The bottleneck wasn’t the model, it was the platform
Modern AI workloads have a shape Python wasn’t built for: tens of thousands of short-lived tasks, multi-gigabyte artifacts shuttled across regions, and orchestrator clients that need to hold thousands of in-flight gRPC streams open without blinking. The Python implementation of Flyte 1.0 was excellent at expressing those workloads, but the runtime carrying them paid for every concurrent task with GIL contention, for every blob download with single-threaded fsspec, and for every workflow fan-out with a controller event loop that serialized state updates through one thread.
Flyte 2.0 is our answer: keep Python as the authoring surface because that’s what AI/ML engineers want and rewrite the performance-critical machinery underneath in Rust. The goal isn’t a Rust rewrite of Flyte. The goal is a Python SDK that feels native, sitting on top of a Rust core that can saturate a 10 Gbps NIC, drive 10,000 concurrent tasks from a single process, and survive a parent-process crash without losing work.
This post walks through every layer where Rust powers Flyte 2.0 today: the SDK, reusable-container runtime, data plane, controller, IDL layer and storage substrate. For each, we’ll discuss the bottlenecks we encountered, the systems we built or adopted, and the impact those decisions had on the end-user experience.
Why Rust, and why now?
We could have continued optimizing Python, but the tradeoffs no longer made sense. Three factors ultimately pushed us toward Rust:
- Beautiful interop with Python via PyO3. We didn’t want to rewrite Flyte in Rust. We wanted to keep Python’s ergonomics for AI/ML practitioners while accelerating performance-critical paths. PyO3’s async support (pyo3-async-runtimes) lets us bridge Rust’s Tokio runtime with Python’s asyncio. In an industry that moves as quickly as AI/ML, the tooling and toolchain of its user base can change just as rapidly, so building core components in a language with a strong foreign function interface (FFI) was a conservative bet.
- A production-grade ecosystem. Tokio for async, Prost for protobuf, Serde for serialization and obstore for object storage. The Rust crate ecosystem had matured to the point where we could build production systems without reinventing core primitives.
- It’s Rust. Not because it was the language of the moment, but because the workload profile demanded stronger runtime guarantees than Python could comfortably provide. Flyte’s core systems are long-running, highly concurrent, and heavily dependent on networking and IO. At that scale, we wanted strict isolation between the Python runtime and the orchestration core itself. In Python, a single CPU-heavy workload can starve the event loop and stall unrelated IO, making `asyncio` difficult to rely on for latency-sensitive infrastructure. Rust gave us predictable concurrency, memory safety without garbage-collector pauses, strong compile-time guarantees, and the ability to build high-throughput systems that remain responsive even under load.
Where Rust shows up in Flyte 2.0
Rust isn’t one component in Flyte 2.0. It’s a layer that spans the SDK, the task runtime, the data path and the storage substrate. Seven places it shows up today:
- Reusable containers: Many concurrent tasks running inside a single, long-lived container, with the scheduling and IO handled in Rust outside the GIL.
- Blob-store data transfer: The default path for S3, GCS, Azure and ABFS in the Python SDK now goes through a Rust object-store engine.
- Remote controller: The SDK component that submits actions, watches their status, and tracks the replay log is being rewritten in Rust to remove the single-threaded asyncio bottleneck.
- Cross-language IDL: The Flyte wire format has a first-class Rust binding so the Rust controller (and future non-Python SDKs) share one source of truth with the Python SDK.
- Sandboxing engine: Two Rust-backed sandboxes: a lightweight workflow sandbox (Monty) for LLM-generated Python, and unionai-sandbox, a process-isolation core with an optional VM-level hook for arbitrary user code.
- Container cold-boot: A Rust snapshotter behind streaming container images that cuts the time between pod scheduling and first task execution.
- Devbox storage: The default object store in local dev and the devbox environment is an S3-compatible service implemented in Rust, so users get the same API surface as production without a real bucket.

The Rust layer, path by path
Reusable containers
The majority of Flyte tasks run in containers, which buys portability, reproducibility, and isolation and costs you image pulls, CNI setup and per-task startup overhead. In large workflows that overhead adds up to hours. Union’s 1.0 answer was a proprietary feature called actors that reused a pod for many tasks. It worked, but each pod could only run one task at a time.
In v2, this is rebuilt as a first-class capability. A user enables it by adding a `ReusePolicy` to a task environment:
Under the hood, the pod runs two cooperating Rust processes. One talks upstream to the Flyte engine over gRPC and owns the lifecycle of the Python worker; the other is loaded into the Python interpreter as a native extension and drives task execution on a multi-threaded Tokio runtime via PyO3. The Python code is still Python, while the scheduling, the IO and the bridge to the platform all run on Rust threads outside the GIL.
The v1 actor system made pods reusable; v2 makes them concurrent. We can drive multiple tasks at once against a single Python process because the v2 SDK is async by default, while Rust handles the parallel work underneath. Flyte’s code-bundle system pairs naturally with this: the container is pinned to one set of Python dependencies, so the Rust runtime can front-load module initialization once and then serve many tasks with no warm-up cost.
Blob-store data acceleration
The Python `fsspec` library is widely used and well-loved. It gives you a consistent interface, and a whole ecosystem of data-science libraries (pandas, dask, polars) respects it. The trouble is that cloud-specific implementations like `s3fs` are GIL-bound and hard to push beyond a small fraction of available bandwidth without serious tuning. On a 10 Gbps machine, downloading a 5 GB file with a stock `s3fs` setup took roughly 50 seconds.
Rather than try to optimize what would ultimately remain GIL-bound, the SDK now routes S3, GCS, Azure Blob and ABFS transfers through a Rust object-store engine reached over PyO3 and backed by Tokio. On top of that, we layer a parallel reader with tunable chunk size (default 16 MiB) and concurrency (default 32).
Benchmarks against a 5 GB single file and a 1000-file × 5 MB directory:
Testing was done on a 10 Gbps machine with 8 CPUs and effectively no competing load. Both `s5cmd` and the Flyte v2 reader were configured with 32 connections, so the parallelism is doing the heavy lifting. Initial results put the Rust path marginally ahead of `s5cmd` and roughly 10x faster than stock `s3fs`. We expect free-threaded Python 3.14 to close some of that gap on the Python side, but the Rust path will continue to outpace it for the same reason it does today: no GIL on the IO loop.
Remote controller
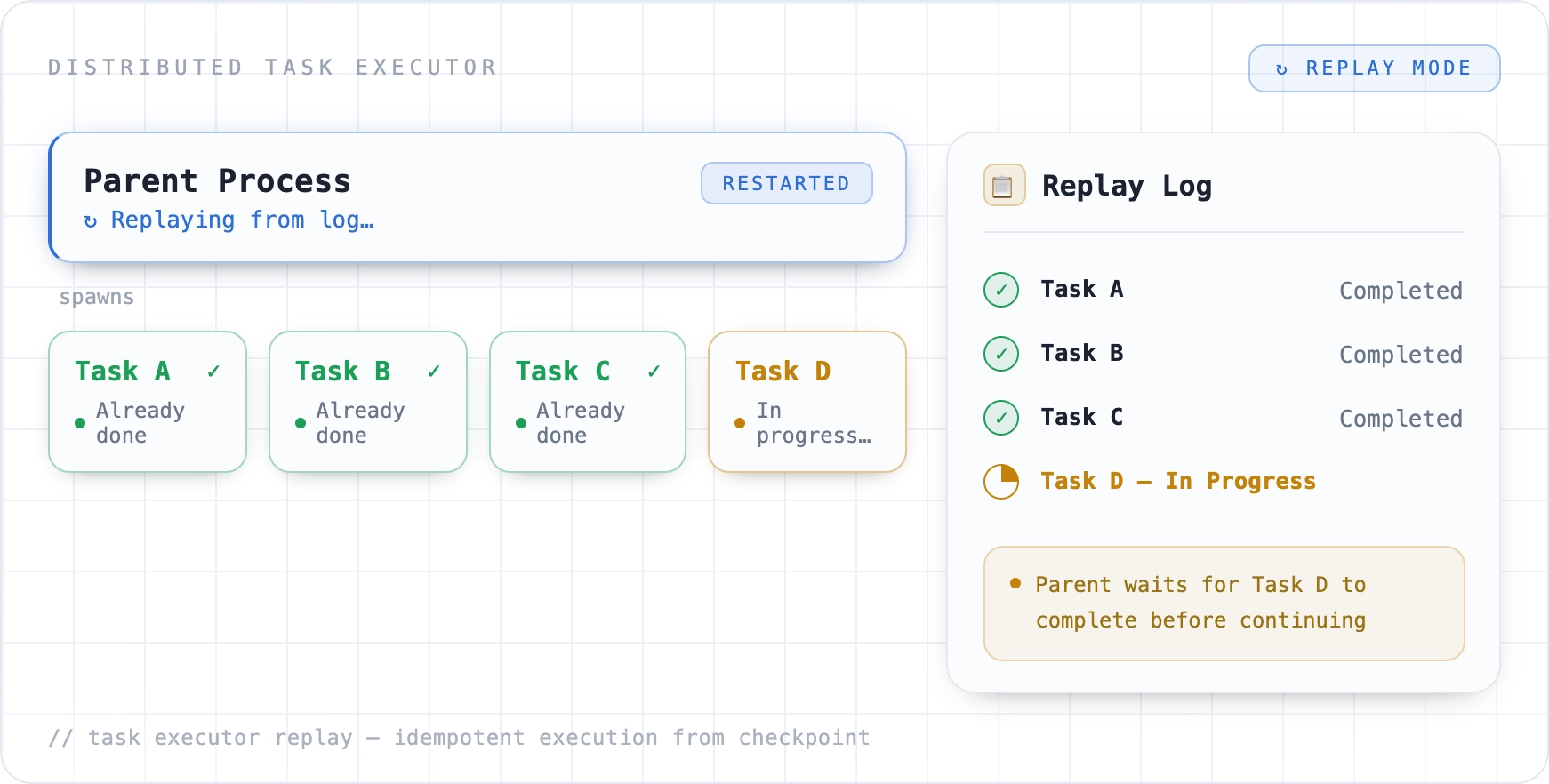
The controller is the component inside the SDK that sits between the user’s Python program and the Flyte backend. It enqueues actions, opens long-lived gRPC watch streams to receive status updates, caches sub-actions in memory, and handles cancellation. It also owns the replay log: the data structure that lets a workflow survive a parent-process crash by replaying only the in-flight work, not the completed work (more on this in the next section).
The Python implementation runs everything on a single-threaded `asyncio` event loop under the GIL. At moderate scale, this works well enough. But once a run fans out into thousands of concurrent sub-actions, each producing a continuous stream of gRPC status updates, the controller itself becomes both a throughput and memory bottleneck. Every gRPC message must be deserialized into a Python object, and every watch stream competes for the same event loop thread.
This becomes especially noticeable at fractional CPU allocations. A Python event loop constrained to `250m` CPU still has to serialize every gRPC message and state transition through a single thread, so it quickly falls behind under real fan-out. In contrast, the Rust controller runs on Tokio’s multi-threaded runtime outside the GIL. Tokio worker threads sleep while waiting on IO and only consume CPU when actual work arrives, allowing the same workload to comfortably run in a `250m` container that previously required a dedicated core.
Architecturally, the Rust controller preserves the same execution model: the worker pool, per-parent informer cache and completion-event flow all remain unchanged. The difference is in the runtime. The implementation is written in Rust and exposed through an API-compatible async interface to Python using PyO3 and `pyo3-async-runtimes`, so existing SDK callers require no changes.
The result is true parallelism across watch streams, lower per-action memory and CPU overhead, and the elimination of GIL contention while processing status updates. The Rust controller is opt-in today while we continue to harden it in production.
Replay log: crashing safely is a feature
Worth calling out on its own: the replay log is what lets a Flyte 2.0 driver process die and come back without losing work. Only in-progress tasks are rerun and completed ones are skipped. That guarantee depends on concurrent network access and consistent tracking of multiple in-flight runs, exactly the kind of correctness-critical, concurrency-heavy code where Rust’s type system and ownership model pay for themselves.
A shared wire format across languages
All of the above depends on a single source of truth for the Flyte API. We generate first-class Rust types and gRPC clients directly from the Flyte protobufs, alongside the existing Python and Go bindings. That’s what makes the Rust controller possible without re-implementing the wire format by hand, and what makes it cheap to stand up SDKs in other languages on top of the same engine.
Sandboxing engine
Flyte 2.0 needs to run untrusted or LLM-generated code safely, and it needs to do so at two very different scales. Rust plays a key role in both.
The first is the Monty (Rust-based) workflow sandbox: an in-process runtime for the small, pure-Python control-flow snippets emitted by agents and code-mode tasks. Monty parses and executes that code directly, with no imports, IO, filesystem access, or subprocesses, and with microsecond startup latency. When sandboxed code calls an external task, Monty pauses and a bridge layer dispatches the call, either directly in the outer Python process or as a remote durable call through the Flyte controller, then resumes execution with the result. This powers `@env.sandbox.orchestrator` and `flyte.sandbox.orchestrator_from_str()`, allowing LLM-generated routing logic to execute with microsecond startup latency inside a task.
The second is `unionai-sandbox`: a separate Rust core designed to isolate arbitrary user code in its own process, solving the same class of problem tackled by systems like Claude Code and Codex when they execute model-generated commands. On Linux, it automatically selects the strongest available backend: either `bubblewrap` or a direct `userns` path. Both layer kernel namespaces, dropped capabilities, Landlock filesystem rules, and for the `userns` path, a seccomp BPF deny-list. On macOS, it uses `sandbox-exec`. Everything security-critical lives in the Rust core: it spawns each process, sets up the namespaces and cgroups, installs the seccomp and Landlock rules, and marshals IO across the boundary. This is code where a single mistake means a sandbox escape, so Rust's memory safety and freedom from GC pauses matter here for correctness as much as they do for speed elsewhere; Python only drives it through a thin PyO3 binding.
Network posture is configurable per call: blocked by default, optionally fully open, or restricted through an HTTPS proxy allow-list for tools like `pip` and `curl`. When stronger isolation is required, the same session abstraction can optionally escalate to VM-level isolation, say via `runtimeClassName: gvisor` on the sandbox pod, without requiring application code changes.
Inside a Flyte task, you wrap the work in a sandbox session. Network is blocked by default; here we open a narrow allow-list so the isolated code can reach PyPI:
`unionai-sandbox` is still under active development and is not yet generally available.
Both sandboxes share the same design philosophy: keep the Python interface minimal and move the components that must be fast, correct and highly concurrent, including process spawning, namespace setup, syscall filtering, and IO marshaling, into Rust.
Container cold-boot
Reusable environments and sandbox pods only help if the underlying container starts quickly. Standard Docker pulls take 6–10 minutes for 5–20 GB images. Flyte 2.0 leans on streaming container images backed by a Rust lazy-loading snapshotter, so pods begin executing before the full image has been pulled, bringing a 10 GB image down to under 2 seconds, a >94% reduction in boot time and 239x faster than a standard pull. We've written about that work separately; the short version is that the snapshotter is another place where Rust’s concurrency model and predictable latency directly translate into shorter time-to-first-task for users.
Devbox storage
One final place Rust shows up is the local devbox storage backend. The default object store is RustFS, an open-source, S3-compatible object store written in Rust that ships as a single static binary and starts in milliseconds. It pairs naturally with the rest of the stack: the same Rust object-store engine that drives S3, GCS and Azure transfers in production points at RustFS in the devbox, so a local run exercises the same Rust data path end to end, a Rust client talking to a Rust server, instead of a separate mock with its own quirks.
The impact is dev/prod parity at zero setup cost. Developers get the exact S3 API their production code uses without cloud credentials, a real bucket or an emulator like MinIO, and without the behavioral drift those mocks introduce. Code that reads and writes blobs behaves the same on a laptop as it does against a production bucket. For production deployments, we continue to recommend AWS S3, GCS, Azure Blob Storage or another production-grade object storage system.
What this adds up to
From the user’s point of view, Flyte 2.0 still looks like Python: you write tasks, you compose them, you run them. Underneath, the hot paths have moved out of Python: object-store IO, reusable-container execution, controller fan-out and devbox storage are all Rust now.
We didn’t pick Rust because it was fashionable. We picked it because at the scales AI workloads are now asking for with thousands of concurrent tasks, multi-gigabyte artifacts, sub-second control-plane latency pushed Python’s runtime model past its comfort zone. At that scale, the GIL stopped being a minor inconvenience and became a core architectural constraint. PyO3 gave us a way to move beyond those limits without forcing users to give up Python. And that tradeoff only becomes more valuable as workloads continue to grow.
Union will continue to push Flyte’s core forward in Rust for performance, for correctness and for the doors it opens to new SDKs.
The easiest way to explore the Union.ai platform is to start with Devbox: union.ai/get-devbox