Voice customer-service agent
Code available here.
Talk to a customer-support agent in your browser and hear it answer back. This tutorial builds that agent as two Flyte apps: a small Qwen model served with vLLM on a GPU, and a web app that serves a single-page voice UI and proxies the model. Speech recognition runs in the browser, the reply streams back as text, and the text is spoken aloud. Once Union is set up, bringing the whole thing online is two python commands.
By the end you will understand, and have running:
- how to serve an LLM as a Flyte app with
VLLMAppEnvironment, exposing an OpenAI-compatible endpoint, - how to build a web app with
FastAPIAppEnvironmentthat serves a UI and proxies the model, - how the two apps compose, with the browser only ever talking to its own origin,
- how text-to-speech is switchable between the browser and a neural voice served on Union, with a live latency comparison, and
- how Flyte app features like health checks, warm replicas, and per-app routing turn this into something that feels like a product.
The agent is “Ava”, a support rep for a fictional electronics company called Northwind. The model is Qwen/Qwen2.5-3B-Instruct, which is public, so no Hugging Face token is needed, and small enough to be snappy on a single L4 GPU.
How it fits together
The demo is two apps plus the browser:
| App | Environment | Hardware | Job |
|---|---|---|---|
llm_app |
VLLMAppEnvironment |
L4 GPU | serve Qwen with vLLM, OpenAI-compatible /v1 |
ui_app |
FastAPIAppEnvironment |
CPU | serve the voice page, proxy chat to llm_app, synthesize speech |
Speech recognition and the default text-to-speech run in the browser through the Web Speech API, so there is no audio model to host for input and the GPU footprint stays tiny. The browser talks only to the UI app, and the UI app talks to the model. That keeps the model internal and avoids any cross-origin setup in the browser.
flowchart LR
B["Browser<br/>mic + speaker<br/>Web Speech API (STT)"]
subgraph UI["ui_app · FastAPIAppEnvironment · CPU"]
P["/ voice page<br/>/api/chat proxy<br/>/api/tts (Kokoro)"]
end
subgraph LLM["llm_app · VLLMAppEnvironment · L4 GPU"]
Q["Qwen2.5-3B-Instruct<br/>OpenAI /v1"]
end
B -- "text turn" --> P
P -- "/v1/chat/completions (streamed)" --> Q
Q -- "tokens" --> P
P -- "reply text or spoken WAV" --> B
classDef ui fill:#e0f2fe,stroke:#0369a1,color:#1a1a2e;
classDef gpu fill:#fde68a,stroke:#b45309,color:#1a1a2e;
classDef br fill:#ede9fe,stroke:#6d28d9,color:#1a1a2e;
class P ui;
class Q gpu;
class B br;
Serving the UI as a Flyte app, rather than hosting it somewhere separate, means the web tier gets the same treatment as the model: a managed endpoint, autoscaling, logs, and one deploy and auth story across both apps, with no separate web server to stand up or operate. It sits next to the model it proxies instead of reaching across the internet to it. Serving over HTTPS by default is part of that same package, and it happens to clear a practical hurdle for voice, since the browser only grants microphone access and speech recognition on a secure origin. So the page works the moment it deploys.
Serving the model
The model app is a VLLMAppEnvironment. It wraps vLLM, downloads the weights, and exposes the standard OpenAI /v1 API, so the UI talks to it the same way it would talk to any OpenAI-compatible server.
First, the image. Flyte’s Image API defines the runtime as a chain of layers you control, so you pin exactly what a served model needs.
vllm_image = (
flyte.Image.from_debian_base(name="vllm-app-image", install_flyte=False)
.with_pip_packages("flashinfer-python", "flashinfer-cubin")
.with_pip_packages("flashinfer-jit-cache", index_url="https://flashinfer.ai/whl/cu129")
.with_pip_packages("flyteplugins-vllm")
.with_pip_packages("vllm==0.11.0", "transformers==4.57.6")
)
The app itself is a few lines. Qwen/Qwen2.5-3B-Instruct is about 6 GB in bf16 and fits an L4 comfortably. scaling=flyte.app.Scaling(replicas=(1, 1)) keeps exactly one warm replica so there is no cold start mid-demo, and the short --max-model-len keeps the KV cache small and latency low, which is all a customer-service turn needs.
try:
from flyteplugins.vllm import VLLMAppEnvironment
llm_app = VLLMAppEnvironment(
name="cs-qwen-llm",
model_id=MODEL_ID,
model_hf_path="Qwen/Qwen2.5-3B-Instruct",
image=vllm_image,
resources=flyte.Resources(cpu="6", memory="20Gi", gpu="L4:1", disk="40Gi"),
# One warm replica so there's no cold start mid-demo. Flip to (0, 1) +
# scaledown_after to save the GPU when idle, at the cost of a cold start.
scaling=flyte.app.Scaling(replicas=(1, 1)),
requires_auth=False,
extra_args=[
# Short context keeps the KV cache small and latency low; a customer
# service turn is tiny.
"--max-model-len",
"8192",
"--max-num-seqs",
"16",
],
)
except ImportError:
llm_app = None # flyteplugins-vllm not installed (e.g. the UI container)
llm_app is a module-level variableThe default serving entry point resolves the app by module:attr, so llm_app has to be importable at module level. If it were created inside a function, the resolver would silently fall back to ui_app, and the GPU pod would end up running the web UI and returning 404 on /v1. The flyteplugins-vllm import is guarded so the lightweight UI image, which never installs that plugin, still imports this module cleanly.
The voice UI app
The UI is a FastAPIAppEnvironment. You hand it a plain FastAPI app, and Flyte serves it over HTTPS. This one serves the single-page voice client at /, proxies chat to the model at /api/chat, and synthesizes neural speech at /api/tts.
ui_app = FastAPIAppEnvironment(
name="cs-voice-ui",
app=fastapi_app,
description="Browser voice UI for the Qwen customer-service agent (browser + Kokoro TTS)",
image=ui_image,
# Bumped for torch + the Kokoro model living in memory.
resources=flyte.Resources(cpu="6", memory="8Gi"),
requires_auth=False,
scaling=flyte.app.Scaling(replicas=(1, 1)),
)
It runs on CPU, with no GPU at all. The server-side voice uses Kokoro, an 82M-parameter text-to-speech model that runs comfortably on CPU, so the image bundles a CPU build of torch to keep it small.
ui_image = (
flyte.Image.from_debian_base(name="cs-voice-ui")
.with_apt_packages("espeak-ng") # Kokoro's grapheme->phoneme runtime dep
# CPU torch wheel keeps the image far smaller than the default CUDA build.
.with_pip_packages("torch", index_url="https://download.pytorch.org/whl/cpu")
.with_pip_packages(
"fastapi", "uvicorn", "httpx", "kokoro>=0.9.2", "soundfile", "numpy"
)
# Kokoro's G2P (misaki) needs spaCy's en_core_web_sm.
.with_commands(["python -m spacy download en_core_web_sm"])
)
The agent and the proxy
The agent’s whole personality is a system prompt. Because the replies are spoken aloud in something that feels like a phone call, it asks for short, plain sentences, one question at a time, and tells the model to say it will look into account-specific details rather than invent them.
SYSTEM_PROMPT = (
"You are Ava, a warm, efficient customer-support agent for 'Northwind', a "
"consumer electronics company. Your replies are spoken aloud in a live phone-"
"like call, so keep them very short (1-2 sentences), natural, and free of "
"markdown, lists, or emoji. Get to the point in the first sentence. Ask one "
"clarifying question at a time. The caller may interrupt you at any moment; if "
"they do, stop and listen. If you don't know an account-specific detail, say "
"you'll look into it rather than inventing facts."
)
The proxy is what the browser actually calls. It injects the system prompt, forwards the turn to the selected model backend, and streams the reply back as plain text token by token. Keeping the model behind this proxy is what lets the browser talk only to its own origin.
@fastapi_app.post("/api/chat")
async def chat(req: Request):
"""Proxy a chat turn to the selected vLLM backend and stream the text reply back."""
body = await req.json()
history = body.get("messages", [])
chosen = _pick_backend(body.get("backend"))
base = (chosen or {}).get("url", "")
payload = {
"model": await _model_id_for(base),
"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *history],
"stream": True,
"max_tokens": 200,
"temperature": 0.3,
}
async def gen():
url = f"{base}/v1/chat/completions"
async with httpx.AsyncClient(timeout=120.0) as client:
async with client.stream("POST", url, json=payload) as r:
r.raise_for_status()
async for line in r.aiter_lines():
if not line.startswith("data:"):
continue
data = line[len("data:") :].strip()
if data == "[DONE]":
break
try:
delta = json.loads(data)["choices"][0]["delta"].get("content")
except (json.JSONDecodeError, KeyError, IndexError):
continue
if delta:
yield delta
return StreamingResponse(gen(), media_type="text/plain")
Speech in, speech out
Speech recognition happens in the browser through the Web Speech API, so the microphone is transcribed locally and only text is sent to the model. This needs Chrome or Edge.
For the reply, the page offers two voices you can switch between live:
- Browser, using the built-in
speechSynthesis. It is the lowest latency, but its audio is not echo-cancelled, so it is best with headphones. - Server, using Kokoro, a neural voice served by the UI app. Its audio plays through the Web Audio graph, which the browser’s echo canceller can subtract, so it works on open speakers without the agent interrupting itself. The page defaults to this when it is ready.
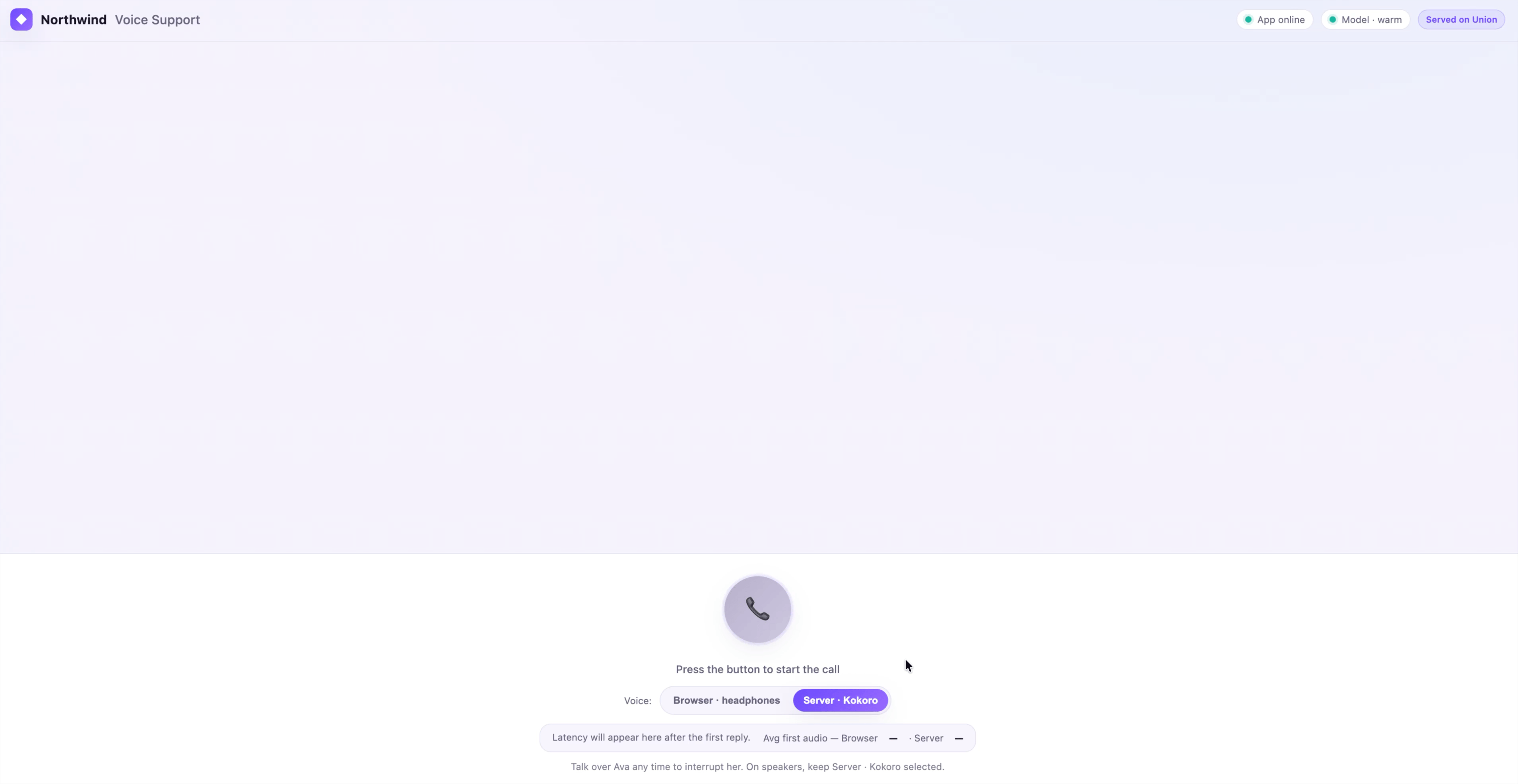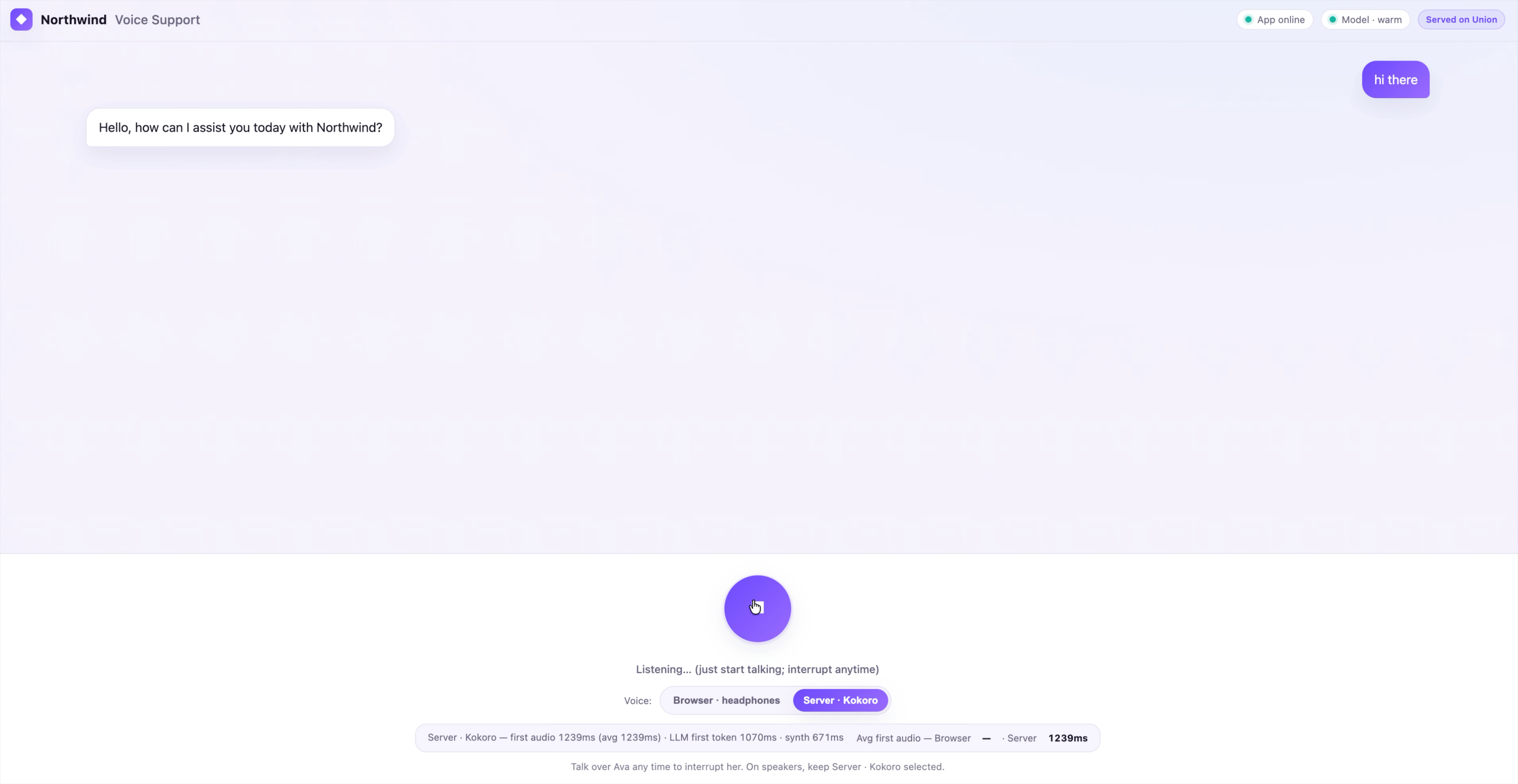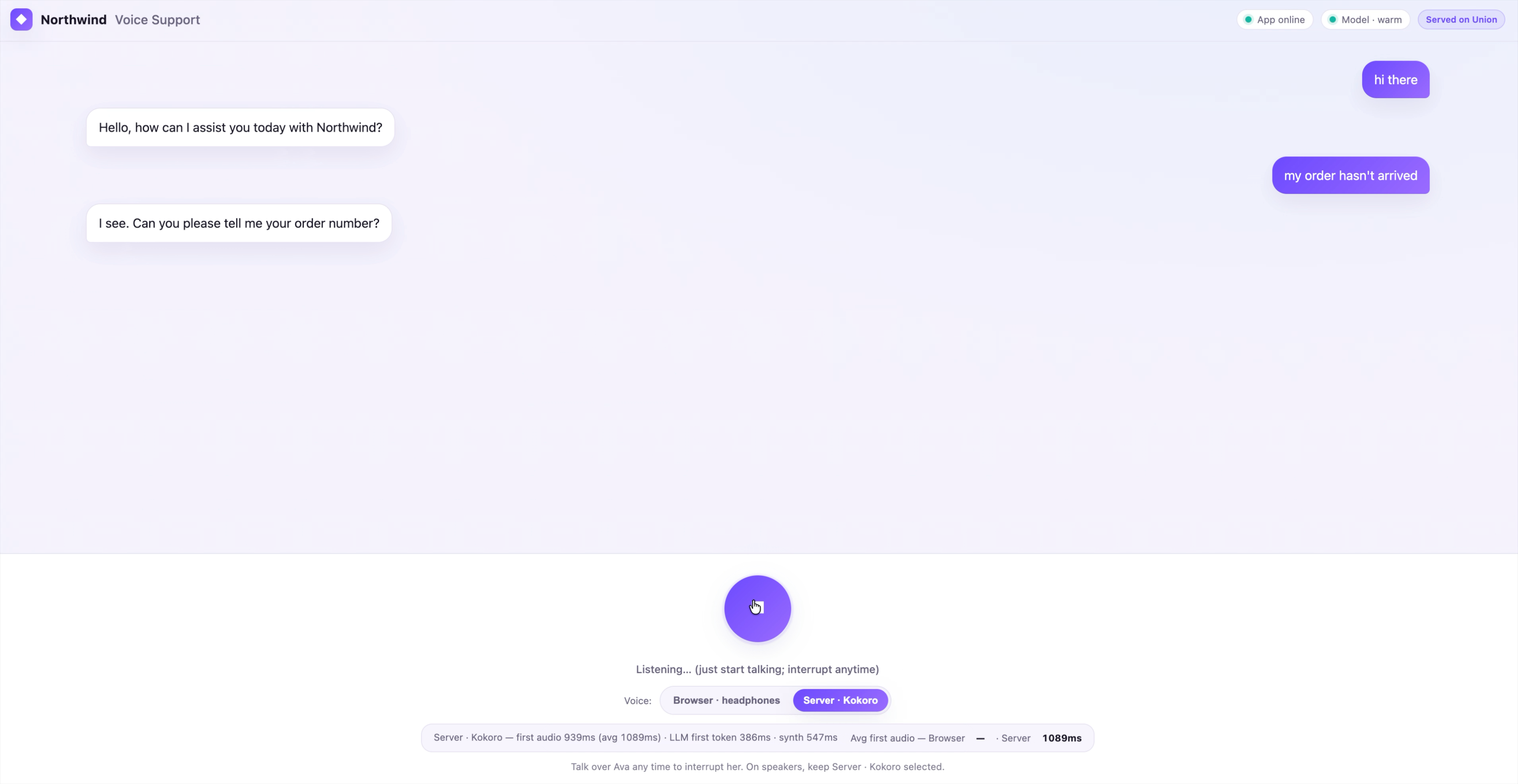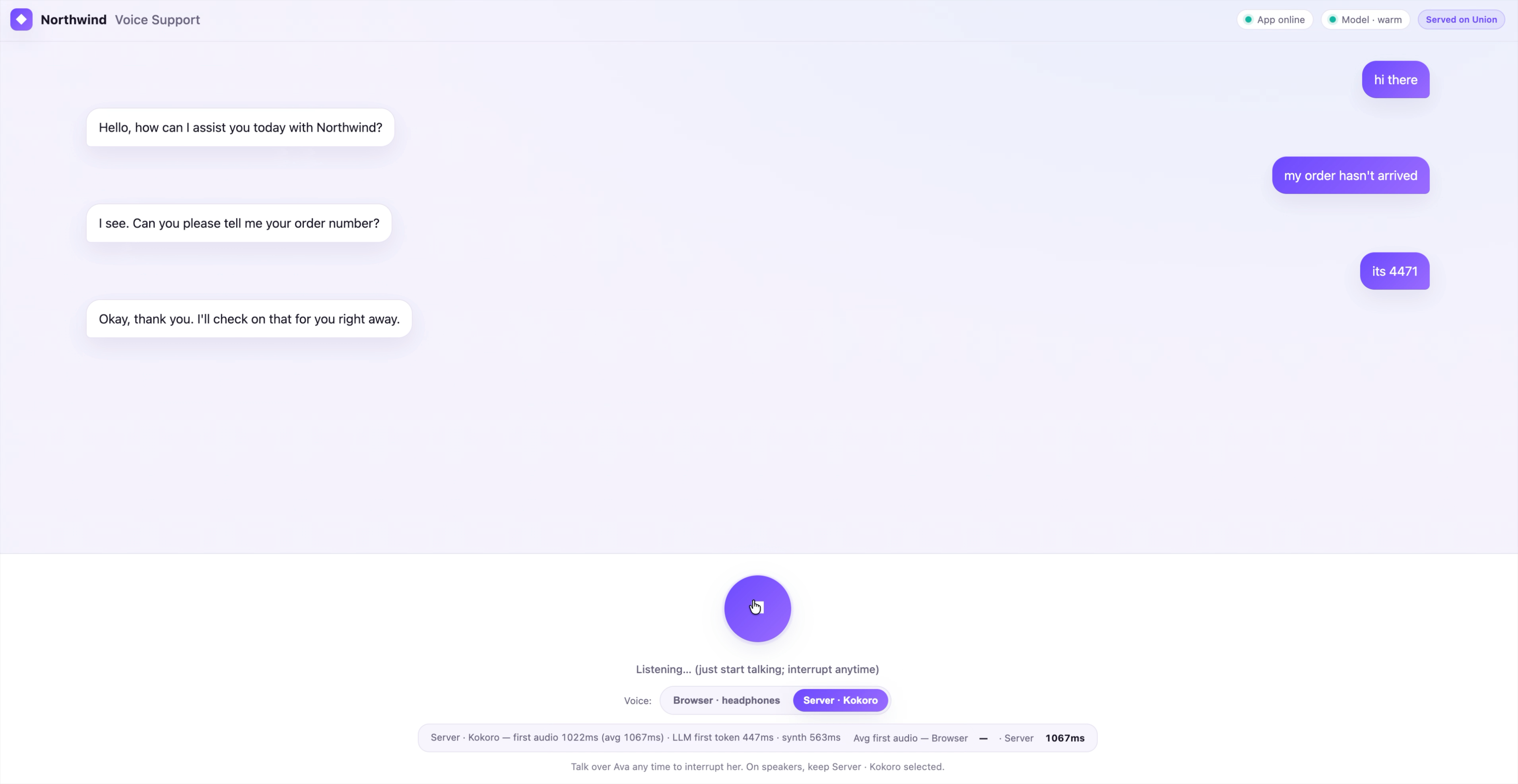
The server voice is one endpoint. It synthesizes a clause of speech with Kokoro and returns a WAV, with the measured synthesis time in a response header so the page can show it.
@fastapi_app.post("/api/tts")
async def tts(req: Request):
"""Synthesize speech for one clause with Kokoro; returns a 24 kHz WAV.
The X-Synth-Ms response header carries the measured server-side synthesis
time so the client can display/compare latency.
"""
body = await req.json()
text = (body.get("text") or "").strip()
if not text:
return Response(status_code=204)
if _tts_state["pipeline"] is None:
return Response(status_code=503, content=_tts_state["error"] or "TTS not ready")
t0 = time.perf_counter()
async with _synth_sem:
audio = await asyncio.to_thread(_synth, text)
wav = await asyncio.to_thread(_wav_bytes, audio)
synth_ms = int((time.perf_counter() - t0) * 1000)
return Response(content=wav, media_type="audio/wav", headers={"X-Synth-Ms": str(synth_ms)})
A few details make the conversation feel natural rather than like a walkie-talkie:
- Clause-by-clause speech. The reply is spoken as soon as the first clause is ready, and the next clause is fetched while the current one plays, so only the first clause’s latency is ever felt.
- Barge-in. The page watches microphone energy, and when you start talking over Ava it cancels both the model stream and the speech playback, so she stops and listens.
- A live latency comparison. After each reply the footer shows time-to-first-audio for the voice you used, and keeps a running average for both, so you can compare the browser and server voices side by side.
What makes this a good Flyte app
The interesting part is not the model, it is how little stands between “I have a model” and “I have a product”. A few things the UI surfaces on purpose:
Two right-sized apps, composed. A GPU model server and a CPU web app are separate environments with their own images and resources. They are wired together at deploy time by passing the model’s URL into the UI app’s environment, and nothing else.
Health you can see. The header shows two status pills. One pings the UI app’s own health endpoint. The other pings the model app and reports whether a warm replica is serving. That second check is a direct read on the Scaling policy: it stays warm with replicas=(1, 1), and would show a cold start if you let the model scale to zero when idle.
@fastapi_app.get("/api/backend")
async def backend_status(req: Request):
"""Liveness of a chat backend, for the "model warm / waking" pill.
Pings the vLLM app's ``/v1/models``. A quick OK means a warm replica is already serving;
a failure or a timeout is the cold start you'd see with ``Scaling(replicas=(0, 1))``.
"""
chosen = _pick_backend(req.query_params.get("backend"))
base = (chosen or {}).get("url", "")
if not base:
return {"up": False, "model": None}
try:
async with httpx.AsyncClient(timeout=4.0) as client:
r = await client.get(f"{base}/v1/models")
r.raise_for_status()
data = r.json()
return {"up": True, "model": (data.get("data") or [{}])[0].get("id")}
except Exception:
return {"up": False, "model": None}
Serve many models, switch live. Because another model is just another app, the UI can route between several. Point it at more than one backend and a model switcher appears in the page; each chat turn goes to the selected one. With a single backend it stays hidden, so the default demo is unchanged.
# Optional model switcher. Set LLM_BACKENDS to a comma-separated list of "Label|https://url"
# pairs — each url is its own vLLM app — and the UI shows a dropdown to route between them.
# Serving another model is just another Flyte app, so this is the whole "switch models" story.
# When unset, the single LLM_BASE_URL above is used and no switcher appears (default demo).
LLM_BACKENDS = os.environ.get("LLM_BACKENDS", "")
# Served-model-id per backend url, cached so each vLLM app is asked at most once.
_model_cache: dict = {}
def _backends() -> list:
"""The list of {label, url} chat backends; a single Default unless LLM_BACKENDS is set."""
pairs = []
for item in LLM_BACKENDS.split(","):
label, sep, url = item.partition("|")
if sep and url.strip():
pairs.append({"label": label.strip(), "url": url.strip().rstrip("/")})
if pairs:
return pairs
base = os.environ.get("LLM_BASE_URL", LLM_BASE_URL).rstrip("/")
return [{"label": "Default", "url": base}] if base else []
def _pick_backend(label: str | None) -> dict | None:
"""Choose a backend by label, falling back to the first configured one."""
backends = _backends()
return next((b for b in backends if b["label"] == label), backends[0] if backends else None)
async def _model_id_for(base: str) -> str:
"""Ask a vLLM backend which model id it serves (cached); fall back to MODEL_ID."""
if not base:
return MODEL_ID
if base not in _model_cache:
mid = MODEL_ID
try:
async with httpx.AsyncClient(timeout=4.0) as client:
r = await client.get(f"{base}/v1/models")
r.raise_for_status()
mid = ((r.json().get("data") or [{}])[0].get("id")) or MODEL_ID
except Exception:
mid = MODEL_ID
_model_cache[base] = mid
return _model_cache[base]
This is the kind of thing that is painful to stand up by hand and nearly free here: each backend is its own addressable Flyte app, so comparing two models, or two voices, becomes a dropdown rather than a project.
Deploy
You will need a Union deployment with GPU capacity. The example uses an L4, and any single modern GPU is enough for a 3B model. Point your Flyte config at your endpoint, and the example uses the remote image builder, so no local Docker is needed.
The model is public, so there is no token to set up. Bring up the two apps in order, passing the model URL from the first into the second:
# 1. Bring up the GPU model server (provisions an L4 and pulls weights, so give it a few minutes)
python app.py llm
# 2. Bring up the voice UI, pointed at the deployed model endpoint from step 1
python app.py ui --llm-url https://<llm-url>Open the UI URL in Google Chrome, click the call button, and start talking. The first deploy of each app also builds its image, which takes a few minutes; later deploys reuse it.
Test without a microphone
Both apps are ordinary HTTP services, so you can exercise them with curl. Hit the model directly through its OpenAI-compatible API:
curl -s https://<llm-url>/v1/chat/completions -H 'content-type: application/json' -d '{
"model": "qwen",
"messages": [{"role": "user", "content": "My order has not arrived. Help?"}]
}' | jq -r .choices[0].message.contentOr go through the UI proxy, which streams plain text and applies Ava’s persona:
curl -N https://<ui-url>/api/chat -H 'content-type: application/json' -d '{
"messages": [{"role": "user", "content": "Do you ship to Canada?"}]
}'Going further
Because it is all plain Flyte apps, each of these is a small change:
- A bigger model. You can swap in a larger model and run it on any silicon for better answers.
- A model switcher. Deploy a second model app and set
LLM_BACKENDSon the UI app to a comma-separated list ofLabel|https://urlpairs. The switcher appears automatically and each turn routes to the selected model. - Lower cost when idle. Change the model app’s
Scalingtoreplicas=(0, 1)with a scaledown so the GPU is released when no one is calling, at the cost of a cold start on the next request. The header’s model pill will show that cold start as it happens. - Authentication. Set
requires_auth=Trueon the apps and pass a token from the client, so the demo doubles as an example of exposing an app safely. - A different persona. The entire agent lives in
SYSTEM_PROMPT. Change it and you have a different assistant.
An LLM behind a polished web UI, served, scaled, and swappable, usually means standing up a model server, a separate web service, and the glue between them. On Flyte it is two decorated objects and two python commands, and the result is an HTTPS app you can hand to anyone with a browser.