The challenge
Today’s AI development lifecycle is marked by multiple teams collaborating to create AI-driven products. At scale, each team is often responsible for developing and maintaining an individual workflow. The inputs and outputs of these workflows form “contracts” between teams so that each team can focus on a core development area. An AI researcher depends on the latest production models to use as benchmarks. ML engineers work to productionize code and models from the research team. Both teams depend on the results of ETL pipelines managed by data engineers.
While this paradigm enables the specialization that is critical for developing complex AI applications, it introduces several key challenges that can negatively impact development velocity:
- Manual interactions between teams. There is often no standardized way for each team to mark a particular output as the “current best” to be consumed by dependent teams. In practice, teams dealing with unstructured data will manually share data and models, which can be difficult to keep track of and introduce scope for error. Teams may instead opt to work together on one monolithic workflow, which adds complexity and creates bottlenecks when downstream teams need to rerun the entire pipeline to test their changes.
- Inaccessibility of data and models. The intermediate inputs and outputs that form each step of the AI lifecycle are often not easily discoverable and accessible. The experimental nature of AI development often creates a massive proliferation of various results, and yet researchers must have access to the latest data inputs and trained models in order to push the frontier of model performance forward. This can be difficult when information about these data and models is buried in object store URIs and Slack messages.
- Opaque or incomplete lineage: Downstream teams often can’t easily view and validate the upstream processes that led to the creation of the inputs of their own workflows. At best, lineage is managed in an external system, and it is often up to the user to write boilerplate code to ensure a given result is tracked. This adds development friction and does not ensure completeness of the lineage graph. Without clear lineage across the AI lifecycle, it can be difficult to debug issues. It is also hard to evaluate which artifacts are important (i.e. dependencies of downstream processes) versus those that can be purged to save on storage costs.
Announcing Artifacts and Reactive Workflows
Artifacts creates a first-class abstraction over the inputs and outputs of tasks and workflows. This important evolution of the Union platform facilitates inter-team collaboration by allowing teams to specify structured “contracts” with other teams. It enables discovery and local accessibility of the data and models created from task and workflow executions. Finally, it automatically captures the relationships between workflows, forming an organizational lineage graph that offers unprecedented observability into every step of a company’s AI development process.

Reactive workflows enable cross-workflow automation by reactively kicking off downstream workflows in response to the completion of upstream workflows. Reactive workflows leverage artifacts as the medium of exchange between workflows, such that when an upstream workflow emits an artifact, an artifact-driven trigger in a downstream workflow passes the artifact to a new downstream workflow execution. Artifacts and reactive workflows can be used together to modularize individual teams’ workflows while automating and providing reproducibility across the overall AI development pipeline.

Smart contracts enable modular workflows
From the perspective of each team, the workflow that generates that team’s work product is of utmost importance, but the innards of the other teams’ workflows are less important. Researchers might focus their time on developing new features that improve model performance and care less about the inner workings of the ETL process that generated the raw data (the domain of data engineers) or the specific steps taken to scale and serve predictions (the domain of ML engineers).
However, it is still necessary to map dependencies and track lineage across each team’s individual workflows. Artifacts facilitates this type of collaboration by enabling each team to define explicit yet flexible dependencies on other teams' workflow outputs and to mark the outputs of their own workflows that are suitable for use by other teams.
Marking workflow outputs for consumption by other teams:
- Artifacts lets you track the outputs of your tasks and workflows as first-class entities. Artifacts are named and versioned such that each execution of an artifact-emitting workflow will generate a new version of the artifact.
- Partitions are key-value pairs associated with each artifact version that enable users to store additional metadata about the artifact. Partitions can be supplied at runtime, allowing this information to be stored dynamically.
- Model Cards are Markdown-formatted text that can be associated with any artifact version to describe the artifact in a human-readable format.

Consuming other teams’ outputs in your workflows:
- Queries allow workflows to be configured to accept only certain artifacts as inputs (i.e. those which match the name and partition query parameters). A query that supplies a particular workflow input forms a “smart default” which can supply the latest version of an artifact that meets the query constraints.
- Reactive workflows enable teams to automate workflow executions by specifying one or more artifacts as the medium of exchange between the two workflows. A triggering workflow emits a new version of an artifact which is then automatically consumed by the reactive workflow.

These features all work together to facilitate greater workflow modularity and team autonomy by making artifacts the “contracts” that define inter-workflow dependencies and automations. Rather than having different teams implement different pieces of a large, monolithic workflow, the AI development process can be separated into distinct workflows within each team’s domain while still providing lineage and reproducibility across the meta-workflow.
Discoverability & accessibility
Artifacts can serve as a versioned data and model registry. Anyone with appropriate organizational permissions can search, inspect, view lineage, and pull down artifacts into their local system for further analysis. This makes it easy for data scientists and other stakeholders to leverage the data, models, and other files that are produced during each step of the AI development lifecycle. It also enables practitioners to quickly understand which workflow executions produced which artifacts, boosting platform observability and debuggability.

Features include:
- Artifacts search: This page shows all artifacts, their partitions, the creation timestamp, and the tasks and/or workflows that produced them. This page currently supports searching by artifact name or partition, with additional search functionality coming soon.
- Artifact overview: Once an artifact is selected, users can click through to the specific task and/or workflow execution that created the artifact. This page also contains metadata such as the artifact version, partitions, and a copyable code snippet to pull the artifact down locally.
- Artifact object: This tab shows the artifact's raw underlying definition. For offloaded data, models, and other objects, it will show the underlying location in an object store that this artifact points to.
- Artifact card: This tab displays the Markdown-based model card or dataset card that can optionally be associated with the artifact. Model cards improve usability and transparency by allowing teams to include relevant metrics such as model performance data in a human-readable format.
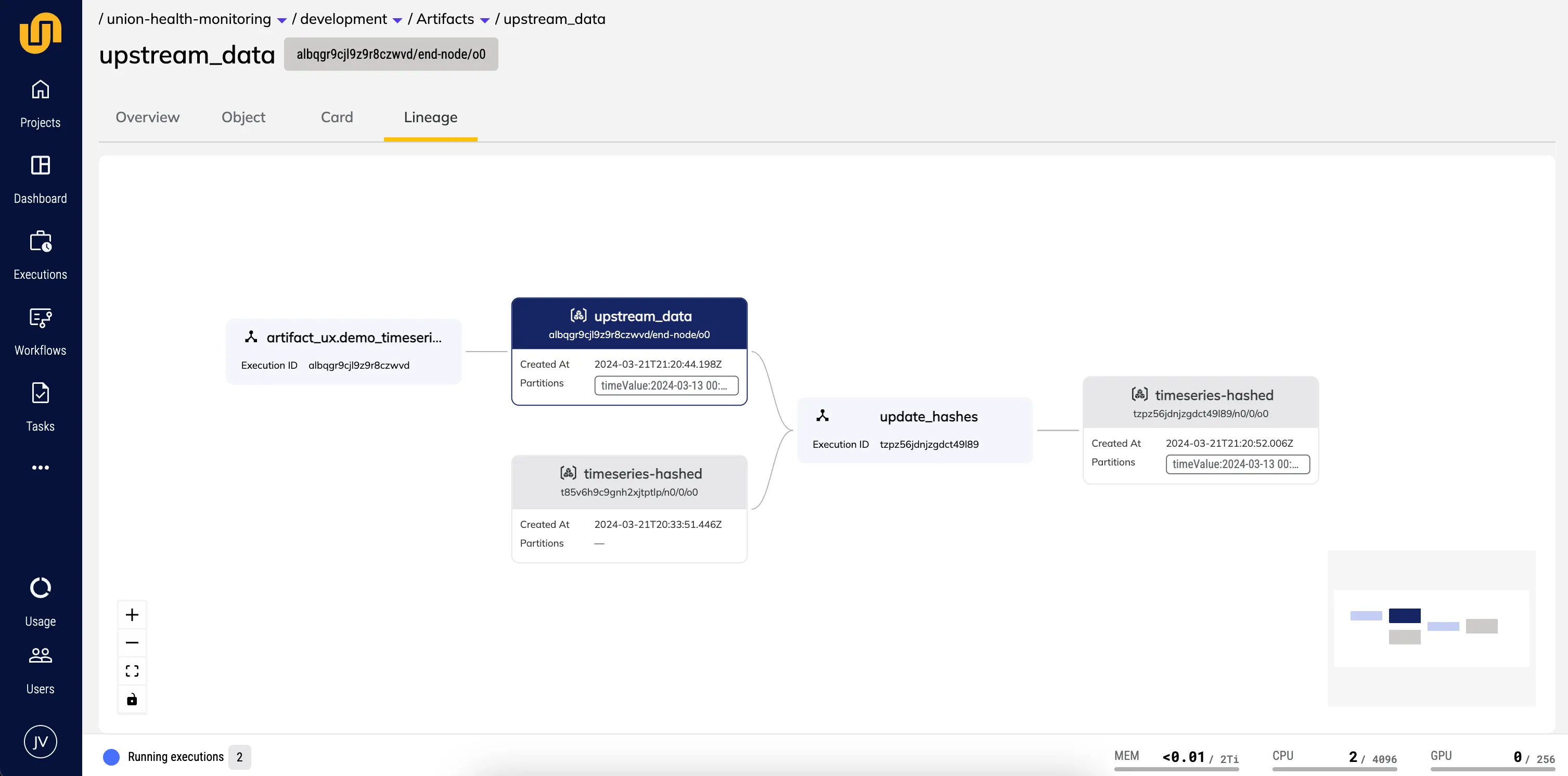
- Artifact lineage: This tab displays the artifact that has been selected, any task or workflow executions that produced or consumed it, and all artifacts which in turn have been produced or consumed by those executions. In other words, it displays one “hop” on the global lineage graph whose nodes are artifacts and whose edges are workflow executions.
End-to-end lineage
Adopting artifacts allows each team to standardize the data and model “contracts” they have with other teams. This in turn enables each team to develop their internal workflows independently, boosting development velocity while maintaining traceability across the meta-workflow that stretches across all teams. This ability to introspect backwards in time across the organizational development process is provided by artifacts lineage.

There are several foundational characteristics of the Flyte and Union development system that enable automated, actionable, and exhaustive lineage to be tracked across the entire organization:
- Automatic versioning. Every entity in the system—tasks, workflows, launch plans, artifacts, and workflow executions—is versioned and immutable. This enables the artifacts system to automatically link and store these precise relationships between specific workflow executions and the versioned artifacts they consume or produce.
- Strong typing. All inputs and outputs of tasks and workflows are strongly typed. This means that the system can make smart decisions about which inputs and outputs are compatible with each workload, as well as automatically categorize artifacts into data, model, and other file types.
- Automatic data offloading. Because of strong typing, the system automatically offloads all data and models to an object store. Artifacts form an index over these offloaded files, such that the metadata contained in the artifact is always linked to an immutable ground truth file sitting in an object store. It is therefore possible to store artifacts of arbitrary size and type, as well as directly supply a specific artifact to a workflow at runtime.
Building on these features, artifact lineage automatically captures the relationships between specific workflow executions and the artifacts they produce or consume. Users can then navigate to any artifact in the UI and view all of the linkages that the artifact in question shares with other workflows and artifacts. This offers an unprecedented ability for users to time travel arbitrarily far backwards and evaluate any aspect of the “uber dag” or meta-workflow.
What makes Union artifacts unique
Union, which is based on Flyte, stores strongly typed inputs and outputs and abstracts the data flow from users within the scope of a workflow. Immutable entities and automatic versioning make it easy to understand lineage within a single workflow. Artifacts builds on this foundation by tracking cross-workflow dependencies and elevating these inputs and outputs to first-class entities, enabling new development paradigms such as modular workflows, smart defaults for workflow inputs via partitions, and event-based workflow reactivity via triggers.
There are many potential choices in the market for tracking the data and models produced within an AI organization, and we plan on integrating with a few of them. However, none of these tools are tightly integrated with both compute and orchestration, and therefore cannot offer the same guarantees around automation, exhaustiveness, and actionability. Data version control systems like DVC, experiment tracking tools like MLFlow, and even purpose-built lineage services such as OpenLineage, require users to manage the artifact offloading process (and are therefore not automated), are opt-in (and are therefore less exhaustive), and are separated from the compute platform (and are therefore less actionable and harder to integrate).
Because Union artifacts are deeply integrated into an orchestration and compute platform, we are able to build a reproducibility solution that is unmatched along these dimensions:
- Automation: When a workflow emits an artifact consumed by another workflow, the lineage is automatically tracked without requiring users to write boilerplate code. This is because Union already offloads typed inputs and outputs to an object store, and artifacts is an index over all of these offloaded assets. Rather than requiring users to manually map dependencies between artifacts (as is the case with other orchestrators), Union simply tracks the dependencies between workflows, which is much simpler to understand and adopt.
- Exhaustiveness: By indexing over the offloaded, strongly-typed inputs and outputs of versioned tasks and workflows, artifacts (which are also versioned) provide a truly end-to-end view of all transformations that take place along each step of the AI development lifecycle. It is therefore possible to introspect across the entire lineage graph—from a given model’s prediction all the way back to the precursor datasets used to train it. Furthermore, by linking versioned artifacts to versioned executions of versioned workflows, Union artifacts maintains the highest-resolution historical “picture” of what happened.
- Actionability: Because workflow executions in Union are containerized, versioned, and infrastructure-aware, it is always possible to rerun an execution. Artifacts explicitly catalogs the linkages between these executions, their outputs, and those outputs’ consumption in other workflow executions. This enables teams to not only identify discrepancies but also correct them by adapting and/or rerunning the specific execution that was problematic. Additionally, any artifact of the correct type can be passed to an ad-hoc workflow execution in the launch form. This allows users to work directly with artifacts rather than merely tracking their existence in an external service.
Artifacts and Reactive Workflows Example
Emitting and Consuming Artifacts
An upstream team can append partitions (key-value pairs) to an artifact emitted by a task or workflow, and a downstream team can specify an artifact query as an input to their workflow. For example, suppose a product development team has a workflow that emits a model, but only certain versions of that model are suitable for consumption by other teams. They can declare an artifact, blessed_model, containing the partition key “blessed”:
Note: Code used in this example can be found here.
A workflow product_development_wf can be configured to emit this blessed_model artifact. Note that the partition keys are defined statically at registration time and the values are supplied at runtime. The below workflow takes the string blessed_or_not as an input and injects it as a partition value for the key blessed:
Users can also define a Model Card (a simple Markdown file) and append it to an artifact using the ModelCard syntax as shown.
A downstream team focused on model operations may always want to work with the latest model available from the product development team. They only want to work with “blessed” models (i.e. models which the upstream team deems fit for purpose), so they can define a query which will return the latest version of the blessed_model artifact that has a “blessed” partition value of “true”:
This data_query can then be set as the input for the operations team’s workflow, which itself emits an artifact called prediction:
This loose coupling between different workflows enables the product development team and the operations team to iterate independently on the latest available artifact inputs.
The artifact query in the operations team’s workflow serves as a “smart default” which will pick up the latest suitable input model. This is done without requiring any code changes and while preserving lineage across executions. For example, navigating to the ops_wf in the UI and clicking “relaunch” now shows the latest version of the input artifact blessed_trigger that meets the query parameters. The system automatically identifies this artifact but can be overridden by clicking “Override” and supplying a compatible input value.
Reactive Workflows
Finally, suppose the operations team is happy with a particular workflow and wants to create an automation such that every time the product development team produces a new model, that particular workflow runs automatically. This is possible with artifact event triggers, an enhancement of launch plans that enables users to trigger workflow executions on artifact creation events.
In order to create an artifact event trigger in this example, define a launch plan connected to ops_wf with an attached trigger:
After registering the code, users can activate the trigger_ops_wf_lp launch plan by navigating to the Union UI, clicking the “More options” icon, selecting “Add active launch plan”, selecting the latest version from the dropdown list, and clicking “Update”.

Once the launch plan containing the artifact event trigger is active, the ops_wf workflow will automatically execute whenever a new version of the blessed_model artifact is created.
Artifacts Lineage
A user can navigate to a version of the blessed_model artifact, click the “Lineage” tab, and visualize the specific workflow execution that created this artifact, any downstream workflows that consumed it, and any other artifacts that were produced by the consuming workflow:

Clicking on either the producing workflow or the consuming workflow will link out to the execution detail page of the specific workload (workflow or task execution) that consumed or produced blessed_model. Clicking on any other artifact in the view will switch the scope to the other artifact, enabling the user to traverse the entire meta-workflow.
To further illustrate the end-to-end nature of artifact lineage, consider a workflow find_next_prime which takes an artifact called largest_baillie_wagstaff (which is simply a prime integer) as an input, computes the next prime integer, and emits it as another version of the artifact largest_baillie_wagstaff. The workflow is set up with an artifact trigger that calls itself whenever a new version of the artifact is created. The meta-workflow therefore continues to compute the next prime number forever. Artifacts Lineage makes it possible to traverse through the entire meta-workflow iteratively.
Note: Code used in this example can be found here.
Artifacts and reactive workflows are key components of the end-to-end AI development platform we are building at Union, and we appreciate feedback! To learn more about Union or request a demo, contact us here.