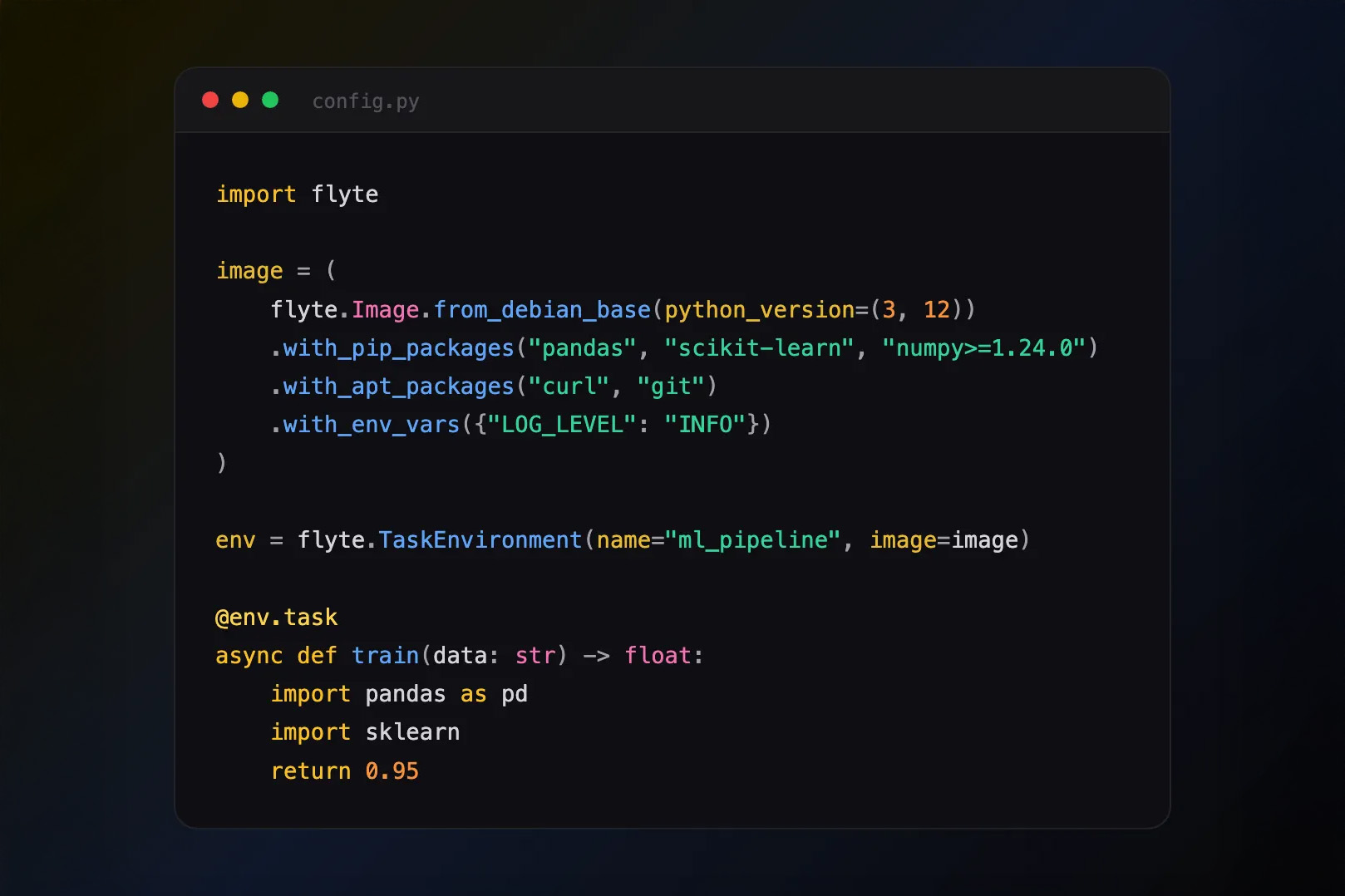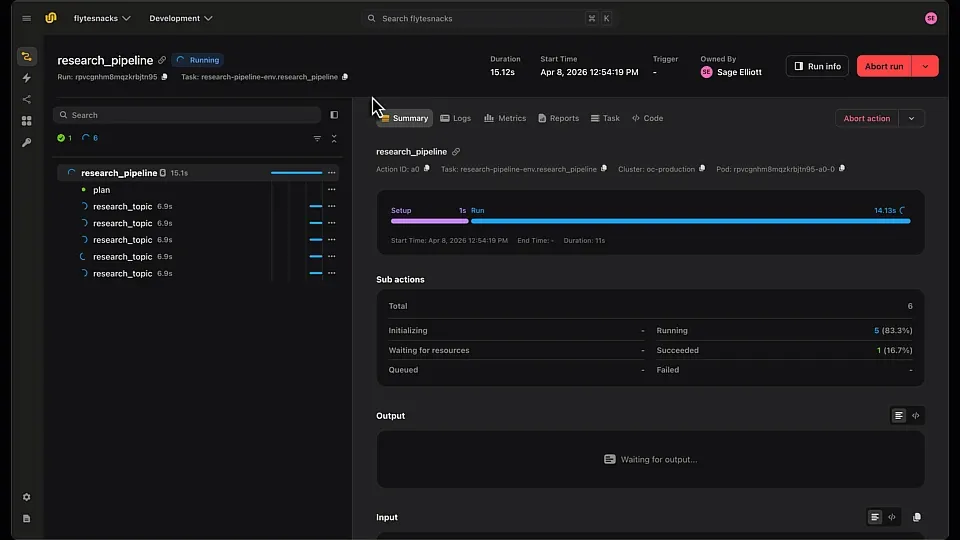
This is part 1 of a blog series on the need for end-to-end reproducibility in AI development.
In the Deep End
The recent explosion of interest in AI has sparked a surge of investment aimed at bringing the technology into virtually every consumer and business software product. At the same time, a wave of optimism has enabled AI products to venture into higher-stakes areas of the market. For example, driverless Waymo cars are now allowed to drive on major highways and AI-based cancer prediction products are moving through late-stage clinical trials. With the main context of AI shifting from internal and experimental use cases to production applications, the ability to reliably develop, ship, and iterate on AI products has never been more important.
In recent years, we saw how software reproducibility was a key factor behind the success of GitOps to increase development velocity. Reliable code versioning enabled modern CI/CD pipelines to ensure reproducible builds, which in turn enabled better debugging, reliable deployments, and more collaboration. This can be summed up in a single insight: reproducibility is key to increasing velocity.
The demand for more AI-based solutions is creating a similar need for reproducibility in AI workflows, but current systems are not well suited to the specialized needs of AI development. With its heavy dependency on large datasets and specialized computational resources, AI brings new challenges to reproducing workflows, especially in the areas of data versioning and resource allocation.
This and the following blog posts in this series make the case that AI reproducibility has a distinct set of needs as compared to traditional software development, and that reproducibility will be critical to achieve the velocity of development needed to meet the demands of the industry. We will also outline what we believe to be the necessary components of an AI-first development platform that can provide reliable reproducibility to this process.
The Technological Impact of Siloed Teams
In the past, data science applications were primarily internal-facing, with analysts using AI techniques to provide insights for the business. However, as AI has become more mainstream and is being embedded into products, multidisciplinary teams are required to take it into production. In particular, the domains of research and data science are often supported by existing teams specializing in managing infrastructure and building resilient software products. Software engineers, data engineers, ML engineers, and researchers therefore all need to work collaboratively to produce a business impact. However, specialization can create silos. Data engineering as a discipline has existed for far longer than ML engineering, and the tooling and best practices haven’t necessarily evolved to meet the needs of the researchers and ML engineers who depend on the downstream outputs of potentially unversioned data pipelines.
The priorities of teams can vary as well. Data scientists and statistical experts are primarily concerned with experimentation and feature engineering, creative work that blends art and science, and are generally not concerned with building containers, tracking dependencies, and versioning experimental runs. ML engineers, who rely on the output of both data engineers and data scientists, usually come from a software engineering background and are focused on testing, version control, predictable deployment, and infrastructure. ML engineers often need to rewrite code, integrate new dependencies, and deploy customized infrastructure in order to produce a resilient AI product.
Tooling Sprawl
In such a large stack, leveraging best of breed tooling (and the accumulated expertise of teams in using these tools) can raise the probability of success. Data engineers may use Spark for fast parallel processing in their data pipelines. Data scientists might use experiment tracking tools like Weights & Biases, MLFlow, and Tensorboard to log relevant metrics from training runs or models in production. Training a model might require the right versions of drivers, specialized hardware and networking, and distributed systems like MPI and Ray. Models sometimes need to be served offline—often running large-scale batch predictions, and in other instances must be served online with extremely low latency. The pace of the industry is evolving so rapidly, with new tools emerging to fit specific use cases, that it’s unreasonable to expect a single tool or vendor to emerge that meets everyone’s needs. Some of the hyperscaler solutions—SageMaker, Vertex AI, and Azure ML—offer products in each of these categories, but the surface area is so large that it is difficult to match the performance and user experience of best of breed tools. Platform lock-in may also present a problem for some stakeholders.
Given the AI lifecycle will likely leverage a range of point solutions for at least the medium term, reproducibility across the stack remains an extremely difficult problem to solve. A team leveraging Weights & Biases has visibility into the model artifacts produced by different training runs, but the ETL process that produced the data being consumed by those runs is invisible to that platform. Similarly, an ML engineering team using Ray for distributed training may want to recreate the training job, which might have used a cluster with specific parameters that needs to be manually spun up again. A Data Engineering team may want to rerun an old pipeline, but find they need to roll back one of their dependencies, something which is not possible in Airflow without changing the dependency for the whole environment.
Integrating and unifying these separate tools into a complete solution is a substantial problem in and of itself. The intersections of these solutions, with their differing paradigms, abstractions, and interfaces leads to fragile end-to-end experiences. This is where reproducibility often breaks down, and where AI development teams lose velocity.
Independently Managed Artifacts, Code, Infrastructure, & Configuration
In a large AI pipeline, which might comprise a parallel data processing step on multiple CPU nodes, followed by a model training step on one or more GPUs, the data inputs, model outputs, code logic, infrastructure, and environment configuration are intrinsically related to each other at each step of the pipeline. In order to reproduce such a complex process, each needs to be tracked in the context of the others. However, in many current AI development tools, the inputs (i.e. a database query), configuration (i.e. Python dependencies), infrastructure (i.e. a Kubernetes pod spec, GPUs, or MPI clusters), and code logic are each defined and maintained separately, possibly by different individuals. Even if these pieces of metadata are tracked, it can be difficult to tie them together as of a particular point in time.
Outside of Kubernetes, many alternative solutions for running data and AI workloads (such as Databricks and Snowflake) assume that engineers have access to one or more long-running clusters, the configuration of which is done out of band and cannot be reproduced on the fly. Even if a team is using ephemeral clusters, the configuration and lifecycle management of these clusters is done independently of the jobs that are sent. In addition to the challenge of tracking state across platforms, AI practitioners need to manage things like Terraform code or write custom API calls to spin up and tear down compute resources.
Lack of Unified Best Practices
The best practices that evolved in the software engineering world such as GitOps and containerization, which enable collaborative development and resiliency, haven’t yet been fully adopted by the AI world. This is partly because AI presents a much harder problem, involving more data, infrastructure, and configuration than relatively lightweight code artifacts. AI practitioners’ backgrounds also vary considerably, with many fields—particularly the traditional sciences—converging across the AI stack. It’s often not immediately clear to a genetics researcher or data scientist that the extra overhead of checking in code, using strong typing, and building images is worth the effort. To address this, any solution offering a standardized way to enforce best practices across all of the disparate teams and tooling not only needs to solve the reproducibility problem—it needs to offer a user experience that is so good as to make the effort of changing behaviors worthwhile.
Conclusion
Achieving end-to-end reproducibility in AI development is imperative for the sustainability and reliability of AI systems. As AI continues to permeate every facet of consumer and business technology, the stakes for ensuring accurate, consistent, and explainable AI behavior have never been higher. The challenges of fragmented teams, diverse tooling, and the intrinsic complexity of AI workflows demand a concerted effort to standardize practices and foster collaboration across disciplines. Future posts in this series will explore AI reproducibility from first principles, explore potential solutions, and recommend an approach for achieving end-to-end reproducibility across the AI stack.