
As generative AI models become more capable and deployed in various contexts, optimizing the model in terms of throughput and memory consumption is essential. For AI engineers, this type of performance tuning can help save GPU compute resources and improve the user experience of your application. In this blog post, we reproduce the results from Pytorch's Segment Anything Fast blog post with Union and NVIDIA DGX cloud. We will demonstrate how seamlessly you can connect your workloads from your existing environments like AWS and scale up using DGX clouds massive GPU resources using Union's Agent Framework. Moving between clouds and scaling is literally a single-line change!
Overview
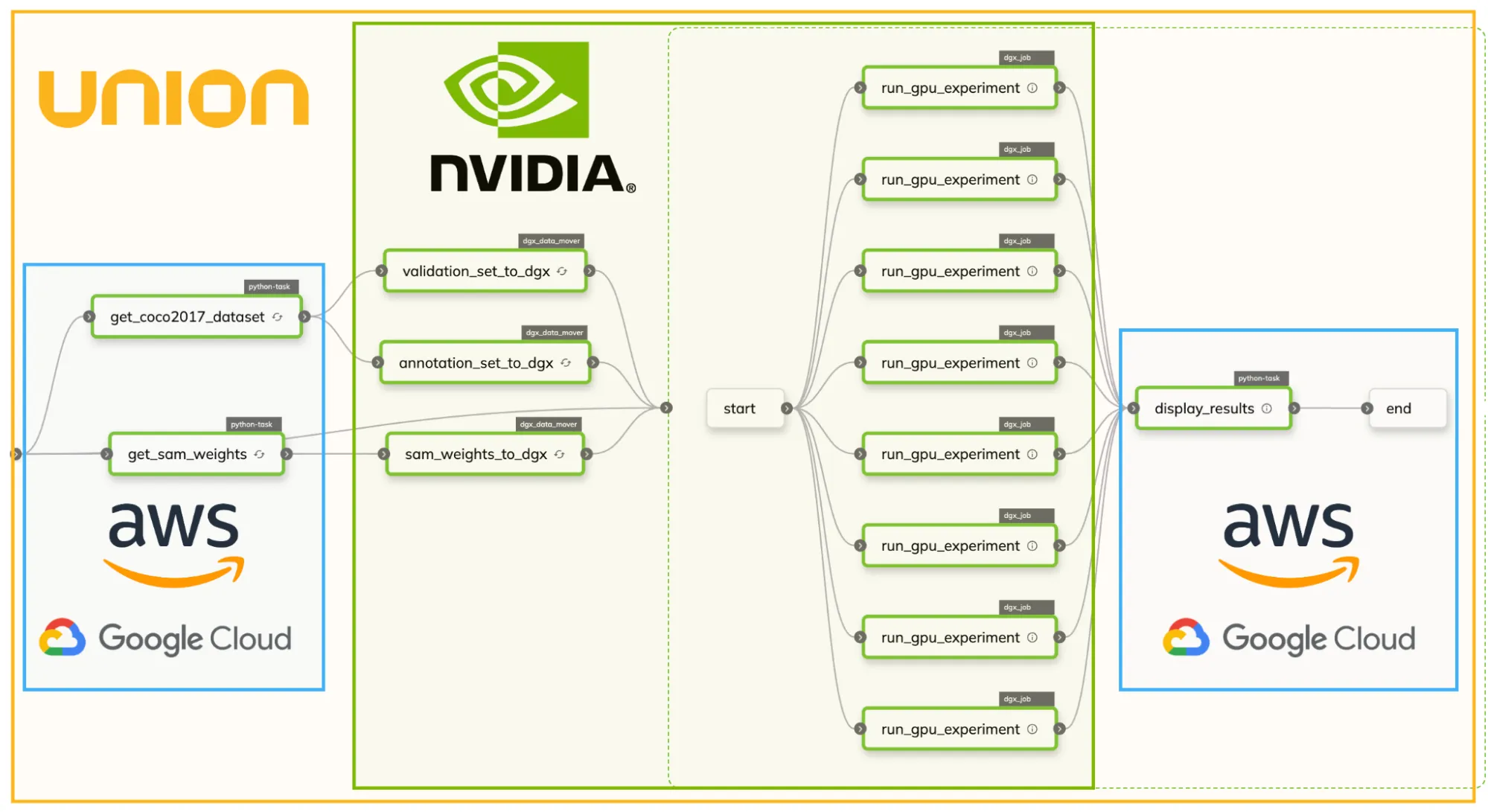
At a high level, the performance tuning experiment is a Flyte workflow that includes data handling, GPU computing, and visualizing results. We run everything with Union's seamless multi-cloud integration system to leverage AWS, GCP, and NVIDIA DGX Cloud.

The left-hand and right-hand nodes represent tasks running on AWS or GCP, while the middle section runs with GPUs on DGX cloud. We scale up to 8 GPU experiments running the Segment Anything Model with different performance optimization techniques.
DGX Agent
We built Union with Flyte to specify workflows using annotated tasks, providing an interface to scale and deploy any AI workload. When writing code with flytekit for Union, @task decorator already makes it simple to obtain GPU resources with the Resources API:
Flyte's Agent is an extension mechanism that empowers Flyte to connect to additional systems. In collaboration with NVIDIA, we developed a special Agent that connects your Union instance to DGX cloud for seamless orchestration across AWS or GCP and DGX cloud. With this DGX agent, running a Flyte task on DGX Cloud is a one-line change!
If you need more GPUs for a single task, we can set the instance variable to dgxa100.80g.8.norm, which will run the task with 8 A100s.
The Segment Anything Fast optimizations require NVIDIA GPUs with at least the Ampere microarchitecture available on DGX Cloud. In our experiment workflow, we scale out to run eight different optimization experiments, where each experiment has access to its own A100. If we update the underlying model, add a new optimization strategy, or update dependencies like PyTorch, we can rerun the same workflow and quickly get feedback!
Data Cache and DGX Data Mover
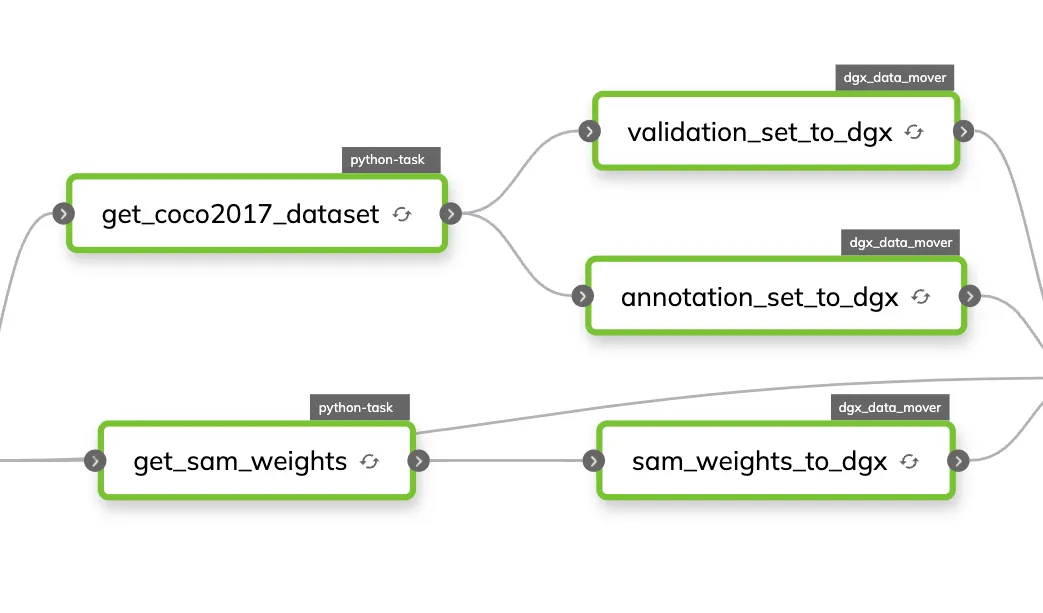
In the left-hand section, we have the model's weights and evaluation dataset downloaded on AWS servers and then moved to DGX cloud. There are two Union-supported data access strategies: streaming directly from AWS or making a one-time move to DGX's dataset abstraction. The latter is better because the GPU-powered machines can quickly access the data for repeated use, which improves GPU utilization. In code, the DGX data mover is a Flyte task that performs the one-time move of a Flyte file or directory into DGX:
Given that the data for our experiments is static, we cache the output of the data tasks. When we rerun experiments or add new ones, they all start quickly using the cached data.
Visualizating Results
After DGX cloud completes all the experiments, we transfer the results back to AWS for analysis. In the final task, we display the throughput and memory usage in a Flyte Deck:

The plots reproduce the results from PyTorch's blog post. The nested tensor (NT), quantization (int8), and semi-structured sparsity (sparse) strategies give the most throughput and memory efficiency. All new optimization strategies perform better than the 32-bit floating-point baseline.
Closing
With Union's DGX integration, scaling out GPU experiments on NVIDIA DGX cloud is as easy as a single configuration change. We get the best of both worlds by leveraging Union for data handling, workflow management, and visualizations while accessing powerful GPU resources on DGX Cloud. If you are interested in Union or DGX Cloud, please message us or connect with our team on Slack.

.webp)