Introduction
The vast majority of AI applications today are powered by batch workloads. From ETA estimation, to sequence alignment, image processing, and recommendation systems, batch processing provides an efficient mechanism to run many similar workloads in parallel, saving resources and time while still meeting latency requirements. In this context, we will explore the specific challenges of running batch workloads on Kubernetes (“K8s”) for AI platform engineers and examine how Flyte, the open-source AI orchestrator, is designed to address these issues.
Container orchestrators like Docker Swarm, Nomad, and K8s were initially designed to streamline the deployment, versioning, and load balancing of long-running services. These services, typically packaged as Docker containers, are generally stateless, allowing for horizontal autoscaling (e.g., deploying new instances under load) and efficient load balancing. This setup enables moving pods for better bin packing, IP assignment, and network route configuration.
Developers have begun to leverage these orchestrators for running batch workloads in the AI domain. However, these workloads have distinct characteristics that add requirements to the orchestration layer:
- They frequently process large amounts of data for data preparation and training purposes
- They often rely on data produced by other batch workloads
- Run on heterogeneous hardware (some requiring GPUs, others are memory heavy… etc.)
Batch workloads can be unit tested on sample datasets locally but require iteration on full samples (which requires specialized compute) to identify edge cases. Various challenges emerge as AI developers attempt to use K8s to orchestrate batch workloads. We will use an example of training a model on GCP and show what challenges face AI developers and how flyte can be used to alleviate them.
Running a fraud detection model training job
Consider a model training job to train a fraud detection model. GCP has a walkthrough on how to do that on GKE (Google’s Kubernetes Engine).

There is a lot to unpack in this diagram; Users need to familiarize themselves with core Kubernetes concepts YAML configuration, shell scripts, networking considerations for transferring data in and out of the cluster; setting up and consuming Redis Queues, and setting up and using Kubernetes Jobs to pull from the queue.
While this is already a set of challenging tasks, users can probably follow the guide and get this working. However, there are a set of challenges that start to arise when users start scaling similar but custom jobs, sharing the cluster with others, or increasing the complexity of the job.
Challenges in Scaling Batch Workloads on Kubernetes
Kubernetes (K8s) addresses several fundamental requirements for running batch workloads, making it an appealing choice for enterprises to run all container workloads. It provides a containerized environment, enabling resource sharing among multiple users, allows retries, offers basic observability out-of-the-box, facilitates scheduling, and enables mounting of storage and other resources. However, when attempting to implement this in practice, three main categories of issues arise:
- Resource Management: Kubernetes must effectively manage resources to handle batch workloads, including addressing resource contention, improving utilization, and supporting multi-tenancy.
- Handling Large and Business-Critical Data: Batch workloads often involve processing vast amounts of critical data, which necessitates robust mechanisms for determining dataset readiness, transferring models, iterating on data preparation code without compromising models, and specifying expectations for dataset schema and outputs.
- Operational Scalability: Running Kubernetes at scale for batch-style workloads presents operational challenges. The Kubernetes API is not designed for massive scalability, leading to potential rate limits, increased memory usage, crashes, and instability when scheduling a large number of pods simultaneously.
While Kubernetes provides a solid foundation for running batch workloads, addressing these three key areas – resource management, data handling, and operational scalability – is crucial for enterprises to successfully deploy and manage batch workloads on Kubernetes at scale.
Existing Solutions for Running Batch Workloads on K8s

There have been many attempts at solving these issues. Several existing solutions, such as Volcano and Karmada, provide frameworks for running batch workloads on K8s. However, they still face challenges in addressing data awareness, job dependencies, and efficient resource allocation (let alone user-friendliness). Karmada (Kubernetes Armada) is one of the most promising projects in this space. It addresses some of the fundamental limitations (i.e. Gang Scheduling, out of cluster scheduling and multi-cluster multi-cloud support) while maintaining a clean abstraction on top. Kubeflow and other ArgoCD-based tools, on the other hand, do address dependency awareness but are limited to a single cluster. None of the reviewed tools, however, addresses the data awareness, iteration speed, observability, or container build and maintenance challenges.
Union: The AI Orchestration Platform
Union is built on the open source project Flyte. Flyte is a powerful orchestration engine that addresses the limitations of existing solutions for running batch workloads on K8s. It provides a comprehensive solution for managing batch workloads, including data awareness, job dependencies, and efficient resource utilization. Union improves on Flyte core functionality and extends its capabilities to address a wider set of use cases.

Why Flyte?
Flyte offers an advanced abstraction layer for defining and managing batch workloads, featuring:
- High-level DSL: Flyte’s python DSL allows users to package container image specifications, execution units, and data flow dependencies in a maintainable format.
- Local execution: Ability to execute the workflows locally, which does not need to use cluster resources. This is great for identifying bugs and testing the end to end flows on smaller datasets.
- K8s native: Flyte runs natively on K8s, making deployment, rollout, and updates familiar to existing platform teams while benefiting from prior solution improvements.
- Out-of-cluster scheduling: Flyte maintains workflows in its durable storage (Postgres DB), handling retries and backoffs to adapt to cluster load, caching outputs to avoid unnecessary work, and supporting multi-tenant and multi-cluster/cloud environments.
- Strong typing: Flyte's strong typing helps avoid common issues, particularly in collaborative environments, by ensuring clear interface definitions and evolution. Strong typing allows for statically catching incompatible interfaces at compilation time, avoiding launching expensive jobs that inevitably fail.
- Data awareness: Flyte's awareness of data types and pointers allows for sandboxed executions, ensuring reproducibility, preventing data corruption, and deterministically caching outputs on success.
- Versioning & immutability: All Flyte entities are versioned and immutable, allowing users to pin dependencies and develop reproducible workloads that consistently generate results over time.
Flyte can easily run on any K8s cluster (on premise, and public and private clouds). Authoring your batch workloads as workflows with strong typing, data abstraction, maintainable container formats, and versioning helps you move faster by massively reducing boilerplate code, reducing scope for runtime errors, and guaranteeing reproducibility of your batch jobs.
Why Union?
While Flyte is powerful at extending K8s for working with big data workloads, the underlying limitations of K8s still play a role - it is expensive to start containers and k8s doesn't have a native way of amortizing container start time across many executions. This is where Union comes in and extends K8s and Flyte by enabling you to reuse containers within the scope of batch executions, massively speeding up execution time while saving resources.
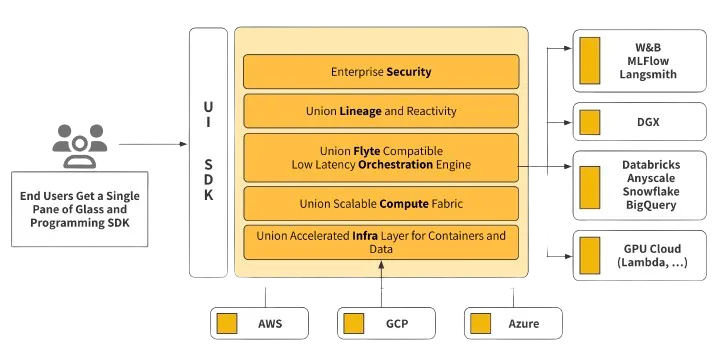
Union builds on Flyte's success, pushing the limits of user capabilities with optimized infrastructure and advanced features:
- Accelerated Datasets: Union provides a way for users to seamlessly cache frequently read datasets on local disks to expedite retrieval
- Reusable K8s Pods: AI Developers can opt into reusing existing K8s Pods instead of paying the penalty of starting new ones for every task execution, saving up to 90% of k8s scheduling overheads.
- First-class Artifact support: Union enables better data sharing between teams through artifact management, versioning, and triggers.
- Multi-cloud & Multi-cluster: Union abstracts management of multiple-clusters from the end-user making it trivial to schedule jobs across multiple clouds & clusters while it takes care of routing executions to the right target clusters based on real time load. This further scales out beyond K8s capabilities (~ 5k nodes) while abstracting that complexity away from end users.
- Live logs & VS Code out of the box: Union sets up a secure tunnel from user’s dataplanes. This enables secure one way communication and low latency access to on demand logs as well as VS Code for interactive debugging without having to setup ingress or other infrastructure pieces.
With these improvements to the core of flyte as well as building out layers on top, Union can drastically reduce the maintenance overhead of running massive compute clusters and dramatically reduce execution time overheads. AI Developers can instantly access a massively distributed computer in the cloud with as low friction as locally developing their workflows.
Putting it all together
With Union, in order to implement the same fraud detection model training above, users can write a workflow like this:
There are a few components in this python script that are straightforward to understand, modify and iterate on:
- `training_workflow`: a python function that defines the flow of data between tasks.
- `prepare_batches`: a python function that takes in the full data directory and prepares batches (perhaps by combining multiple files or splitting larger files).
- `train_iterative`: is a dynamic workflow that iterates over the batches and calls `train_model` iteratively to update the final model.
This can then be invoked by calling:
To run the workflow locally and iterate on code changes and unit tests.
Schedule an execution on the remote cluster by adding `--remote` to the same command:
The command will automatically upload data from the local directory to a remote storage bucket, build a container image, compile the execution graph and launch an execution of this workflow to process the data and generate a model.
Conclusion
Batch workloads often involve large data processing and dependency on other batch workloads. Running these workloads on K8s presents challenges in resource management, multi-tenancy, and data handling abstractions. Solutions like Volcano and Karmada address some issues but fall short in areas like data awareness and job dependencies. Flyte offers a comprehensive solution with high-level DSL, native K8s support, out-of-cluster scheduling, strong typing, data awareness, and versioned immutability. Union builds on Flyte’s foundation, massively speeding up executions on single clusters as well as simplifying scaling out across clusters and clouds.
To learn more about Flyte, join the Slack community.
To learn more about Union, visit Union.ai