Code mode analytics agent
Code available here.
This tutorial builds a “chat with live market data” app on Flyte’s native AI stack. You ask a question in the browser, and the app launches a Flyte run to answer it. Inside that run, flyte.ai.agents.Agent running in code mode has Claude write one small Python program, the program executes in Flyte’s
Monty sandbox, and the only things it can touch are the tools you registered. It fetches daily stock prices from a Yahoo Finance server plugged in over MCP, and hands them to a DuckDB query — a durable Flyte task, so every query the model writes shows up as a tracked, retryable child task you can open in the UI. The cheap tools that render metrics, charts, and tables run in-process. And the web layer is not hand-built either: flyte.ai.chat.AgentChatAppEnvironment provides the chat UI, the streaming, and the run-per-question wiring in one declaration.
Why code mode
Most tool-using agents call tools one at a time. The model asks for a tool, the result comes back, it reasons, it asks for the next one. For anything multi-step that turns into a lot of round-trips, and the orchestration logic lives in a loop you have to babysit.
In code mode, the model writes a single program that orchestrates the tools instead, with real control flow and composition. A question like “compare three tickers, indexed to 100 at the start, then rank them by volatility” becomes one script that does a few fetches and runs one query. It doesn’t glue togther a dozen tools with model turns.
The code runs inside Monty, a restricted interpreter with no imports, no filesystem access, no network access, and near-instant startup. It can only use the tools you explicitly make available to the sandbox. That means the model isn’t running arbitrary Python with unrestricted access. It can only work within the boundaries you’ve defined.
What runs where
The example splits work by how expensive and how worth-tracking each piece is.
| Piece | Where it runs | Why |
|---|---|---|
| the chat app | a CPU app pod | The native chat UI. Streams progress and launches one analysis run per question. |
analyze |
a Flyte task (the run) | Starts a report, runs the agent loop, returns the report blocks and a summary. |
yf_get_historical_stock_prices |
the MCP server subprocess | Live price fetch: the agent’s only path to the network. Loaded over MCP; the model calls it from its code like any other function. |
query(sql, series) |
a durable child task | Parses the fetched price JSON into a prices table and runs read-only DuckDB SQL. Real work worth tracking, retrying, and caching. Dispatched from inside the sandbox. |
create_metric, create_chart, create_table, calculate_statistics |
in-process in analyze |
Microseconds of pure Python. Making them tasks would add a round-trip for nothing. |
| the model’s code | the Monty sandbox | Untrusted LLM code, confined to calling the tools above. |
The heavy tool: a durable query
The agent fetches prices at runtime from a Yahoo Finance MCP server (covered below). Each fetch returns one ticker’s closing prices as a JSON string; query parses those into a prices(ticker, date, close) table and runs read-only DuckDB SQL against it, coercing dates to ISO strings on the way out. The reshape lives in the task, not the sandbox, because the sandbox has no json or pandas:
async def run_sql(sql: str, series: dict[str, str]) -> list:
"""Parse raw Yahoo Finance price JSON per ticker, then run a read-only query.
Args:
sql: A DuckDB SELECT statement against the table `prices`
(columns: ticker, date, close). Aggregate in SQL where you can.
series: Maps ticker symbol -> the JSON string returned by
yf_get_historical_stock_prices for it (closing prices keyed by
epoch-millisecond timestamp).
Returns:
A list of row dicts (one per result row), with dates as ISO strings.
"""
import duckdb
import pandas as pd
# Parse each ticker's raw MCP payload into rows and stack them into one table.
# This reshape needs json + pandas, which the Monty sandbox lacks — so it runs
# here, in the durable task, not in the model's generated code.
frames = []
for ticker, raw in series.items():
data = _json.loads(raw) if raw else {}
if not data:
continue
frame = pd.DataFrame({"ts": list(data.keys()), "close": list(data.values())})
# The MCP keys its close prices by timestamp, but the format varies by
# pandas version inside the server: ISO date strings ("2025-07-03") or
# epoch-millisecond integers. Detect which and parse accordingly.
ts = frame["ts"].astype(str)
if ts.str.fullmatch(r"\d+").all():
frame["date"] = pd.to_datetime(ts.astype("int64"), unit="ms").dt.date
else:
frame["date"] = pd.to_datetime(ts).dt.date
frame["ticker"] = ticker
frames.append(frame[["ticker", "date", "close"]])
prices = (
pd.concat(frames, ignore_index=True)
if frames
else pd.DataFrame(columns=["ticker", "date", "close"])
)
# Lock the engine down: no reading or writing files, no extensions, no network.
con = duckdb.connect(config={"enable_external_access": "false"})
_ensure_read_only(con, sql)
con.register("prices", prices)
rel = con.execute(sql)
columns = [d[0] for d in rel.description]
return [{c: _jsonable(v) for c, v in zip(columns, row)} for row in rel.fetchall()]
The model does the analytics in SQL. It uses window functions for moving averages, LAG for daily returns, STDDEV for volatility, rather than looping in Python.
Tools are a safety boundary
Restricting the model to a fixed set of tools is one layer of safety. The tool itself is a second. Because the model can only ever call the tools you register, narrowing what each tool accepts shrinks the whole system’s surface area.
query is a good example. The sandbox confines the orchestration code, but the SQL string still runs against real DuckDB, which can read and write local files, install extensions, and reach the network. So the tool adds two of DuckDB’s own controls: it opens the connection with external access disabled (no files, no extensions, no network), and it uses DuckDB’s parser to classify the statement and reject anything that is not a single read-only SELECT. A DELETE or DROP is rejected as a non-SELECT; a read_csv('/etc/passwd') parses as a SELECT but is stopped by the disabled external access.
# The tool is a safety boundary. The model can only call the tools you register, so
# narrowing what a tool accepts shrinks the blast radius. `query` allows a single
# read-only SELECT and nothing else. DuckDB's own parser classifies the statement, so
# there is no brittle keyword matching to trip over identifiers or string literals.
def _ensure_read_only(con, sql: str) -> None:
import duckdb
statements = con.extract_statements(sql)
if len(statements) != 1 or statements[0].type != duckdb.StatementType.SELECT:
raise ValueError("Only a single read-only SELECT query is allowed.")
Letting DuckDB parse the SQL beats hand-matching keywords, which trips over identifiers and string literals. A rejected query comes back as an error that the agent loop feeds back to the model, so it rewrites the query as a proper SELECT. The same idea applies to any tool you add: accept the narrowest input that does the job.
The durable environment
query becomes durable by living in a flyte.TaskEnvironment. The environment carries the image (DuckDB, pandas, the Anthropic SDK, the Monty sandbox package, the MCP client, and the Yahoo Finance MCP server) and the Anthropic API key as a flyte.Secret. The MCP server reads public market data, so it needs no credentials and the key is the only secret:
ANTHROPIC_SECRET = flyte.Secret(key="anthropic_api_key", as_env_var="ANTHROPIC_API_KEY")
# The analysis environment: the agent runs here, and `query` is a durable task in
# the same environment, so the sandboxed code's query calls dispatch as child tasks.
# The Yahoo Finance MCP server needs no credentials (public data), so the only secret
# is the Anthropic key.
env = flyte.TaskEnvironment(
name="code-mode",
image=flyte.Image.from_debian_base().with_pip_packages(
"flyte[mcp]",
"anthropic",
"pydantic-monty",
"duckdb>=1.1.0",
"pandas",
"mcp-yahoo-finance",
),
secrets=[ANTHROPIC_SECRET],
)
The query task itself is a thin wrapper over the tool function, and it carries cache="auto":
# Cache the analytics: given the same SQL over the same fetched series, the result is
# deterministic, so identical queries dedupe across conversations. The fetch itself is
# live and is not cached — it is an MCP tool call the agent makes, not this task.
@env.task(cache="auto")
async def _query_task(sql: str, series: dict[str, str]) -> list[dict]:
return await tools.run_sql(sql, series)
async def query(sql: str, series: dict[str, str]) -> list[dict]:
"""Run a read-only SQL query over fetched stock prices and return rows.
Args:
sql: A DuckDB SELECT statement against the table `prices`
(columns: ticker, date, close). Aggregate in SQL where you can.
series: Maps ticker symbol -> the JSON string returned by
yf_get_historical_stock_prices for it. Pass the raw strings; the
durable task parses them into the `prices` table.
Returns:
A list of row dicts (one per result row), with dates as ISO strings.
"""
return await _query_task(sql, series)
Caching is scoped to query, not the whole environment. Given the same SQL over the same fetched series, the result is deterministic, so identical queries return instantly from cache and dedupe across conversations. The fetch itself is deliberately left off the cache: prices are live, so an MCP call the agent makes (not this task) is the right place for it. analyze is uncached too: it is a non-deterministic model turn keyed on the whole conversation, so it rarely repeats, and caching it could freeze a transient failure.
The native agent
The agent is Flyte’s built-in Agent from the
agent framework with code_mode=True. On each turn the model writes a Python program, the program runs in the sandbox via orchestrate_local, and the render tools populate the report as a side effect. When the report is done the model writes a one-line plain-text summary; a small shim stops there so a second turn can’t re-run the same queries. Sandbox errors are fed back to the model automatically, so it fixes its own code within the turn budget.
agent = CodeModeAgent(
name="code-mode-analyst",
instructions=INSTRUCTIONS,
model="claude-opus-4-8",
# One list, two kinds of local tools: `query` awaits an @env.task, so the sandbox
# dispatches the DuckDB analytics as a durable child task; the render helpers are
# plain callables and run in-process. The live price fetch is a *third* kind — an
# MCP tool contributed by `mcp_servers` below — but the model calls all of them the
# same way. The agent introspects signatures and docstrings to build its prompt.
tools=[
query,
tools.create_metric,
tools.create_chart,
tools.create_table,
tools.calculate_statistics,
],
mcp_servers=_mcp_servers(),
code_mode=True,
# Turn 1 writes the program; the next turn is the plain-text summary. The
# spare turns let the agent fix its code if the sandbox rejects it.
max_turns=5,
call_llm=call_llm,
)
Two things about that tools list are worth pausing on.
First, it mixes bindings. query is an @env.task, so the code-mode runtime passes it through as a task and every call the model writes dispatches as a durable child task. The render helpers are plain callables and run in-process. And the price fetch is a third kind: a tool the MCP server contributes, yet the model calls all three the same way. The split is about more than observability: if query ran in-process, a burst of questions, or one analysis firing several queries, would pile onto the single process handling the request. As a durable task, each query fans out to its own worker on the cluster, with retries for free, while the microsecond render helpers stay in-process where a round-trip would only add latency.
Second, the tools and the instructions are the whole definition of what this agent does, so what you get is a stock analyst, not a general assistant. Ask it to write a sorting function and it will not hand you one: it produces results by running code against the tools it has. That narrowness is a feature for a served app, since the behavior stays predictable and the surface stays small. Code mode itself does not impose the scope; the tools and the prompt do, so to widen or narrow the agent, you change those, not the machinery.
The agent generates its system prompt from the registry, introspecting each function’s signature and docstring, so adding a tool is a matter of writing a function. The instructions add the data description and the report guidance on top.
The LLM callback uses the official Anthropic SDK. The agent’s default callback goes through litellm, which works fine; supplying our own keeps the image lean and the API surface explicit:
async def call_llm(
model: str, system: str, messages: list[dict], tools_schema: list[dict] | None
) -> LLMMessage:
"""LLM callback for the agent, using the official Anthropic SDK.
The agent's default callback goes through litellm; supplying our own keeps the
image lean and the API surface explicit. In code mode `tools_schema` is None
(tools are called from generated code, not via JSON tool-calling).
"""
from anthropic import AsyncAnthropic
client = AsyncAnthropic() # reads ANTHROPIC_API_KEY, injected as a Flyte secret
resp = await client.messages.create(
model=model,
max_tokens=4096,
thinking={"type": "adaptive"},
system=system,
messages=messages,
)
text = "".join(block.text for block in resp.content if block.type == "text")
return LLMMessage(content=text)
This does not have to be Claude. The call_llm callback is the only model-specific code; everything around it is model-agnostic. Point it at any chat-completion endpoint, including an open model you host yourself, for example
an LLM served with vLLM as its own app right alongside this one. That keeps the data and the model on your own infrastructure and drops the per-call API cost in exchange for running the inference yourself.
The report collector
The code-mode loop ends in a plain-text answer, but the app renders structured HTML blocks: metric cards, charts, tables. A per-run collector bridges the two. Each render tool appends its HTML as a side effect and returns a short confirmation (which keeps the sandbox observations small), and analyze reads the blocks back after the agent finishes. A ContextVar keeps concurrent runs isolated:
# The native code-mode loop ends in a plain-text answer, but the UI renders
# structured HTML blocks. A per-run collector bridges the two: each render tool
# appends its HTML here as a side effect, and the `analyze` task reads the blocks
# back after the agent finishes. A ContextVar keeps concurrent runs isolated.
_REPORT: contextvars.ContextVar[list | None] = contextvars.ContextVar(
"report", default=None
)
def start_report() -> None:
"""Begin a fresh report for this run (called by `analyze` before the agent)."""
_REPORT.set([])
def collect_report() -> list[str]:
"""Return the HTML blocks rendered so far, in the order they were created."""
return list(_REPORT.get() or [])
def _add_block(html: str) -> None:
blocks = _REPORT.get()
if blocks is not None:
blocks.append(html)
Live prices over MCP
External tools plug in over MCP with MCPServerSpec. The agent connects on first use, lists the server’s tools, and registers each one alongside the local tools; the model calls them from its generated code like any other function. The example wires the mcp-yahoo-finance server, launched as a subprocess in the task pod, with no credentials since it reads public market data:
def _mcp_servers() -> list[MCPServerSpec]:
"""The Yahoo Finance MCP server — the agent's live price source.
The agent connects on first use, lists the server's tools, and registers each
one alongside the local tools; the model calls them from its generated code
like any other function. `tool_prefix` namespaces them, and `tool_filter`
narrows the server's 12 tools down to the one the analytics needs, the same
surface-shrinking move as the SQL guard. No auth: the server reads public
Yahoo Finance data, so there is no secret to inject.
"""
return [
MCPServerSpec(
name="yahoo-finance",
command=["mcp-yahoo-finance"],
tool_prefix="yf_",
tool_filter=["get_historical_stock_prices"],
)
]
tool_prefix namespaces the server’s tools (yf_get_historical_stock_prices) to avoid collisions, and tool_filter narrows the server’s twelve tools down to the one the analytics needs, the same surface-shrinking move as the SQL guard: the model never even sees the tools it should not use, and the prompt stays small. Because the sandbox has no json, the model never parses the tool’s raw output. It passes the string straight to query, which does the reshape. Fetching a ticker becomes one more function call in the model’s program, sitting alongside the durable query.
The analysis task
analyze ties it together: start a fresh report, run the agent with the chat history as its memory (so a follow-up like “now compare it with two peers” refers back to earlier turns), collect the blocks, and return them with the summary. It also appends a link to its own run, so every answer carries a click-through to the task graph that produced it:
@env.task
async def analyze(message: str, history: list[dict[str, str]]) -> dict:
"""Run one analysis: start a report, run the agent, return blocks + summary.
`history` is the prior conversation, which `Agent.run` takes as its memory, so
follow-ups can refer back to earlier turns. This task is the chat app's
`task_entrypoint`: each question becomes a run, and inside it the sandbox's
`query` calls dispatch as durable child tasks.
"""
tools.start_report()
result = await agent.run.aio(message, memory=list(history))
blocks = tools.collect_report()
if link := await _run_link_block():
blocks.append(link)
# The UI renders the summary as Markdown, where a pair of ~ characters becomes
# strikethrough. Models like ~ as shorthand for "approximately", so escape it.
summary = result.summary.replace("~", "\\~")
return {
"summary": summary,
"charts": blocks,
"code": result.code,
"error": result.error,
"attempts": result.attempts,
}
Because analyze runs inside a task context, the query calls made by the sandboxed code dispatch as durable child tasks. You can run this half on its own with python analysis.py, which submits one analysis as a flyte.run and prints the run URL, no app required.
Serving it: the native chat app
The web layer is one declaration. AgentChatAppEnvironment from the
agent chat UI provides the chat interface, the tools sidebar, progress streaming, and the chat endpoint:
env = AgentChatAppEnvironment(
name="code-mode-analytics",
agent=agent, # powers the tools sidebar
# Each question is launched as a durable run of `analyze` (with the chat
# history), so the sandbox's query calls dispatch as tracked child tasks.
task_entrypoint=analyze,
# Run those tasks with the caller's forwarded credentials.
passthrough_auth=True,
title="Code Mode Stock Analytics",
subtitle=(
"Chat with live stock prices. The model writes one Python program per "
"question; it fetches prices from the Yahoo Finance MCP server and runs "
"the heavy queries as durable Flyte tasks."
),
prompt_nudges=_prompt_nudges,
theme=CustomTheme(
accent_color="#0ea5e9",
accent_hover_color="#0284c7",
button_text_color="#ffffff",
),
image=flyte.Image.from_debian_base().with_pip_packages("fastapi", "uvicorn"),
scaling=flyte.app.Scaling(replicas=1),
depends_on=[agent_env],
# Every request launches a run (compute + a paid LLM call), so gate the app
# behind platform auth.
requires_auth=True,
)
Two parameters do the architectural work.
task_entrypoint=analyze makes each question a durable run. An app’s request handler has no task context, so calling a task directly from it would run the task locally in the app pod and you would lose durability and the child-task graph. With a task entrypoint, the chat endpoint launches analyze with flyte.run (passing the message and the history), streams the run’s phase changes to the UI as progress, and renders the returned blocks. For more on apps and tasks calling each other, see
hybrid app-task graphs.
passthrough_auth=True forwards each caller’s credentials to those runs, so the analysis executes as the signed-in user rather than as a shared service identity, and the app needs no credential plumbing of its own. Together with requires_auth=True, which gates the app at the platform gateway, every request is authenticated end to end, which matters because each one launches real compute and a paid LLM call.
The rest is presentation: a theme for the accent colors, prompt nudges shown before the first message (ready-made comparisons like “Compare AAPL and MSFT over the last year”), and a title and subtitle.
Deploy and run
Deploying is one command. The entry point uses the remote image builder so no local Docker is needed, and serves the app and its task environment together:
if __name__ == "__main__":
# Remote image builder so no local Docker is needed to build the app + task images.
flyte.init_from_config(image_builder="remote")
handle = flyte.serve(env)
print(f"Deployed Code Mode Stock Analytics: {handle.url}")
Register your Anthropic key as a secret and deploy:
$ flyte create secret anthropic_api_key <your-anthropic-key>
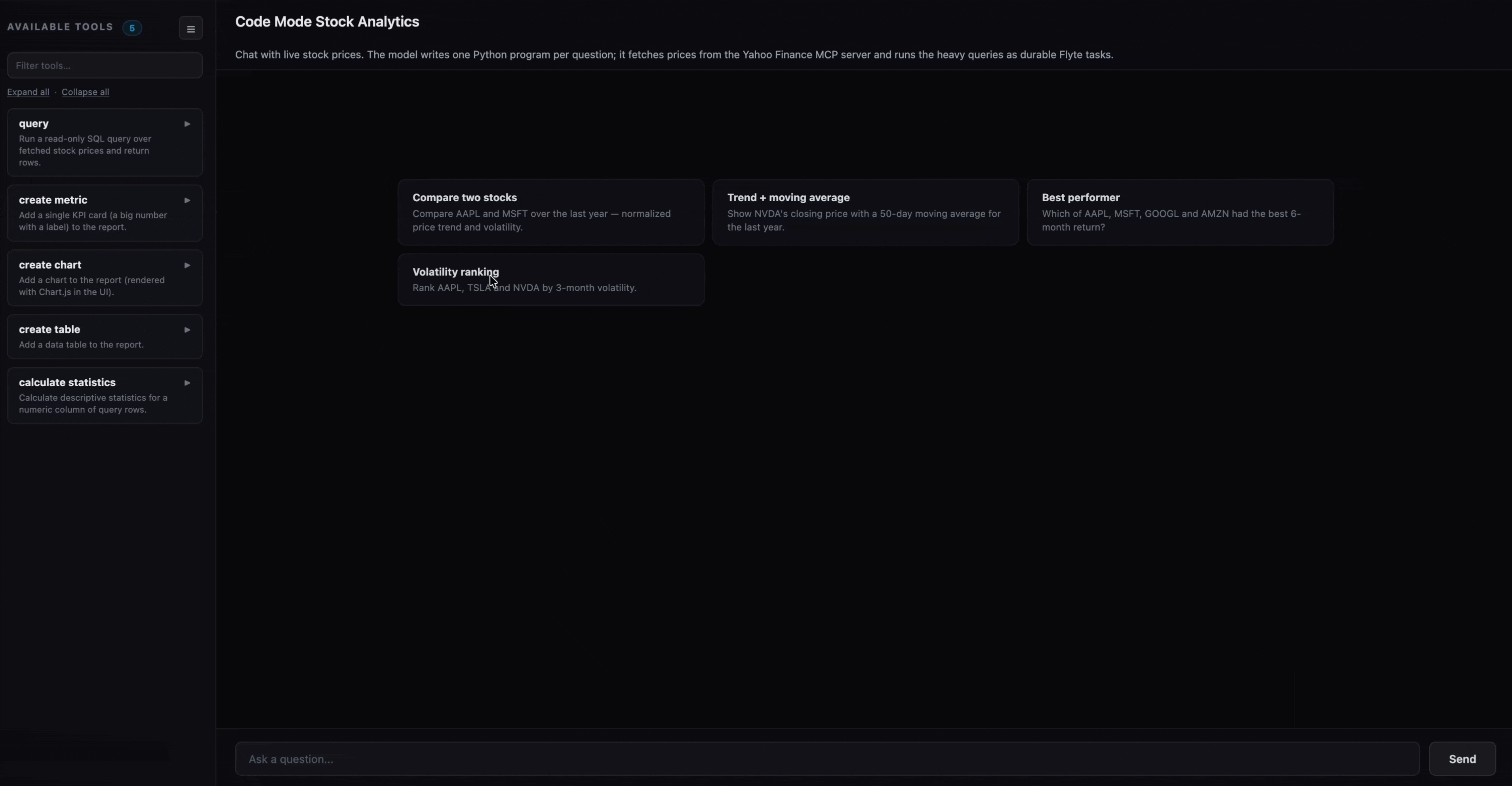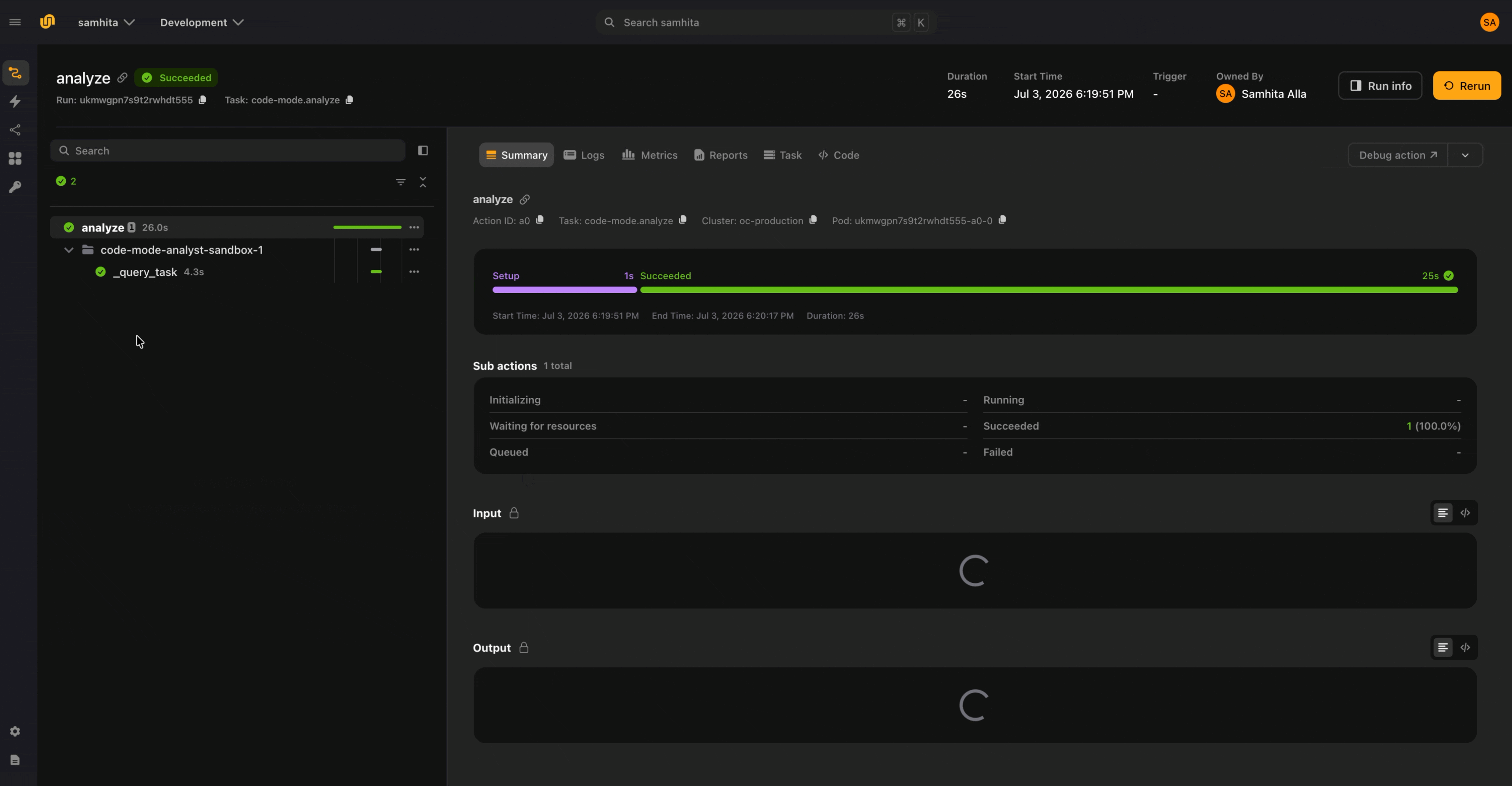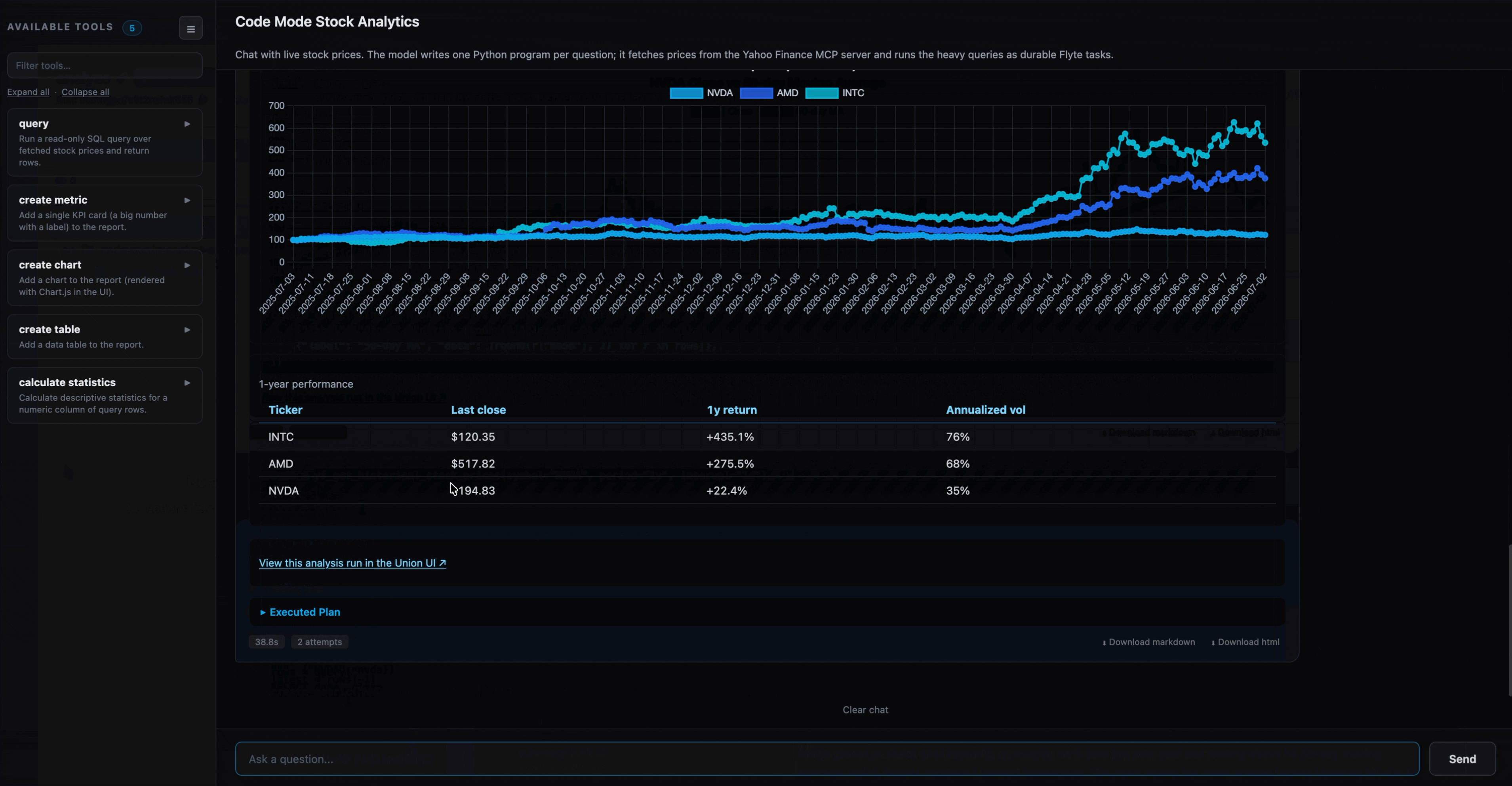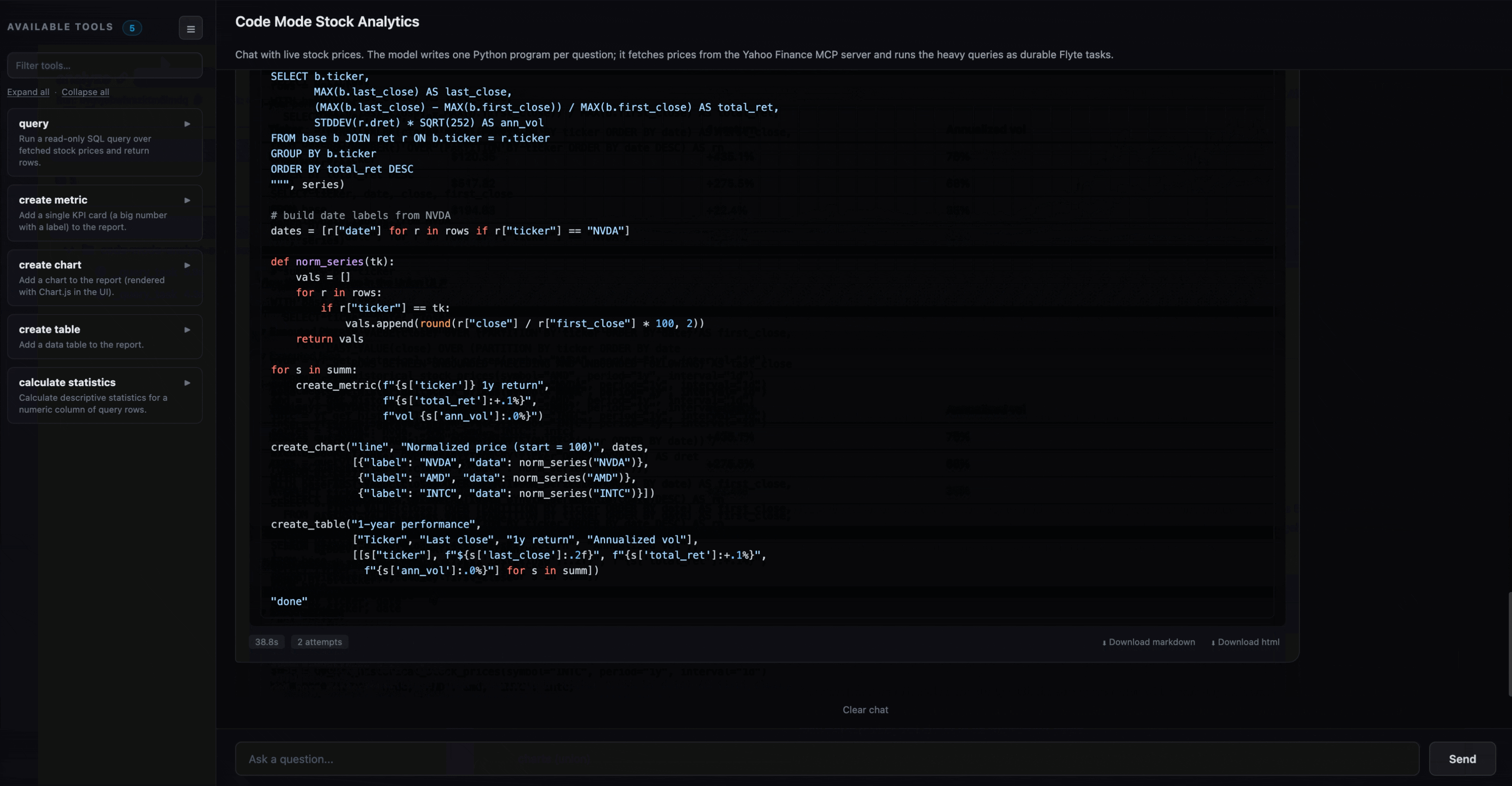
$ python app.pyOpen the printed URL and ask something like “Compare AAPL and MSFT over the last 6 months” or “Rank the FAANG stocks by 6-month return.” The first question is slower as the task image builds and the MCP server cold-starts, then each answer streams progress while the run executes, and comes back as a short report of headline numbers, a chart, and sometimes a table, with the generated code and a link to the run so you can see the query tasks it dispatched.
Going further
- More history, more tickers. The queries are ordinary DuckDB SQL over whatever the model fetches. Because
queryis a durable task, large or slow queries get retries and caching for free. - More MCP servers. Add another
MCPServerSpecfor web search, Slack, or a ticketing system. Usetool_filterto expose only the tools the agent should have. - Add a model-based tool. A tool that calls another model, such as an LLM judge or an embedder, registers like any other. Cheap tools stay in-process, and expensive ones become tasks.
- More tools. Write a function with a docstring and add it to the agent’s
toolslist. The prompt regenerates from the signatures, so there is nothing else to wire up.