Still orchestrating AI/ML workloads with tools built for ETL?
Union.ai, the managed Flyte platform, is the production runtime for the AI era. Orchestrate compute, models, and data on your own secure cloud. No DAGs needed.
Old eras of orchestration don’t work for AI
Using a data orchestrator instead of an AI runtime is like using a paper map instead of GPS.
Orchestration has evolved through 3 distinct eras:
- Data Era: move data from A to B
- ML Era: run workloads on different compute resources
- AI & Agentic Era: dynamically determine workflow paths at runtime
AI is non-deterministic, so it needs to branch, handle errors, and provision resources dynamically at runtime.
Static DAGs aren’t built for this reality.

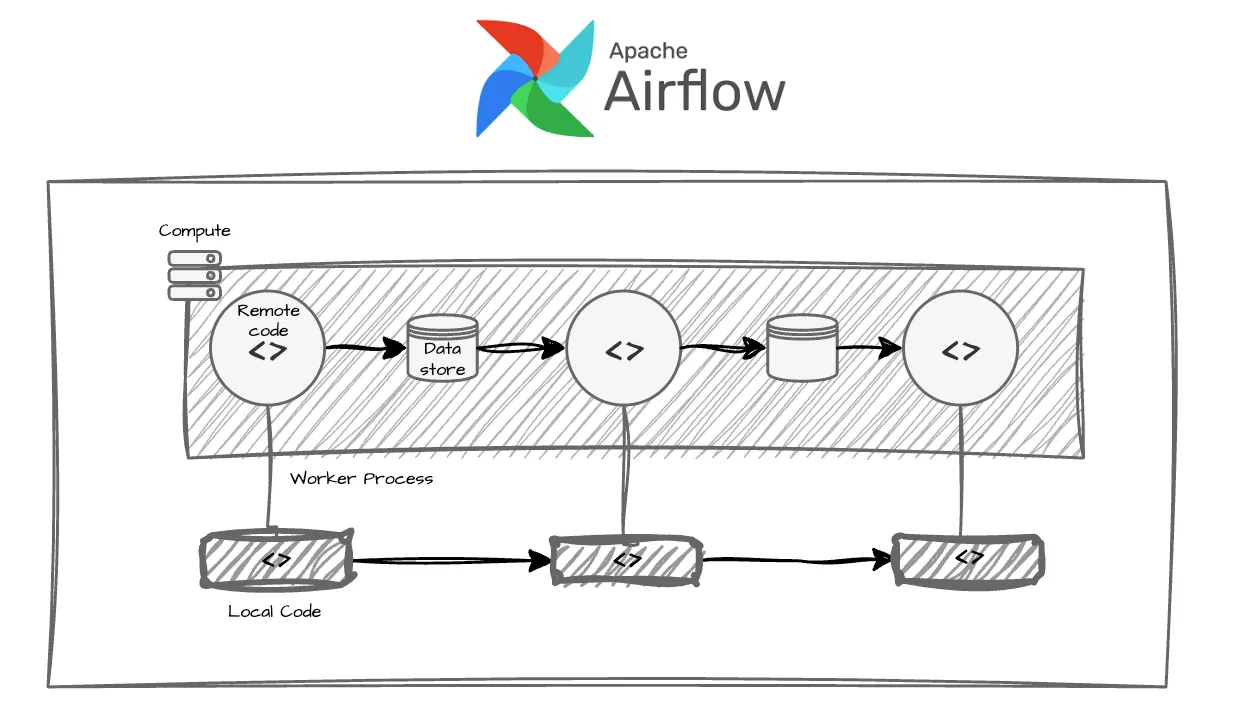
Airflow was built for data, not AI
Airflow was designed to move structured data between systems on a schedule. That worked when every task shared one environment and one compute profile. But AI workloads broke that assumption:
- One-size-fits-all compute. Airflow runs tasks in a monolithic environment. When your preprocessing needs CPUs and your training needs GPUs, you're either overprovisioning everything or bolting on workarounds.
- No native data handoff. Passing data between tasks means writing custom serialization, storage logic, and glue code — a primary source of bugs and version drift.
- Static DAGs, brittle pipelines. The execution graph is defined before runtime. When an LLM call needs to branch, retry with different parameters, or spin up new tasks based on intermediate results, Airflow has no answer.
- Lineage is an afterthought. Tracking which data produced which model requires external tooling. At scale, this becomes a compliance and debugging nightmare.
If you’re running simple data workloads, these compromises can be totally fine. But if you’re orchestrating AI or agentic projects, you’ll need an AI runtime.
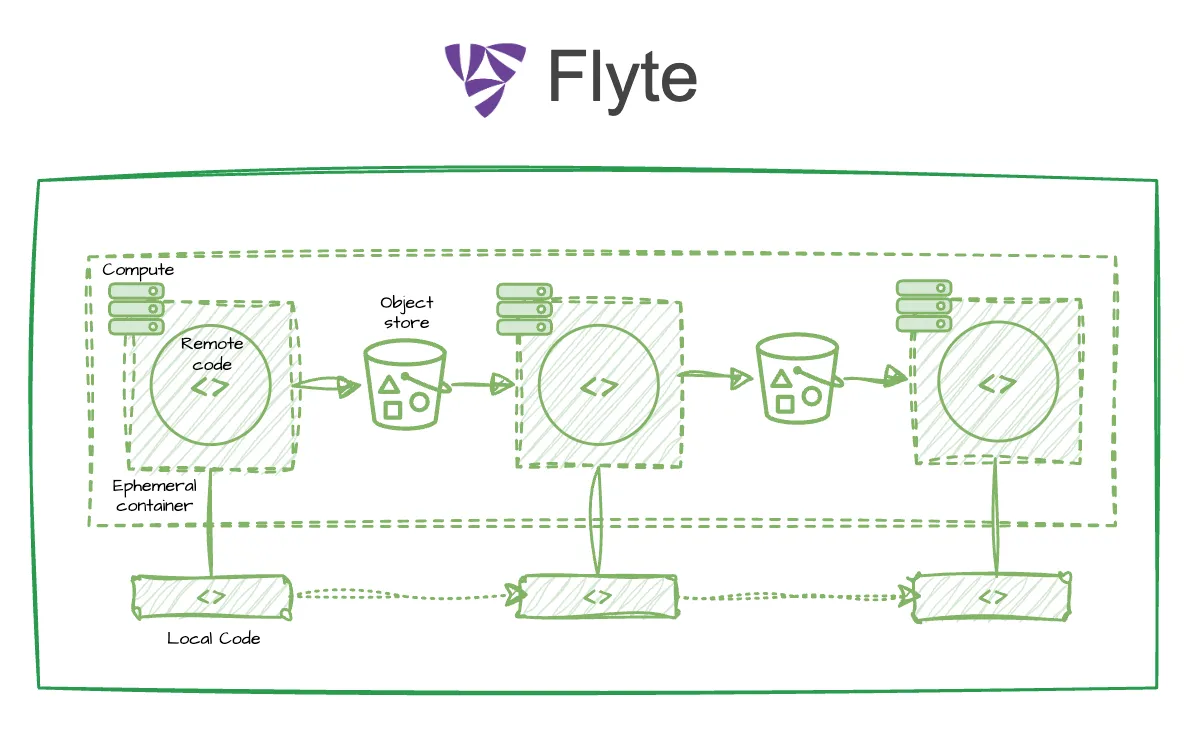
Union.ai is AI-native orchestration
Union.ai, the enterprise Flyte platform, is expressly designed for AI engineers. Teams can build workflows that are:
- Self-healing, so pipelines that fail autonomously recover and continue
- Dynamic, so your AI systems and agents can make decisions on the fly at runtime
- Authored in pure Python, so you can easily go from local dev to production in your cloud
- Compute-aware, operating in your cloud and auto-scaling to optimize usage
- Scalable and efficient, handling large task fanout and parallelism with ease
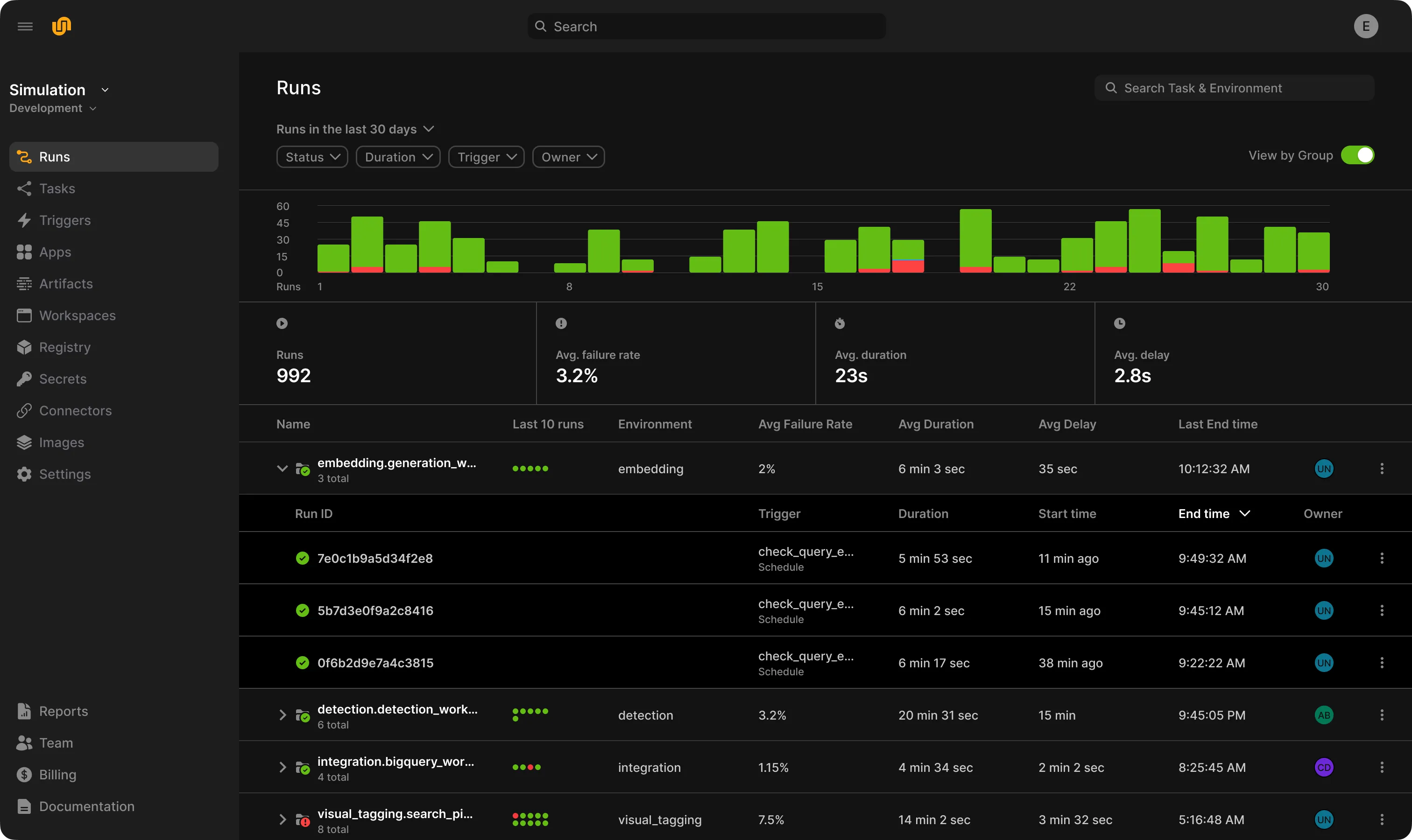
Union.ai is built for production
The platform deploys to your secure cloud
- Enhanced scale and performance, with significantly improved actions/run, concurrency, and task startup time
- End-to-end AI lifecycle support, including orchestration, training and fine-tuning, and inference
- Developer-loved UI, for faster, easier development cycles
- Observability, including for data lineage, resource usage, failure logs, etc.
- Portability to open-source, for teams looking to avoid lock-in
Teams report that Union.ai accelerates them from prototype to production, cutting iteration cycle time in half.
The Union.ai team offers high-touch support to ensure users are successful.
Flyte 2 OSS: Open-source AI runtime
Flyte 2 OSS is the most powerful open-source AI runtime, bringing Flyte’s core data model, scalability, and reliability to DIY teams. While it lacks some enterprise capabilities of Union.ai, it remains the most capable open-source AI runtime available. It’s trusted by teams worldwide with 80M+ downloads and growing.
Trusted by 4,000+ companies
Accelerate engineers with tools to make their lives easier.





Let’s chat
What’s a quick chat compared to the hours a week you could save on maintaining infrastructure?