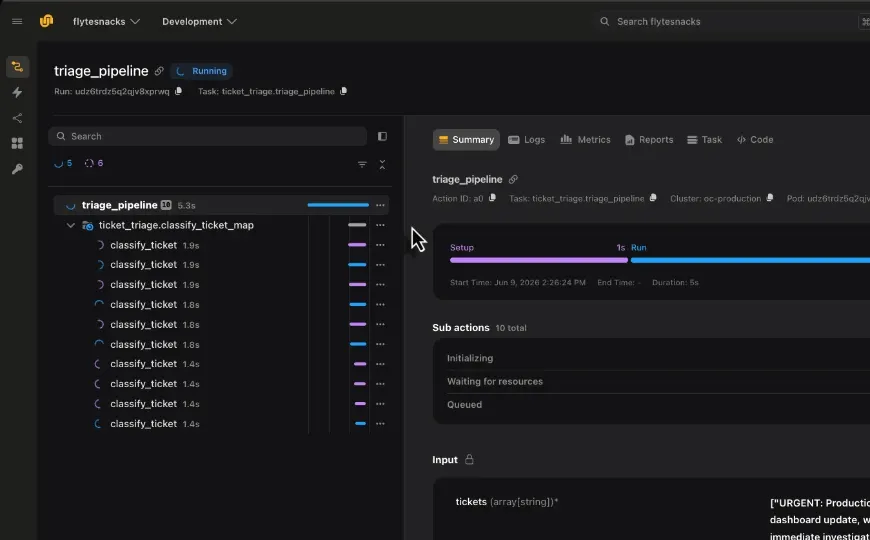
Introduction
In a previous post we highlighted the need for reproducibility in AI development, and explored some of the challenges of achieving this in contemporary AI stacks. From a technological perspective, these challenges are driven by the need to integrate data, models, and specialized infrastructure into the development lifecycle. Non-technical factors like siloed teams, differing incentives across teams, and the interdisciplinary nature of AI development also play a role.
This blog provides a framework for thinking about AI reproducibility in the context of these challenges. It also evaluates the benefits and costs of some common tools used by practitioners to improve reproducibility, such as containerization, experiment tracking, data versioning, and orchestration.
The AI Development Lifecycle can be Modeled as a Workflow
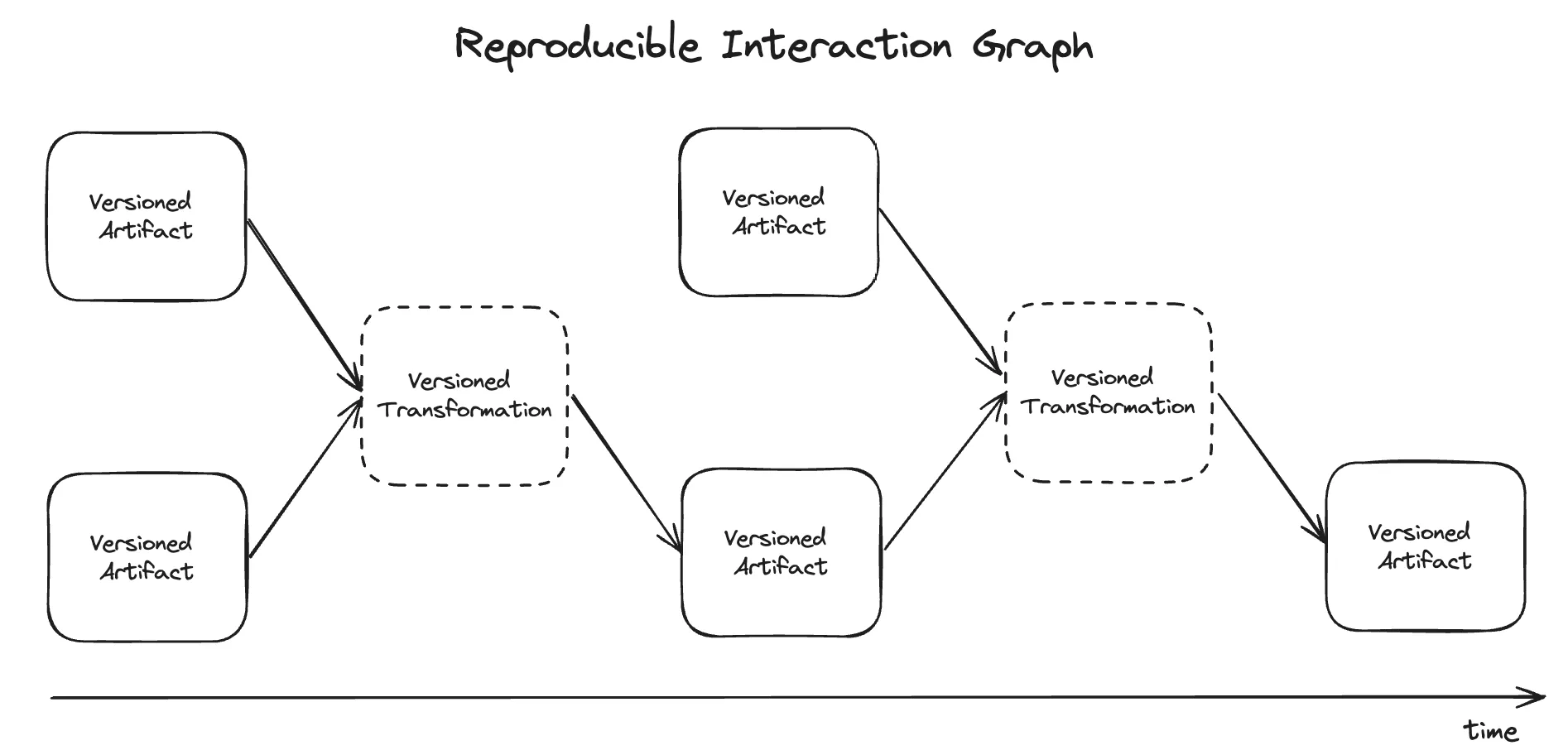
At a high level, the AI development process can be thought of as an interaction graph between artifacts (data and models) and transformations (compute-based operations) on those artifacts. Consider these examples:
- ETL workflows often start with raw data artifacts collected from some business process, then perform transformations to validate, clean, enrich, and organize the data for downstream consumption.
- Model training workflows might aggregate many such cleaned data artifacts as inputs, then perform model training or hyperparameter tuning, which effectively transforms these data inputs into trained models.
- Model validation workflows run batch inference on candidate models to generate test predictions, then compare performance against the current best models.
- Inference workflows such as RAG take a user’s query as an input, enrich the query by fetching additional information from a vector database, call one or more LLMs to generate a result, then further process the result before returning it to the user.
In contemporary systems, each of these workflows uses different tooling, and can be costly to run multiple times. Worse, changes in the data sets and execution environments between runs may yield differing results. However, if we look at their common traits, a series of transformations over artifacts, we can see where both reproducibility and efficiency can be improved.
Principles of a Reproducible AI System
Reproducibility implies that teams are able to recreate all the intermediate results obtained during the execution of these workflows. Because we can break down all the steps of the AI development process to artifacts (such as input data, trained models, model outputs, vector databases, etc) and transformations (data ETL, model training, model inference, etc), we can reduce reproducibility problem down to a few principles:
Artifact immutability: the data, models, and other artifacts that mark discrete “steps” in a workflow should be immutable and versioned. Once a daily run of an ETL process creates a data artifact, it shouldn’t be possible to overwrite the resulting data. Instead, re-running the job should produce a new version of the data artifact.
Transformation immutability: the compute operations that take place on artifacts and form the edges of the workflow graph should also be immutable and versioned. Transformation definitions should comprise input and output artifacts, code logic, environment specification (such as dependencies), and infrastructure requirements.
Transformation determinism: Immutable, deterministic transformations guarantee that re-running the same transformation on the same inputs produces the same result every time. Note that in emerging applications such as multi-agent frameworks, transformation immutability may not be possible to achieve due to the nondeterministic nature of LLMs and other AI models. We will save this discussion for the future.
Completeness and accessibility: the graph of all artifacts and transformations performed in an organization should be persisted in order to make it possible to recreate historical state. It should be possible to re-hydrate any node in the graph with its inputs, recreate the environment and infrastructure associated with a given transformation, rerun the execution, and produce the same results.
The below graphic shows these principles in action for a daily ETL process:

Common Reproducibility Best Practices
Mature AI organizations have adopted several best practices to bring reproducibility into their AI development processes. These include containerization, experiment tracking, data management, and AI orchestration.
Containerization and Container Orchestration
Containerized apps allow developers to create portable, fully-specified logic blocks that make it easier to deal with configuration and infrastructure differences between local and remote environments. In the realm of AI, containerized processes enable teams to manage the multitude of different dependencies leveraged across the AI stack. Containers also enable infrastructure, such as GPUs, to be associated with specific compute operations that require them.
Containerization has some drawbacks. Most pertinently, containers are tedious to create and manage. Users need to build images, upload them to a registry, and keep them current. In AI development, the infrastructure, code logic, and dependencies often change much more frequently than in software development because practitioners are constantly experimenting. This accentuates the overhead of container management. Containers and container orchestration systems like Kubernetes are also not necessarily built to handle large data. Unless teams have provisioned specialty infrastructure (such as attached volumes for fast data reads), data needs to be downloaded into the pod before the computation can start, which can slow down velocity.
Because a container can contain a complete specification of the transformations and compute operations to be performed, the benefits of containerization for reproducibility are significant. However, the real-world costs of container management sometimes mean that users prefer to experiment outside of the containerized ecosystem. In this case, containerization is integrated only when models are being brought into production, which is a large part of the reason why ML engineers spend so much time rewriting code. In order to get the reproducibility benefits of containerization, there needs to be wide adoption across the various AI practitioners in an organization. Some tools, like Flyte and Union, seek to make this possible through abstractions like ImageSpec that make it much easier to deal with containers.
Experiment Tracking
The experimental nature of AI development means that practitioners are constantly training and testing new models to try to improve performance. Training is highly complex, with many configurable parameters that influence the quality of the resulting model. To help manage this, AI practitioners use experiment tracking tools such as Weights & Biases and MLFlow to log data about experimental training runs. Practitioners also use these tools to store outputs of training runs in model registries, which encapsulate metadata about the infrastructure, environment, and training metrics associated with each run.
However, experiment tracking tools have the drawback of not actually controlling the runtime that performs the compute operations they are tracking. It’s possible to log metrics from any experimental run, regardless of whether that run is reproducible. Also, because these tools focus on model ops, they are not deeply integrated with the rest of the AI lifecycle (such as data processing). Thus, while experiment tracking tools are a critical component of any reproducible AI solution, they do not by themselves provide end-to-end reproducibility.
Data management
Organizations have been dealing with big data for a long time, and there are many solutions geared towards offering reproducibility through versioned datasets. Data Version Control (DVC) is a popular open-source tool that allows users to integrate large datasets into their GitOps system. Adopting a tool like DVC as part of the AI development process can enhance reproducibility by enabling users to mark specific datasets as dependencies for a given bit of code logic. When combined with containerization, this approach can guarantee that computational jobs are operating on the same data, and can give users visibility into how that data has changed over time.
The drawback of standardizing on a system such as DVC is that AI practitioners now need to think very explicitly about data. Users must learn DVC commands and concepts, which can add overhead, especially for teams already juggling multiple tools. Also, while the integration with Git is the core reason to use the tool, it also means projects must be structured around Git repositories, which may not suit all workflows or environments. Thus while versioned data inputs and outputs are critical for reproducibility, current best-of-class tools for versioning datasets, such as DVC, have some overheads and don’t perfectly extend to the world of AI development.
AI Workflow Orchestrators
As organizations have stretched to accommodate the demands posed by AI development, a new breed of AI-centric workflow orchestrators such as Flyte and Kubeflow have emerged to facilitate AI development on top of Kubernetes. These systems extend Kubernetes by allowing users to stitch containerized steps together in a structured way to match AI development workflows. Because everything runs in containers, the code logic, dependencies, and infrastructure are encapsulated in each logical workflow step, which supports reproducibility.
AI orchestrators are different from traditional data orchestrators like Airflow and Dagster because they directly manage infrastructure and provide integrated compute capabilities. It is therefore possible to run jobs using many popular open-source frameworks for distributed computation, including Spark, Ray, PyTorch, and Tensorflow. Because compute is natively provided by the system, reproducibility is a step closer because there is not a need to integrate between a version control system and a compute platform. Additionally, being container-native enables users to develop new pipelines in isolation, without the burden of managing shared dependencies as is the case with Airflow.
The main drawback of Kubernetes-native open-source tools is that you or someone in your company needs some expertise in Kubernetes and infrastructure in order to set up these systems. The main difference between Flyte and Kubeflow is the extent to which you need specialized Kubernetes knowledge to author workflows. Another consideration when thinking about adopting a container-centric approach is the aforementioned friction associated with container management.
Reproducibility Principles vs Best Practices
{{reproducible-ai="/blog-component-assets"}}
As the above table shows, each of the best practices has some benefits and drawbacks with respect to reproducibility. Containerization alone, while important for reproducibility, is insufficient for dealing with data, and may not be widely adopted due to the overhead associated with image management. Experiment tracking is great for MLOps, but often does not extend to data, and doesn’t guarantee transformation immutability. Data version control systems are largely unaware of transformations, and typically do not extend to model artifacts.
Container-native AI orchestrators are capable of both artifact immutability (through strongly typed, versioned inputs and outputs) and transformation immutability (through containerization), and therefore offer a potentially strong foundation for AI reproducibility. While these powerful tools can be technically complex to set up, the organization-wide benefit of reproducibility is often worth the investment.
Conclusion
In this post we expanded on the importance of AI reproducibility, describing the essential features of a reproducible AI development environment, and exploring some of the best practices currently in use. A successful solution must have artifact immutability, transformation immutability and determinism, and be integrated and accessible throughout all stages of development. To accomplish this, successful AI development organizations use containerization, experiment tracking, data management, and orchestration tools.
The next post in this series dives into Flyte, one of the most popular container-native workflow orchestrators and the engine that powers Union. We will explore how Flyte enables Union to deliver reproducibility for AI workflows while prioritizing developer experience and iteration velocity.
Disclaimer: The creators of the Flyte open-source project founded Union, which continues to heavily support the development of Flyte.