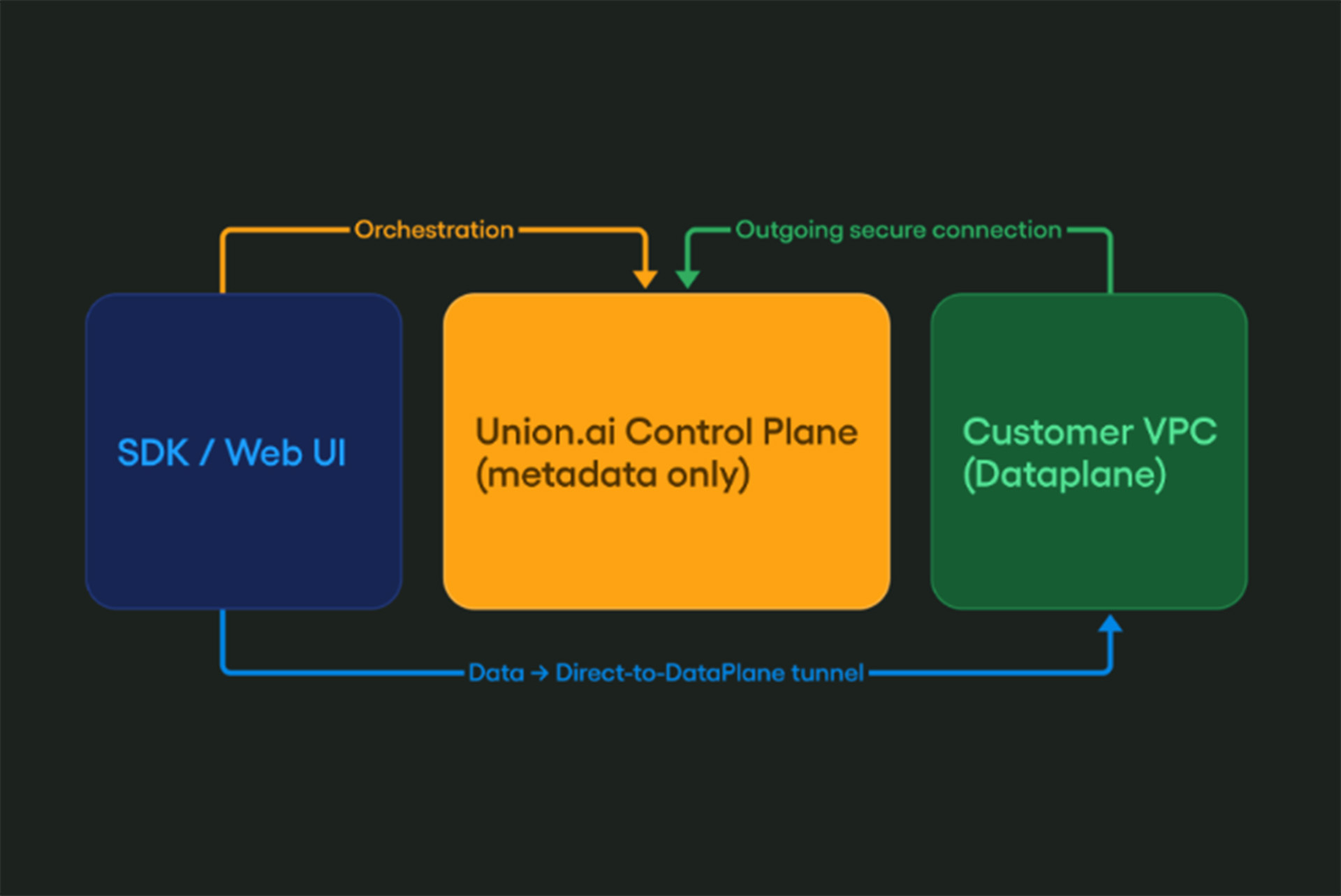
At Union.ai, our philosophy is simple: provide you with every tool needed to unlock maximum value from your AI infrastructure. With our recent launch of the Union.ai serving feature, we’re doubling down on that promise — making it effortless to serve in real time and productionize your apps and models so you can focus on what really matters: driving business impact.
Our partnership with Weights & Biases shares this vision. Their developer tools are truly exceptional, and our existing integration with their W&B Models MLOps platform is already a favorite among our customers for accelerating experiment velocity and productionizing ML models. Now, with the W&B Weave integration, you can evaluate, iterate, monitor, and guardrail AI applications and agents, closing the loop on the full lifecycle from model training to production-ready AI.
Union.ai handles implementation, serving, and scaling of compound AI systems, while Weave provides the critical observability and governance layers to productionize AI-powered workflows. Together, they form a robust ecosystem that makes Retrieval Augmented Generation (RAG) not just possible, but easy for building robust, reliable AI applications and agents.
Let's explore how!
Using RAG to search Airbnb listings like a human would
Let’s assume you have Airbnb listing data available. We’ll build a RAG app that can handle natural language queries like:
“Show me properties in Centrum-Oost, Amsterdam priced between $150 and $300 with a review score above 4.5.”
You’ll see how to wire this up with a FastAPI endpoint, and how Weave gives you full visibility into what’s happening under the hood.
We start by defining a `lifespan` function to handle all initialization logic. This includes setting up the Weave project with `weave.init`, along with Weave’s pre-built hallucination and context relevancy scorers to establish guardrails for model responses.
The model serving the final RAG responses can be self-hosted on Union.ai, no need to rely on external providers. This keeps everything on your infrastructure and unlocks native performance optimizations. For instance, the `stream_model` argument streams the model artifact directly to the GPU, bypassing disk I/O and dramatically reducing deployment time.
We define a standalone function for generating RAG responses and decorate it with `@weave.op` to enable tracing.
Under the hood, this uses LlamaIndex with Weaviate as the vector database. All Airbnb listings are embedded and stored in Weaviate, and we apply metadata filters during retrieval. With Weave tracing enabled, both inputs and outputs are automatically logged to the Weave dashboard, giving you full visibility into each call.
Next, we define an `App` using FastAPI and initialize `WeaveConfig` to connect it to the Weave dashboard. This includes specifying the entity, project, host, and API host, and once it's set up, a shareable link to the traces is available on the app page.

The FastAPI endpoint itself is decorated with `@weave.op`. It calls the RAG generation function and applies guardrails to the output. If the model’s response doesn’t meet the guardrail criteria, it’s filtered out, ensuring only reliable answers are returned.

The bottom line
By now, you’ve probably seen why adding observability to your models and apps really matters. With Weave, you don’t have to set anything up. It's simple to implement and gives you instant visibility into the inner workings of your app. While building this tutorial, I actually used the Weave dashboard myself to debug an incorrect response. It helped me trace the root cause easily, and if it helped me, I’m confident it’ll help you too.
On the Union.ai side, deploying an app is just as easy. Define your app spec, run the deploy command, and you're set. You can configure auto-scaling, set up secrets, tap into native optimizations, and, as I like to say, serve on your own terms. Having the ability to deploy any model or app with production-grade reliability, without managing Kubernetes, is a game changer. You get all the benefits without the operational overhead.
Union.ai Serving and Weave together make a powerful combination. It’s a step toward full transparency and control, so you can focus on building, not battling your infrastructure.
You can find detailed documentation on integrating Weave with Union.ai in the Union.ai docs. To learn more about Weave itself, refer to the Weave docs.
<div class="button-group is-center"><a class="button" href="https://www.union.ai/consultation">Book a free consultation</a></div>