestration. This improved demo experience also means we’ll no longer support Union Serverless.
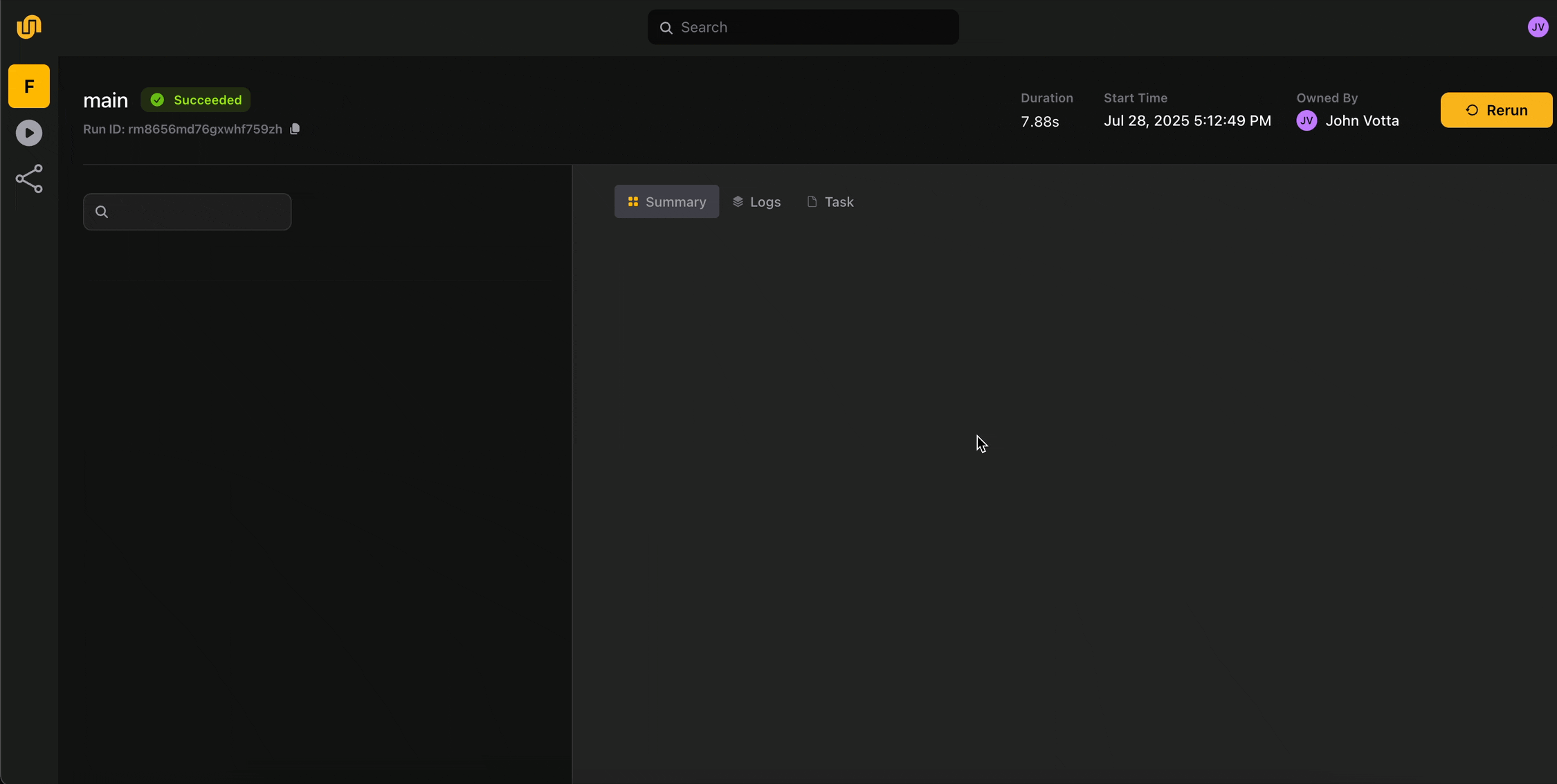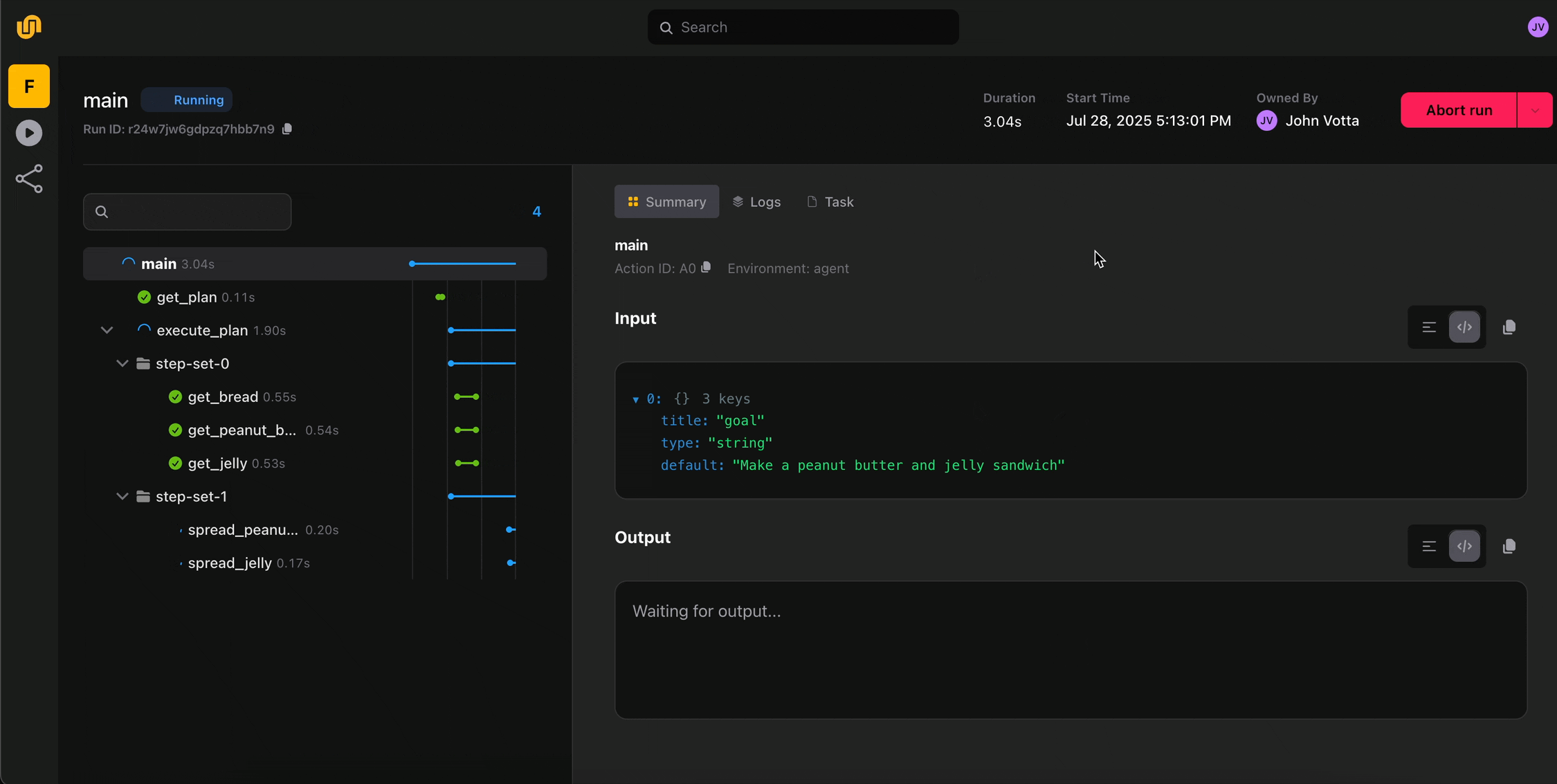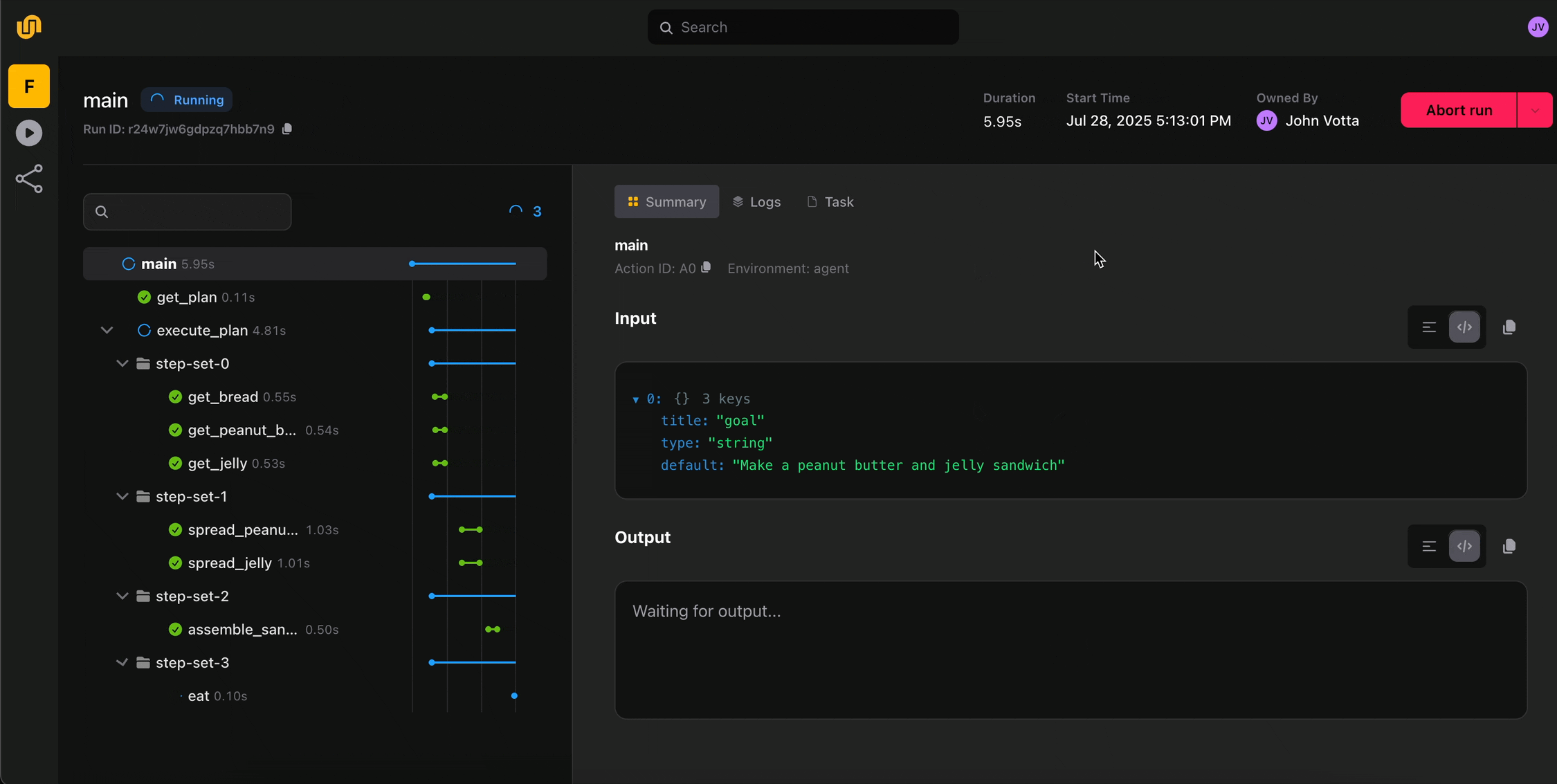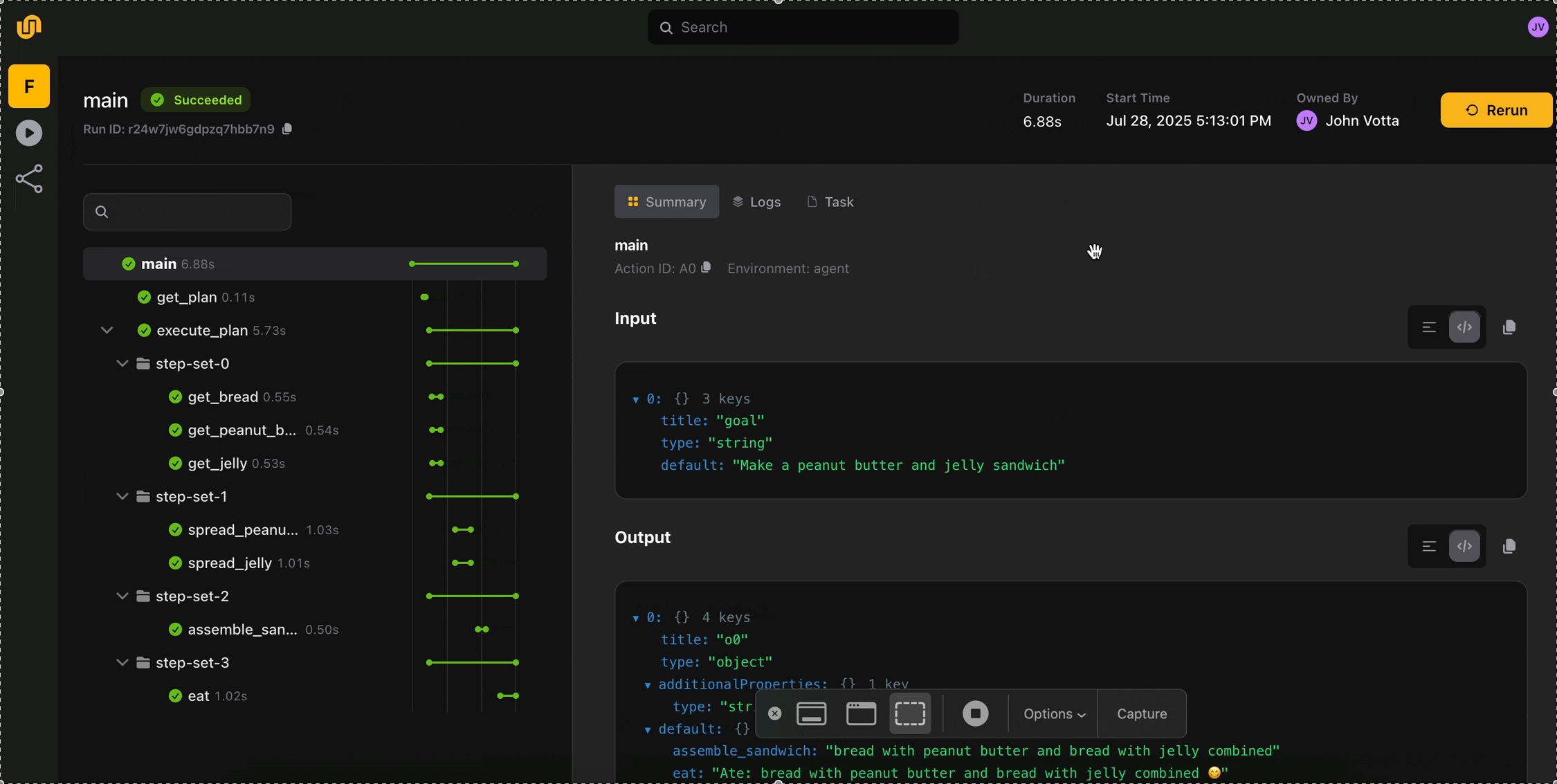
A completely reimagined Flyte UI
Alongside the devbox, we're releasing a reimagined Flyte UI. This is a meaningful subset of the UI for Union.ai, the enterprise Flyte platform. It reflects over two years of production UX progress made thanks to our incredible community of developers.
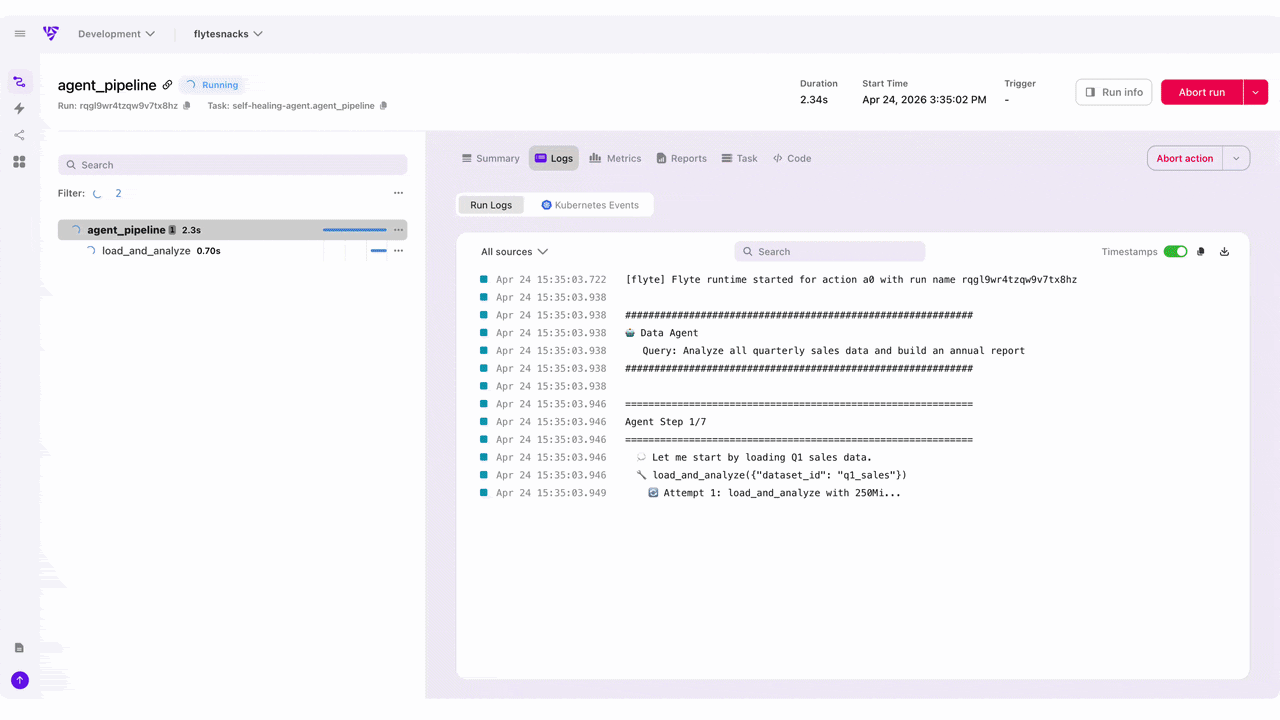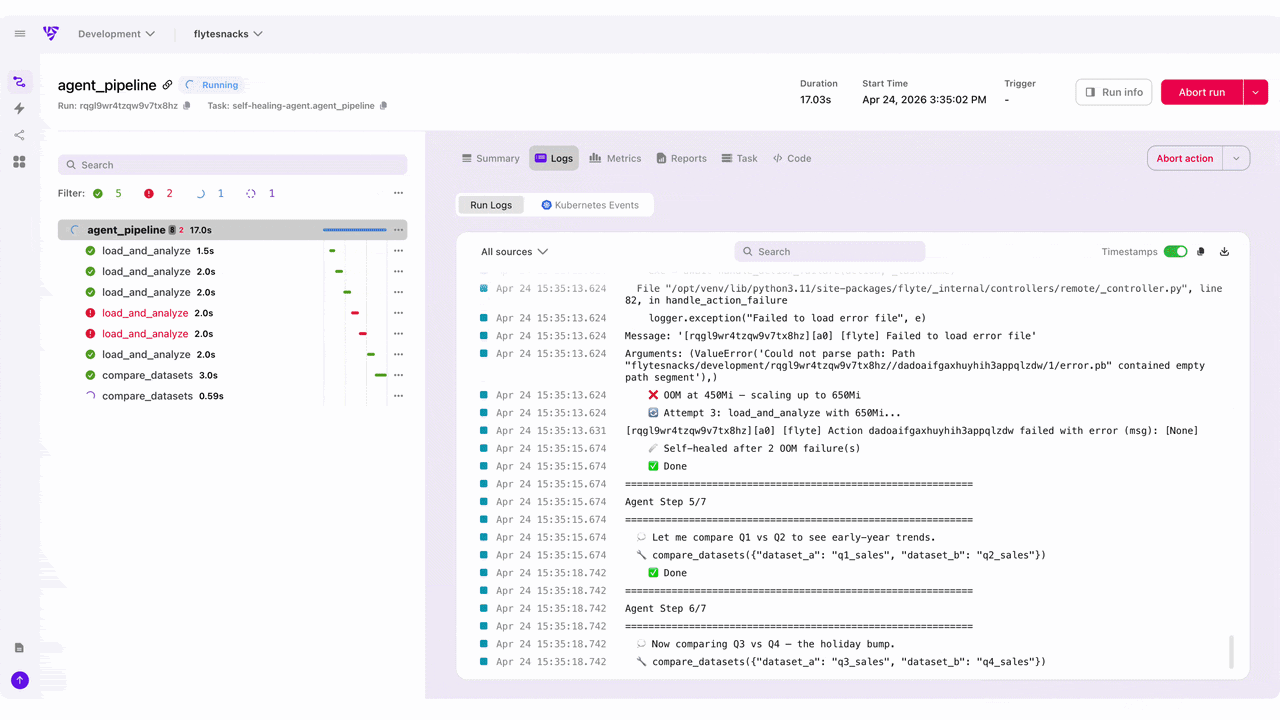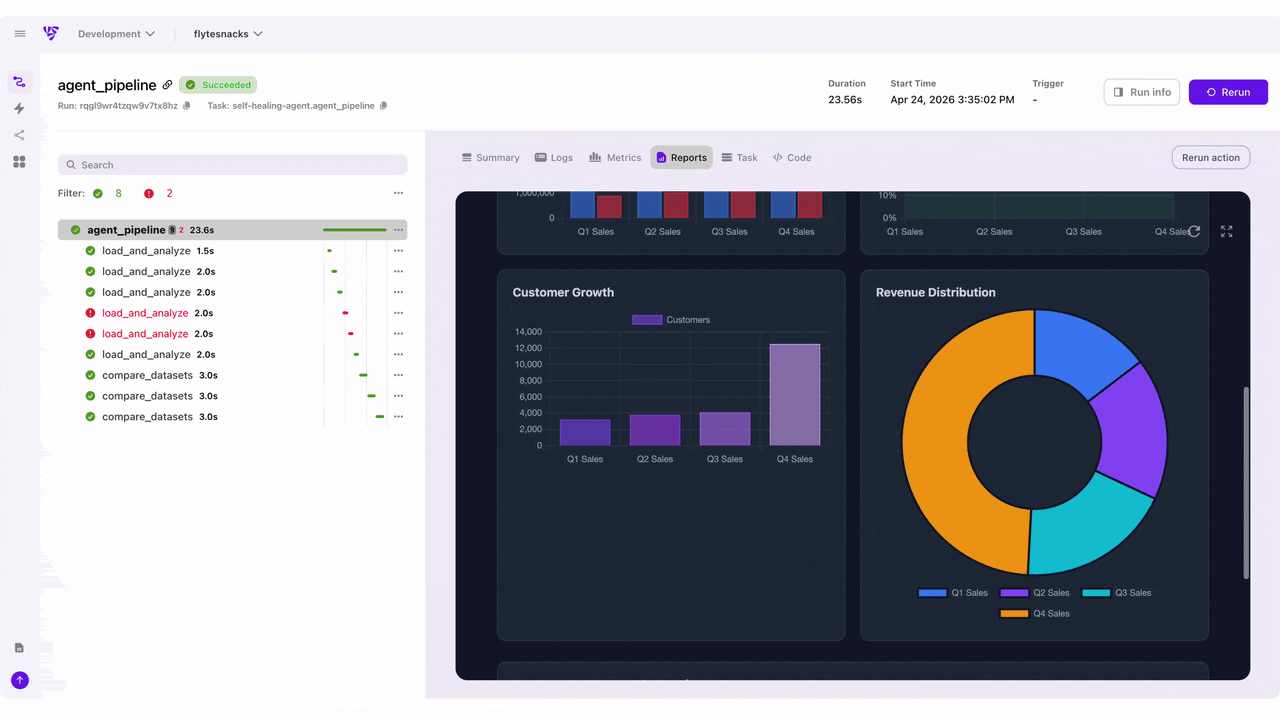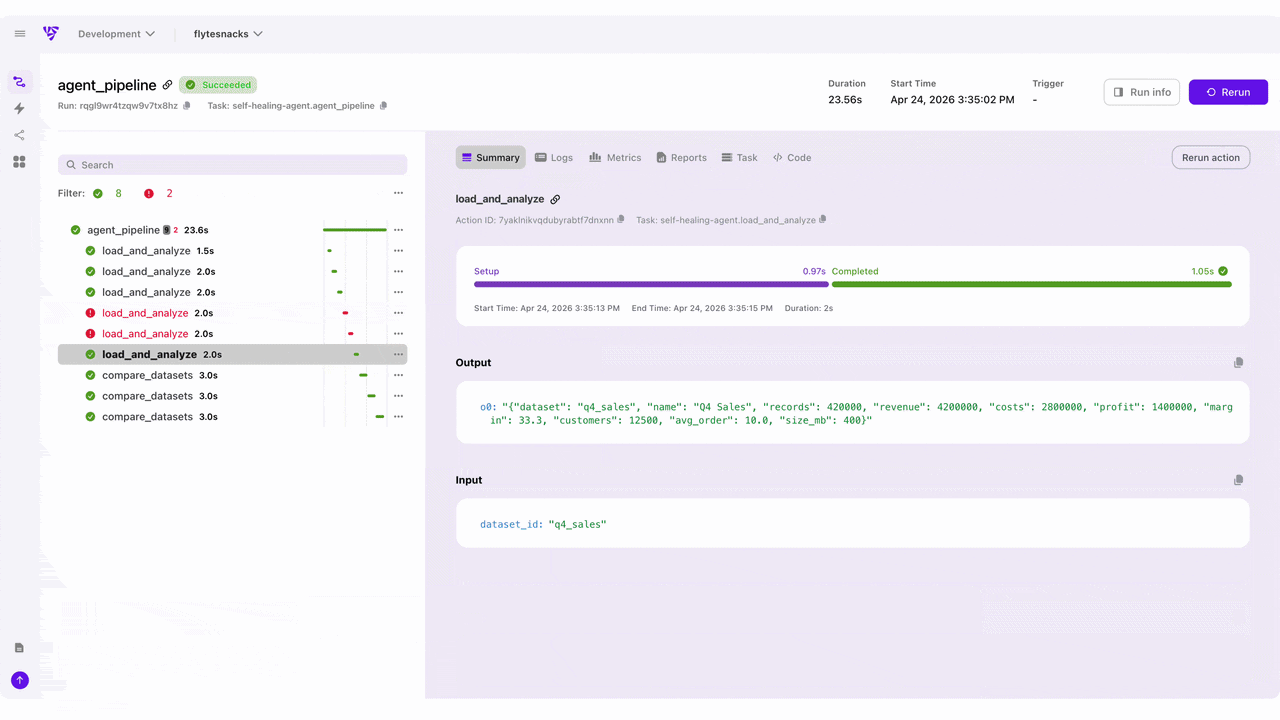
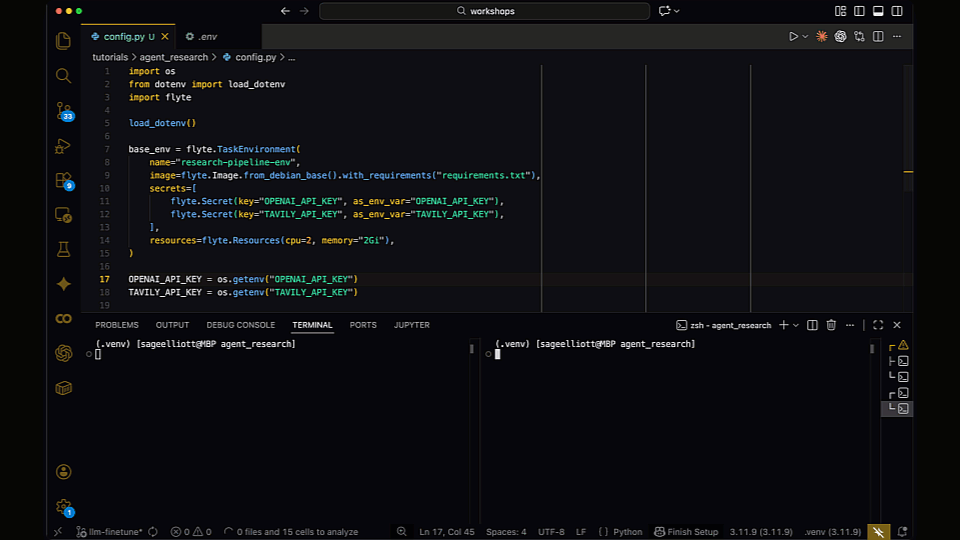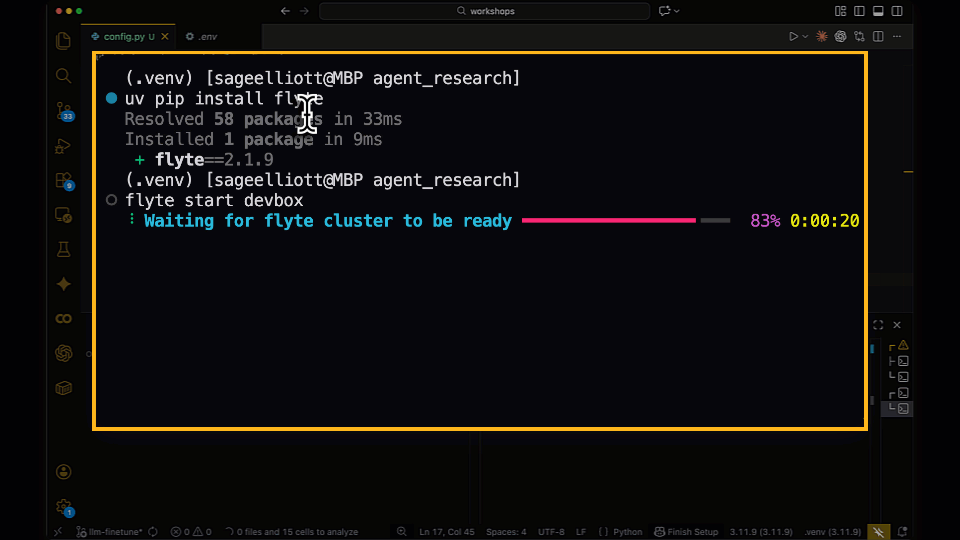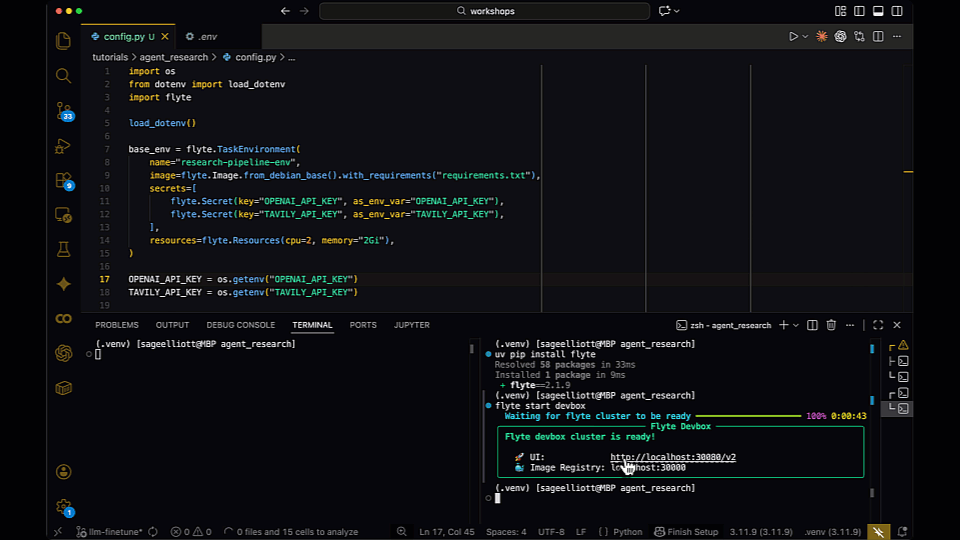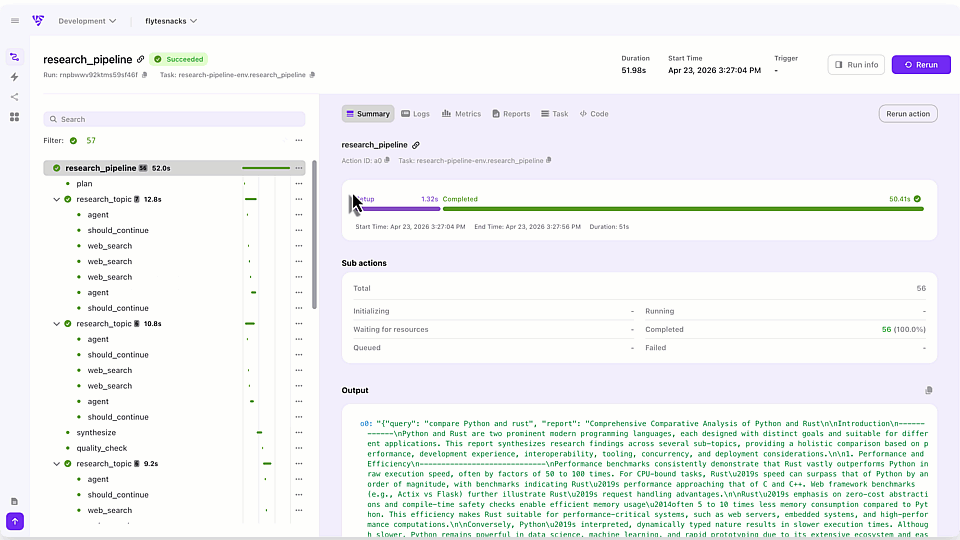
Here are the upgrades most loved by the community members who have tried the new Flyte UI:
- Real-time execution visibility
The UI surfaces real-time execution state, logs, and failures at every step of your workflow. Catch errors as they happen and act on them. No more digging through logs to figure out where something broke. - Dynamic workflow visualization
Flyte 2 workflows are dynamic with branching, loops, runtime decisions. The new UI actually visualizes this. - Execution timelines and run history
For long-running workflows, the UI provides execution timeline support so you can see exactly where time is being spent. It also shows the full history of runs and deployed tasks, which can be triggered directly from the UI. - Self-healing observability
When Flyte 2 auto-recovers from a failure, the UI shows you exactly when and how it happened, so you have full transparency into the self-healing behavior that makes Flyte 2 unique.
The Flyte 2 community is building
Since we launched the Flyte 2 beta, the community has shown up in a big way:
- 700,000+ Flyte 2 downloads
- 78 releases
- ~800 commits
- ~900 merged pull requests
- 44 unique contributors
We also want to spotlight and say a massive thank you to our community member, André Ahlert, for some incredible contributions:
A place to discover community-built Flyte integrations for data processing, ML training, experiment tracking, and more.
Flyte 2 on the Visual Studio Marketplace
Bringing the Flyte 2 development experience directly into VS Code.

A huge thank you to everyone who has contributed code, filed issues, tested beta releases, and shared feedback. You're shaping the future of open source AI orchestration, and we’re incredibly grateful for you.
What’s next: the road to production
Today's release is another major step, but it's not the finish line. Here's where we're headed:
Our next milestones are releasing a production-grade Flyte 2 backend with single-cluster support for distributed execution and multi-cluster support after that. This is a fault-tolerant, open-source backend that will bring everything – autoscaling, resource awareness, and resilient state management – to production environments.
Every release brings us closer to a fully open source Flyte 2, and we're building it in the open with our community.
Get started
Run the `flyte start devbox` on your machine and explore the new Flyte 2 capabilities & reimagined UI.
<div class="button-group is-center"><a class="button" target="_blank" href="https://www.union.ai/docs/v2/flyte/user-guide/run-modes/running-devbox/">Try Flyte Devbox</a></div>