Reinforcement learning for LLMs with GRPO and LoRA
Code available here.
This tutorial builds a reinforcement learning loop for an LLM, the same shape of loop the major labs use to train reasoning models, and runs it entirely on the Flyte SDK. Flyte orchestrates the tasks and supplies the pieces that make the loop fast and reliable: a warm pool of reusable GPU containers for generation, right-sized environments for each stage, automatic recovery after failures, and a live report you can watch as training moves. Once you have Union and the Flyte SDK installed, running the whole thing is a single python command.
By the end you will understand, and have running:
- the RL-for-LLMs loop (sample, generate, score, update, repeat) and the GRPO objective behind it,
- how Flyte keeps a vLLM engine warm across iterations so you never reload the base model,
- how a small LoRA adapter is trained with one policy-gradient step and handed back to the generator,
- how generation and reward scoring overlap so the GPU stays busy, and
- how the run resumes after a preemption and streams a live progress report.
The example uses a small policy (Qwen3-0.6B) on a single L4 GPU so the loop is cheap to run end to end. It was validated on a Union cluster across three GRPO iterations. With a model this size and a toy dataset, the run proves the machinery rather than convergence, so scale the model and dataset once the loop is working for you.
Why Flyte with Union fits RL training
RL training loops are genuinely awkward to run well. They mix very different work in a tight cycle: GPU text generation, cheap CPU scoring, and GPU gradient steps. They run long enough that failures become a certainty rather than a risk. And they are hard to observe while they run. This is the shape of problem Flyte with Union is built for, which is why the loop in this tutorial is nothing more than a for loop of ordinary Python functions. You write plain Flyte tasks, and Union runs them: provisioning the GPUs, holding the warm pools alive, and serving the UI and reports.
What you get without writing any of it yourself:
- The right hardware for each step. Generation, reward, and training have different needs, so each is its own task environment with its own resources. GPU for rollouts and the trainer, cheap CPU for reward and the driver. You never pay for a GPU to run a reward function.
- Warm pools for the expensive parts. Loading a model into vLLM is slow, so the generator runs in a reusable environment. Flyte holds a pool of warm replicas with the model already resident, and every iteration reuses them. This is the single biggest speedup in an RL-for-LLMs loop, and it costs one line of config.
- Autoscaling to the resources you have. The warm pool scales between a minimum and maximum replica count with demand, so the rollout fan-out spreads across whatever GPUs are available and scales back down when the loop is idle. You do not size a cluster up front.
- Isolation across concurrent runs. Every run is its own set of containers with its own warm pool, state, and report. You and your teammates can run many experiments at once without them stepping on each other.
- Long runs that survive failures. RL runs for hours or days, and spot preemptions and OOMs happen.
flyte.Checkpointresumes the loop mid-run, task retries recover transient errors, and the pool recovers replicas on its own. There is no control plane for you to write. - Observability and data plumbing, handled. Every rollout, reward, and gradient step is a tracked task with logs and lineage.
flyte.grouporganizes iterations in the workflow, andreport=Truestreams a live report. The LoRA adapter flows from trainer to generator as aflyte.io.Dir, and the base model is prefetched into object storage once, so there is no shared filesystem and no manual file shuffling.
The rest of this tutorial shows each of these in action.
The idea: RL for LLMs in one loop
Reinforcement learning fine-tunes a language model against a reward instead of against fixed target text. Whatever the lab or the algorithm, the loop has the same shape:
sample prompts
│
▼
generate several candidate answers per prompt ← the policy (our LLM) acts
│
▼
score each answer with a reward function ← how good was it?
│
▼
nudge the policy toward higher-reward answers ← the gradient step
│
▼
repeat with the improved policyWhat is GRPO?
GRPO (Group Relative Policy Optimization) is the algorithm behind reasoning models like DeepSeek-R1. Its one big idea: to judge whether an answer was good, compare it against other answers to the same prompt, instead of training a separate value network to predict a baseline the way PPO does. That keeps it simple and cheap to run.
For each prompt we sample a group of G answers and compute a group-relative advantage:
advantage(answer_i) = (reward_i − mean(rewards in group)) / (std(rewards in group) + ε)Answers above their group’s average get a positive advantage, which makes them more likely. Answers below it get a negative advantage, which makes them less likely. The objective we maximize is:
J(θ) = mean over answers [ advantage_i · (average log-probability the policy assigns to answer_i) ]That is the whole idea with no critic or replay buffer. The example implements this objective directly so you can read exactly what every line does. The full GRPO paper adds a PPO-style clipped ratio and a KL penalty against a reference model. We leave both out to keep the math legible, which is fine for the single-gradient-step-per-iteration setup here, and the code notes where they would go.
Why LoRA?
Updating all of a model’s weights each iteration is expensive, and it makes the handoff between the trainer and the generator enormous. So we freeze the base model and train a small LoRA adapter, a pair of low-rank matrices layered on top of the frozen weights. The adapter is only a few megabytes, and that is what makes the warm-engine trick work: the generator keeps the big frozen base resident and swaps in the tiny adapter each iteration.
Coming from Ray or RLlib?
If you have built RL with Ray, the mental map is direct:
| In Ray/RLlib | Here (Union + Flyte SDK) |
|---|---|
| Rollout worker actors | the warm vLLM pool (generate) |
| Learner / trainer | the train_step task |
| Driver / Tune loop | a plain async driver task (train_rl) |
ray.remote calls |
calling another task (await generate(...)) |
The difference is that there is no separate cluster to launch and operate. Each box is a Python function with a decorator, and Flyte schedules them, moves data between them, retries them, and shows them in a UI.
How the work is laid out
The loop is four task environments plus a one-time model prefetch:
| Environment | Hardware | Job |
|---|---|---|
generate (rollout) |
GPU, warm pool | run vLLM, produce candidate answers with the current adapter |
score_group (reward) |
CPU | grade a group of answers (rule-based and verifiable) |
train_step (trainer) |
GPU | one GRPO step, emit the new LoRA adapter |
train_rl (driver) |
CPU | run the for loop, wire everything together, checkpoint |
The interesting part is the warm pool. Loading even a small model into a vLLM engine takes time, so if generate were a fresh container on every call you would pay that cost on every rollout. Instead generate runs in a reusable environment: Flyte keeps a pool of warm replicas alive between calls, each holding the loaded engine in memory, and autoscales that pool with demand. Everything else is an ordinary ephemeral pod, cheap to start and stateless between iterations.
Warm-pool topology
Only the rollout generator is a warm pool (🔥). The driver, reward, and trainer are ephemeral (❄):
flowchart TB
P["flyte.prefetch.hf_model(Qwen3-0.6B)<br/><i>runs once, before the loop</i>"] --> B["base model Dir<br/>in object store"]
D["DRIVER · train_rl<br/>❄ ephemeral · CPU · one pod for the whole run<br/>async <code>for it in range(N)</code>:<br/>fan out, score, GRPO step, checkpoint"]
subgraph POOL["🔥 WARM POOL · rl-grpo-rollout · GPU · ReusePolicy(replicas=1..4, concurrency=1, idle_ttl=300)"]
direction LR
R1["replica 1<br/>vLLM + BASE<br/>(frozen, resident)"]
R2["replica 2<br/>vLLM + BASE<br/>(frozen, resident)"]
R3["replica 3..4<br/>autoscaled on load"]
end
S["score_group × groups<br/>❄ ephemeral · CPU<br/>one task per prompt group (as_completed)"]
T["train_step<br/>❄ ephemeral · GPU<br/>one GRPO step per iteration"]
D -- "generate(prompt, adapter, version)" --> POOL
POOL -- "rollouts" --> S
S -- "rewards" --> T
T == "new LoRA adapter (few MB, flyte.Dir)" ==> D
D -. "attached next iteration via LoRARequest" .-> POOL
B -. "loaded once per replica" .-> POOL
B -. "downloaded per step" .-> T
classDef warm fill:#fde68a,stroke:#b45309,stroke-width:2px,color:#1a1a2e;
classDef ephem fill:#e0f2fe,stroke:#0369a1,color:#1a1a2e;
classDef store fill:#ede9fe,stroke:#6d28d9,color:#1a1a2e;
class R1,R2,R3 warm;
class D,S,T ephem;
class P,B store;
style POOL fill:#fffbeb,stroke:#b45309,stroke-width:3px;
🔥 marks the warm pool, reused across iterations via flyte.ReusePolicy. ❄ marks ephemeral environments that get a new container per call. In the validated run, the generate actions ran as Flyte actor tasks (the warm pool), while init_adapter, score_group, and train_step ran as ordinary python pods.
Getting started
Once Union and the Flyte SDK are installed, running this is a single command. You will need:
- A Union deployment with GPU capacity. The example uses
L4:1, and any single modern GPU is enough for a small model. - A Hugging Face token stored as a Union secret. The example reads a secret named
hf-token. Create it withflyte create secret hf-token, or point theHF_SECRETin the code at an existing one. - The Flyte SDK pointed at your endpoint via
flyte create config.
Then run:
python rl_grpo_lora.pyThat prefetches the base model and launches the training loop. The very first run also builds the container image (vLLM, flashinfer, and PEFT), which takes a few minutes. Every run after that reuses the image, so you go straight into training.
The image and environments
A single image backs every environment. It is built explicitly rather than from the uv script header so it can pull vLLM’s flashinfer kernels as precompiled cubin wheels. Without them, vLLM tries to JIT-compile attention at runtime and fails because there is no CUDA toolkit in the base image. The unionai-reuse package provides the actor bridge that the reusable rollout environment needs. The module top level only imports flyte and pydantic, while torch, vLLM, transformers, and PEFT are imported lazily inside the GPU tasks.
image = (
flyte.Image.from_debian_base(name="rl-grpo-lora")
.with_pip_packages("flashinfer-python", "flashinfer-cubin")
.with_pip_packages("flashinfer-jit-cache", index_url="https://flashinfer.ai/whl/cu129")
.with_pip_packages(
"vllm==0.11.0",
"transformers==4.57.6",
"peft>=0.13.0",
"accelerate>=0.34.0",
"unionai-reuse>=0.1.3",
"async-lru>=2.0.0",
)
)
The rollout generator is the one reusable environment. reusable=flyte.ReusePolicy(...) is what holds the warm replicas between calls. concurrency=1 is set because a single in-process vLLM engine batches internally and is not safe to drive from several coroutines at once. The driver still pipelines by fanning generate() calls across replicas, and replicas=(1, 4) lets the pool autoscale from one replica when idle up to four under load.
rollout_env = flyte.TaskEnvironment(
name="rl-grpo-rollout",
image=image,
resources=flyte.Resources(cpu=4, memory="24Gi", gpu=flyte.GPU("L4", 1), shm="auto"),
reusable=flyte.ReusePolicy(replicas=(1, 4), concurrency=1, idle_ttl=300, scaledown_ttl=120),
secrets=[HF_SECRET],
env_vars={"VLLM_USE_V1": "1"},
)
The reward environment is cheap CPU only:
reward_env = flyte.TaskEnvironment(
name="rl-grpo-reward",
image=image,
resources=flyte.Resources(cpu=1, memory="2Gi"),
)
The trainer is a single node with one GPU, which is plenty for a 0.6B base plus a LoRA adapter:
train_env = flyte.TaskEnvironment(
name="rl-grpo-train",
image=image,
resources=flyte.Resources(cpu=4, memory="24Gi", gpu=flyte.GPU("L4", 1), shm="auto"),
secrets=[HF_SECRET],
)
The driver does plain async orchestration with no GPU of its own. It invokes tasks in the rollout, reward, and train environments, so it declares them through depends_on. That registers their images and environments alongside the driver’s when the run is created.
driver_env = flyte.TaskEnvironment(
name="rl-grpo-driver",
image=image,
resources=flyte.Resources(cpu=1, memory="2Gi"),
depends_on=[rollout_env, reward_env, train_env],
)
The model weights: prefetch once
Both vLLM (the generator) and Transformers with PEFT (the trainer) need the base model’s weights. Rather than have every task pull from Hugging Face, Flyte prefetches once into object storage and hands the resulting directory to the tasks as a flyte.io.Dir. This happens in the script’s entry point, which prefetches the model, then launches the driver with the resulting directory:
if __name__ == "__main__":
import flyte.prefetch
flyte.init_from_config()
# Prefetch the base ONCE into the Flyte object store as plain HF weights (see module docstring for
# why we do not vLLM-shard for this single-GPU MVP). hf_model returns a Run; its sole output is the
# model Dir, which we pass straight into the driver task as a flyte.io.Dir.
run = flyte.prefetch.hf_model(repo=BASE_MODEL_REPO, hf_token_key="hf-token")
run.wait()
print(f"Prefetched base model: {run.url}")
# hf_model's sole output is the model Dir. run.outputs() may be sync or awaitable depending on the
# SDK build, so handle both. The result is an ActionOutputs tuple; element 0 is the base Dir.
import inspect
outputs = run.outputs()
if inspect.isawaitable(outputs):
outputs = asyncio.run(outputs)
base_dir = outputs[0]
rl_run = flyte.run(train_rl, base=base_dir, num_iterations=NUM_ITERATIONS)
print(rl_run.url)
rl_run.wait()
hf_model can pre-shard weights for vLLM, but that layout is not readable by the Transformers and PEFT trainer. On a single GPU (tensor_parallel_size=1), vLLM loads plain Hugging Face weights directly with no downside, so the example prefetches plain weights and shares one directory between the generator and the trainer. Pre-sharding only pays off for multi-GPU rollout replicas, in which case you need a separate copy for the trainer.
Walkthrough
Rollouts on a warm vLLM pool
This is the core technique, and where the warm pool earns its keep. The expensive per-replica work, building the engine and downloading each adapter, is wrapped in @alru_cache, so it runs once and is reused for every call that replica handles. The caches are keyed on the remote URI string (which is hashable) rather than on the flyte.io.Dir object.
@alru_cache(maxsize=1)
async def _load_engine(base_uri: str) -> Any:
"""Build the vLLM engine once per warm replica (cached); the frozen base stays resident in GPU."""
from vllm import LLM
local_base: str = await flyte.io.Dir.from_existing_remote(base_uri).download() # plain-HF base
logger.info("Building warm vLLM engine from %s", local_base)
return LLM(
model=local_base,
enable_lora=True,
max_lora_rank=LORA_RANK,
max_loras=1,
trust_remote_code=True,
gpu_memory_utilization=0.85,
max_model_len=2048,
enforce_eager=True, # skip CUDA-graph capture → faster cold start for an MVP
)
@alru_cache(maxsize=None)
async def _adapter_local_path(adapter_uri: str) -> str:
"""Download a LoRA adapter once per warm replica (cached by its remote URI → one download/version)."""
return await flyte.io.Dir.from_existing_remote(adapter_uri).download()
The generate task attaches the current adapter per request and returns a whole group of completions for one prompt, exactly the group GRPO needs to compute relative advantages:
@rollout_env.task
async def generate(
base: flyte.io.Dir,
question: str,
answer: str,
adapter: flyte.io.Dir,
version: int,
group_id: int,
) -> list[Rollout]:
"""Generate a GROUP_SIZE group of completions for one prompt, using the current LoRA adapter.
The frozen base loads exactly once per replica (cached ``_load_engine``); each adapter version is
downloaded once (cached ``_adapter_local_path``) and attached per request via ``LoRARequest`` — the
base weights in GPU memory are never touched.
"""
from vllm import SamplingParams
from vllm.lora.request import LoRARequest
engine: Any = await _load_engine(base.path)
adapter_path: str = await _adapter_local_path(adapter.path)
# lora_int_id must be >= 1 and unique per adapter; version starts at 0 so shift by 1.
lora: LoRARequest = LoRARequest(f"policy-v{version}", version + 1, adapter_path)
sampling: SamplingParams = SamplingParams(
n=GROUP_SIZE,
temperature=SAMPLING_TEMPERATURE,
top_p=1.0,
max_tokens=MAX_NEW_TOKENS,
)
prompt: str = build_prompt(question)
# vLLM's generate() is a blocking call, so we run it via asyncio.to_thread to keep it off the event
# loop — that lets the reusable replica's background actor heartbeat stay responsive while the GPU
# is busy. (We deliberately do not use flyte.extras.DynamicBatcher here: it batches many concurrent
# producers, whereas this env runs concurrency=1 and each call already submits a full group of
# GROUP_SIZE sequences as one vLLM batch.)
outputs: Any = await asyncio.to_thread(engine.generate, [prompt], sampling, lora_request=lora)
completions: list[str] = [o.text for o in outputs[0].outputs]
logger.info("group %s: generated %d completions (adapter v%d)", group_id, len(completions), version)
return [
Rollout(group_id=group_id, question=question, completion=c, answer=answer) for c in completions
]
A few details worth noticing:
@alru_cachedoes the warm-state caching declaratively._load_engine(maxsize=1) builds the vLLM engine the first time and returns the same instance forever after, and_adapter_local_pathdownloads each adapter version exactly once.enable_lora=Truereserves adapter slots when the engine starts, and the frozen base loads once.- Each call attaches the iteration’s adapter with
LoRARequest(name, id, path), and vLLM applies the low-rank update on the fly. The base in GPU memory is never touched, so swapping weights is just pointing at a new adapter directory with a new id. The id must be at least 1, which is why the code passesversion + 1. asyncio.to_threadruns vLLM’s blockinggenerate()off the event loop, so the reusable replica’s background heartbeat stays responsive while the GPU is busy. This is the standard way to call blocking code from an async task. The example does not reach forflyte.extras.DynamicBatcherhere, because that helps when many concurrent producers feed one GPU, whereas this environment runsconcurrency=1and each call already submits a full group as one vLLM batch.
Reward
The reward is a plain CPU task. The example uses a verifiable reward, a tiny arithmetic dataset where the answer can be checked exactly, because that is the cleanest way to watch RL actually working. The rule gives a small format bonus for emitting the answer marker and a larger bonus for the correct value:
def _extract_answer(text: str) -> str | None:
"""Pull the integer following the last '####' marker; fall back to the last integer in the text."""
import re
if "####" in text:
tail = text.rsplit("####", 1)[1]
m = re.search(r"-?\d+", tail)
if m:
return m.group(0)
nums = re.findall(r"-?\d+", text)
return nums[-1] if nums else None
def _reward(rollout: Rollout) -> float:
"""Verifiable reward: 1.0 for the correct answer, +0.2 format bonus for emitting the '####' marker."""
reward = 0.0
if "####" in rollout.completion:
reward += 0.2
predicted = _extract_answer(rollout.completion)
if predicted is not None and predicted == rollout.answer:
reward += 1.0
return reward
Scoring runs one task per prompt group rather than one task per rollout:
@reward_env.task
async def score_group(rollouts: list[Rollout]) -> list[float]:
"""Score a whole prompt group in one task — one reward task per group, not per rollout.
The rule-based reward is microseconds of pure-Python work, so a task *per rollout* would pay pod
startup over and over for trivial compute. Scoring at the group granularity (the unit `generate`
already returns) keeps reward an observable, pipelined task while cutting the pod count ~GROUP_SIZE×.
"""
return [_reward(r) for r in rollouts]
Why per group? The rule-based reward is microseconds of work, so a task per rollout would pay container startup over and over for trivial compute. With GROUP_SIZE=6 that is 24 tiny pods an iteration. Scoring at the group granularity, the unit generate already returns, keeps reward an observable, pipelined Flyte task while cutting the pod count by a factor of GROUP_SIZE.
A warm pool would not be the right fix here, because a pool amortizes expensive per-replica state like a model in GPU memory, and score_group has none. When the reward becomes model-based (an LLM-as-judge or a reward model), it gains that state, and then it should run on a warm vLLM pool, exactly like the generator. Picking the right tool per task is part of what Flyte makes easy.
Pipelining generation and reward
Instead of waiting for all rollouts before scoring (a barrier), the driver launches every rollout at once and scores each group the moment it finishes, so reward overlaps generation that is still in flight. This is plain asyncio: create_task to fan out, as_completed to drain, and gather to collect. Because each await generate(...) and score_group(...) is a Flyte task call, the overlap happens across containers, and Flyte spreads it over the warm pool’s autoscaled replicas. You can see this pattern inside the driver loop below.
The GRPO update
The trainer resumes the previous adapter (frozen base, trainable LoRA), computes group-relative advantages, takes one policy-gradient step, and saves the new adapter. The advantage helper is the GRPO formula from earlier, standardizing each reward against its prompt group:
def _group_normalized_advantages(rollouts: list[Rollout], rewards: list[float]) -> list[float]:
"""GRPO advantage: within each prompt group, ``(r - mean) / (std + eps)``."""
import statistics
from collections import defaultdict
by_group: dict[int, list[int]] = defaultdict(list)
for i, r in enumerate(rollouts):
by_group[r.group_id].append(i)
advantages = [0.0] * len(rollouts)
for idxs in by_group.values():
group_rewards = [rewards[i] for i in idxs]
mean = statistics.fmean(group_rewards)
std = statistics.pstdev(group_rewards) if len(group_rewards) > 1 else 0.0
for i in idxs:
advantages[i] = (rewards[i] - mean) / (std + 1e-4)
return advantages
The step itself loads the previous adapter as trainable, accumulates the policy-gradient loss across the batch, and takes a single optimizer step. save_pretrained on a PEFT model writes only adapter_config.json and adapter_model.safetensors, a few megabytes, and that directory is the entire trainer-to-generator handoff:
@train_env.task
async def train_step(
base: flyte.io.Dir,
rollouts: list[Rollout],
rewards: list[float],
adapter: flyte.io.Dir,
version: int,
) -> tuple[flyte.io.Dir, float, int]:
"""One GRPO policy-gradient step over externally-generated rollouts; trains the LoRA adapter only.
Resumes from the previous adapter (``PeftModel.from_pretrained(..., is_trainable=True)``), takes a
single optimizer step on the group-normalized policy-gradient loss, and ``save_pretrained()``s the
new adapter as a ``flyte.io.Dir``. See module docstring for why this is hand-rolled rather than TRL.
Returns ``(new_adapter, mean_loss, contributing)`` so the driver can chart loss in the report.
"""
import torch
import torch.nn.functional as F
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
device: str = "cuda" if torch.cuda.is_available() else "cpu"
local_base: str = await base.download()
local_adapter: str = await adapter.download()
tokenizer: Any = AutoTokenizer.from_pretrained(local_base, trust_remote_code=True)
base_model: Any = AutoModelForCausalLM.from_pretrained(
local_base, torch_dtype=torch.bfloat16, trust_remote_code=True
).to(device)
# Resume the trainable adapter from the previous version (frozen base, only A/B train).
model: Any = PeftModel.from_pretrained(base_model, local_adapter, is_trainable=True).to(device)
model.train()
advantages: list[float] = _group_normalized_advantages(rollouts, rewards)
optimizer: Any = torch.optim.AdamW((p for p in model.parameters() if p.requires_grad), lr=LEARNING_RATE)
optimizer.zero_grad()
total_loss: float = 0.0
contributing: int = 0
for rollout, advantage in zip(rollouts, advantages):
if advantage == 0.0:
continue # no learning signal (whole group scored identically)
prompt_text = build_prompt(rollout.question)
prompt_ids = tokenizer(prompt_text, return_tensors="pt").input_ids
full_ids = tokenizer(prompt_text + rollout.completion, return_tensors="pt").input_ids.to(device)
prompt_len = prompt_ids.shape[1]
if full_ids.shape[1] <= prompt_len:
continue # empty completion after tokenization
logits = model(full_ids).logits # (1, seq, vocab)
# log p(token_t | token_<t): align logits[:-1] with targets full_ids[1:]
log_probs = F.log_softmax(logits[:, :-1, :], dim=-1)
targets = full_ids[:, 1:]
token_log_probs = log_probs.gather(-1, targets.unsqueeze(-1)).squeeze(-1) # (1, seq-1)
# Mask to the completion tokens only (targets at positions >= prompt_len-1 in the shifted view).
completion_mask = torch.zeros_like(token_log_probs)
completion_mask[:, prompt_len - 1 :] = 1.0
seq_log_prob = (token_log_probs * completion_mask).sum() / completion_mask.sum().clamp(min=1.0)
loss = -advantage * seq_log_prob
loss.backward() # accumulate gradients across the batch, single optimizer step below
total_loss += float(loss.item())
contributing += 1
if contributing > 0:
torch.nn.utils.clip_grad_norm_((p for p in model.parameters() if p.requires_grad), 1.0)
optimizer.step()
logger.info(
"GRPO step v%d: %d/%d rollouts contributed, mean loss %.4f",
version,
contributing,
len(rollouts),
total_loss / contributing,
)
else:
logger.info("GRPO step v%d: no contributing rollouts (flat rewards); adapter unchanged", version)
out_dir = tempfile.mkdtemp(prefix=f"adapter-v{version}-")
model.save_pretrained(out_dir)
mean_loss = total_loss / contributing if contributing > 0 else 0.0
new_adapter = await flyte.io.Dir.from_local(out_dir)
return new_adapter, mean_loss, contributing
A library trainer like TRL’s GRPOTrainer owns the entire loop: it runs its own generation backend inside the trainer process and calls your reward as an in-process callback. That is convenient for a single self-contained job, but on Flyte it quietly undoes the three things this example is built around.
Generation moves inside the trainer, so you reload the model on the training GPU and sample on the same box that runs the gradient step, instead of fanning rollouts across a warm, autoscaling vLLM pool that already holds the base resident. Reward stops being a task, so it can no longer run on cheap CPU, overlap with in-flight rollouts through as_completed, or appear in the run with its own logs and lineage. And one process doing everything pins generation and training to a single pod, even though one wants many GPU replicas and the other wants one.
The cost of keeping them separate is the single explicit gradient step in train_step, which is a few lines of PyTorch. In exchange, generation, reward, and the update stay independently scaled, observable Flyte tasks, and the warm pool keeps paying off across every iteration.
The driver loop
The driver is a normal async task that owns the for loop. Each iteration it samples prompts, fans out rollouts on the warm pool, scores them as they finish, takes a GRPO step, then checkpoints loop state and publishes the report. A small set of helpers handles prompt rotation, the static report config, and re-rendering the report:
def _sample_prompts(iteration: int) -> list[tuple[str, str]]:
"""Deterministically rotate through the dataset so each iteration sees a different slice."""
start = (iteration * PROMPTS_PER_ITER) % len(DATASET)
return [DATASET[(start + i) % len(DATASET)] for i in range(PROMPTS_PER_ITER)]
def _report_config() -> dict[str, Any]:
"""Static run config surfaced in the report header."""
return dict(
base_model=BASE_MODEL_REPO,
num_iterations=NUM_ITERATIONS,
group_size=GROUP_SIZE,
prompts_per_iter=PROMPTS_PER_ITER,
lora_rank=LORA_RANK,
learning_rate=LEARNING_RATE,
)
async def _publish_report(history: list[IterationMetrics], status: str) -> None:
"""Re-render and flush the live GRPO progress report to the driver task's report tab."""
await flyte.report.replace.aio(
render_report(history, status=status, **_report_config()),
do_flush=True,
)
Here is the loop itself:
@driver_env.task(report=True)
async def train_rl(base: flyte.io.Dir, num_iterations: int = NUM_ITERATIONS) -> flyte.io.Dir:
"""Own the GRPO loop: fan out rollouts, score as they finish, take one GRPO step, repeat.
Loop state (iteration, current adapter, and the report history) is checkpointed each iteration so a
preempted driver resumes mid-run — including the accumulated report rows — instead of restarting.
Progress is published to a live HTML report (``report=True``) after every iteration.
"""
ctx = flyte.ctx()
cp = ctx.checkpoint if ctx is not None else None
start_iter = 0
adapter: flyte.io.Dir | None = None
adapter_version = 0
history: list[IterationMetrics] = []
# Resume from a prior driver attempt, if any.
if cp is not None:
prev = await cp.load()
if prev is not None:
state = json.loads(prev.read_text())
start_iter = state["iteration"] + 1
adapter_version = state["adapter_version"]
adapter = flyte.io.Dir.from_existing_remote(state["adapter_path"])
history = [IterationMetrics(**row) for row in state.get("history", [])]
logger.info("Resumed from checkpoint at iteration %d (adapter v%d)", start_iter, adapter_version)
# Cold start: mint a fresh LoRA adapter (version 0).
if adapter is None:
adapter = await init_adapter(base)
adapter_version = 0
await _publish_report(history, status="running")
for it in range(start_iter, num_iterations):
with flyte.group(f"iter-{it}"):
prompts = _sample_prompts(it)
# Launch every rollout group at once on the warm replicas.
rollout_futs = [
asyncio.create_task(generate(base, q, a, adapter, adapter_version, group_id=gid))
for gid, (q, a) in enumerate(prompts)
]
# Score each group the instant its rollout finishes — reward overlaps in-flight rollouts.
# One reward task per group (not per rollout): see score_group.
flat_rollouts: list[Rollout] = []
reward_futs: list[asyncio.Task[list[float]]] = []
for fut in asyncio.as_completed(rollout_futs):
group = await fut
flat_rollouts.extend(group)
reward_futs.append(asyncio.create_task(score_group(group)))
group_rewards = await asyncio.gather(*reward_futs) # aligned with append order
rewards = [r for gr in group_rewards for r in gr] # flatten → aligned with flat_rollouts
mean_reward = sum(rewards) / len(rewards) if rewards else 0.0
logger.info("iter %d: %d rollouts, mean reward %.3f", it, len(rewards), mean_reward)
# One GRPO step → next adapter version.
new_version = adapter_version + 1
adapter, mean_loss, contributing = await train_step(
base, flat_rollouts, rewards, adapter, new_version
)
adapter_version = new_version
# Record metrics for the report (accuracy/format derived directly from the rollouts).
n = len(flat_rollouts)
correct = sum(1 for r in flat_rollouts if _extract_answer(r.completion) == r.answer)
formatted = sum(1 for r in flat_rollouts if "####" in r.completion)
best_idx = max(range(n), key=lambda i: rewards[i]) if n else None
history.append(
IterationMetrics(
iteration=it,
adapter_version=adapter_version,
num_rollouts=n,
mean_reward=mean_reward,
max_reward=max(rewards) if rewards else 0.0,
accuracy=correct / n if n else 0.0,
format_rate=formatted / n if n else 0.0,
mean_loss=mean_loss,
contributing=contributing,
sample_question=flat_rollouts[best_idx].question if best_idx is not None else "",
sample_completion=flat_rollouts[best_idx].completion if best_idx is not None else "",
sample_reward=rewards[best_idx] if best_idx is not None else 0.0,
)
)
await _publish_report(history, status="running")
# Persist loop state so a preempted driver resumes here (with its report history).
if cp is not None:
state = {
"iteration": it,
"adapter_version": adapter_version,
"adapter_path": adapter.path,
"history": [vars(m) for m in history],
}
await cp.save(json.dumps(state).encode())
await _publish_report(history, status="complete")
assert adapter is not None
return adapter
This is where Flyte’s reliability shows up with almost no code:
flyte.Checkpointpersists the iteration number, the adapter location, and the report history each step. If the driver is preempted by a spot reclaim or an OOM, it resumes mid-run instead of starting over.flyte.group("iter-N")nests each iteration’s tasks in the UI so the DAG stays readable.- The fan-out and scoring use
asyncio.create_taskwithasyncio.as_completed, so reward overlaps in-flight generation across the warm pool, with one reward task per group.
The live report
report=True on the driver, together with the dependency-free toolkit in
report_helpers.py, gives you a self-contained HTML report that is re-published every iteration. It charts reward, accuracy, format rate, and loss, shows a per-iteration table, and surfaces the best sample completion. It is pure Python with inline SVG and no plotting dependency, so the CPU driver stays light. Open it from the run’s Report tab in the Union UI and watch training move in real time.
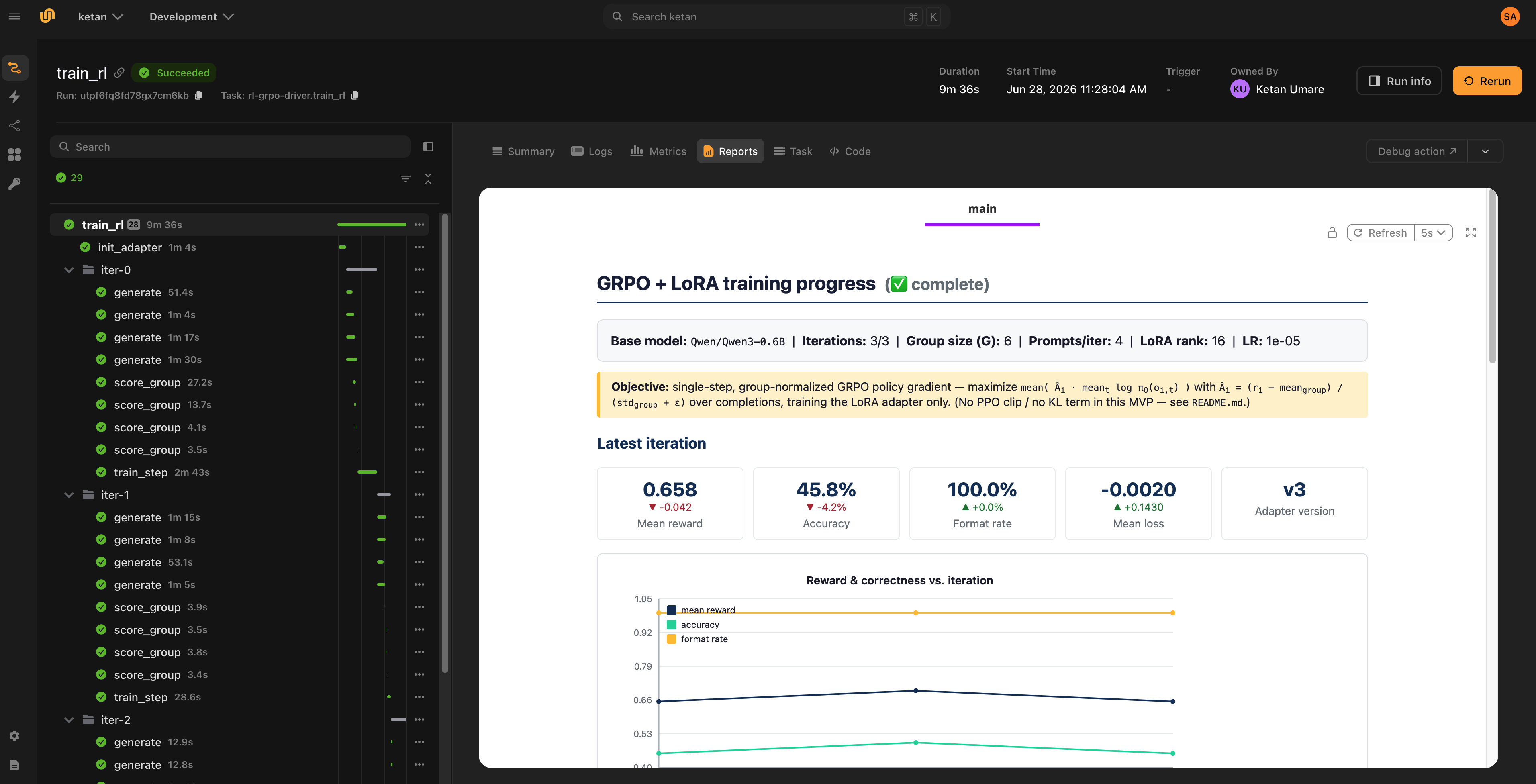
What this validates
Running python rl_grpo_lora.py against a Union cluster (Qwen3-0.6B, L4 GPUs, three GRPO iterations) exercises the whole loop on real hardware:
- prefetch, then
init_adapter, then 12 warm-vLLM rollouts (4 prompts × 3 iterations), then 12 group reward tasks, then 3 GRPO steps, then a final LoRA adapter (v3) returned as aflyte.io.Dir, - with the live report published each iteration, the driver checkpointing per step, and the rollout tasks running as warm, autoscaled
actorreplicas.
With a 0.6B model and a toy dataset, this proves the machinery rather than convergence. Scale the model and dataset for a real learning signal.
Going further
The example is deliberately the smallest thing that runs end to end. Because it is all plain Flyte, each of these is a small change rather than a rewrite:
- A real task and a bigger policy. Swap
BASE_MODEL_REPOandDATASETfor a larger model and a real verifiable-reward dataset (math, code, or tool use). The loop code is unchanged. - Model-based reward. Replace the rule in
score_groupwith a call to a second warm vLLM environment (an LLM judge), the same warm-pool pattern as the generator. - Multi-GPU rollouts. Raise
tensor_parallel_sizeand prefetch a vLLM-sharded copy for the generator, keeping a plain copy for the trainer. - Multi-node training. When the policy outgrows one GPU, move
train_stepto a clustered task environment withTorchRun. The body stays nearly the same. - Full-weight RL. If LoRA capacity is not enough, train all parameters and hand off the full model directory instead of an adapter.
- Serving the result. Merge the final adapter into the base with
merge_and_unload()and serve it with a vLLM app environment. - The full GRPO objective. Add the PPO-style clipped ratio and a KL penalty against a reference model for stability over many steps.
An RL training loop, with warm GPU pools, CPU reward fan-out, a resumable driver, and live reporting, usually means standing up and operating a distributed system. On Flyte with Union it is a handful of decorated Python functions that autoscale to your hardware and stay isolated per run. Start with this small example, then scale the model, the reward, and the hardware without changing the shape of your code.