

2021 was a fantastic year for Flyte — 100+ features and 20+ integrations were added, 1000+ community members joined us, production deployments across the globe grew ten-fold, integrations paved the way for greater adoption, and the number of use cases that Flyte could solve skyrocketed!
I’m extremely stoked about the community we built as we progressed through 2021. Most importantly, Flyte has become one of the most helpful and inclusive communities I am proud to be a part of.
Early 2021, I left Lyft and started a company called Union (more on this soon: stay tuned!), where we are committed to making Flyte the de-facto open-source machine learning orchestration platform.
A couple of weeks ago, Flyte started a new chapter. The project was unanimously voted by the Linux Foundation AI & Data community to be promoted from an Incubation to a GRADUATE PROJECT.
An uptick in Flyte’s designation means that we will work much harder to make it all the more user-friendly and reliable. 2021 was focused on getting the basics right. In 2022, we want to use the launchpad that has been created to reach thousands of users and increase Flyte’s adoption in several industries, enhance existing features, add new ones, and delight users of Flyte the world over!
Before we dive into what’s in store for 2022, let’s look at some crucial properties and design decisions of Flyte.
Workflow Engine vs. Workflow Automation Platform
Workflows are extremely common in most software engineering systems. Workflows refer to a sequence of activities that should be performed in a prescribed order to ensure that the completed tasks are not repeated. They are, essentially, complex distributed systems that are usually used to achieve resilience in the face of failures.
Machine Learning and data pipelines are two of the most common applications of workflows. For ML, workflow automation has become crucial and hence, is a defining tool for most MLOps stacks. While we understand workflows are critical to capture the business logic that goes into building ML Applications, it’s hard to miss the complex infrastructure that needs to be set up to support the use cases.
Workflows are distributed systems, and ML code is usually authored by practitioners who do not have in-depth knowledge about distributed systems (on a side note, I would argue that they should not need to!). Some critical requirements for ML Workflows are outlined below:
- Ability to run ad hoc experiments and potentially, multiple versions concurrently (e.g., various data scientists may work on the same algorithm concurrently)
- Ability to repeatedly and deterministically produce results; sometimes, the need for reproducibility is critical for a business (healthcare, biotech, transportation, financial systems)
- Ability to collaborate with others within the organization and share data and the authored workflows/tasks
- Abstraction of infrastructure and reduction in boilerplate as we move from experimentation to production
- Integrations with disparate systems and external data sources
Thus, a traditional workflow engine model does not work for ML. We need more than a workflow engine, essentially, a workflow automation platform that:
- Is multi-tenant
- Manages concurrent workflows
- Helps with reproducibility and version management
- Connects to external resources using best practices, and
- Scales well
Flyte is an outstanding solution for such cases. It helps build manageable pipelines which can scale to millions of executions and containers. Flyte exemplifies the concept of “Event Sourcing”. Martin Flower described Event Sourcing as follows:
“Event Sourcing ensures that all changes to application state are stored as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.” – Martin Fowler (Dec 12, 2005)
Event sourcing drives the main essence of Flyte. Every user-triggered activity is captured as an event and logged. Every workflow in Flyte is versioned, which enables roll back to the past executions. There’s a record of every activity that happens with a Flyte entity, which helps to provide full details of every workflow.
Overall, Flyte keeps track of how an execution progressed rather than simply retaining the final result. It tracks the code and configuration used for execution, and thus, reconstruction of the past can be achieved almost perfectly!
Static Graphs with Controlled Dynamism
When we started Flyte, we wanted every workflow and task to be like a package that captures business logic and infrastructure. A remarkable effect of this packaging structure is that every workflow and task is inherently shareable!
This facilitated the creation of static graphs within Flyte, which typically depict what the workflow looks like, and the dependencies between tasks in a workflow before the execution commences. Static graphs can be reproduced at any time without external infra help and are shareable.
However, business is not really static. There are cases where you may want to adapt your workflow in response to external inputs. For example, you may want to train a model on certain regions based on the time of the day or dynamically add new regions as and when a service is launched. It is entirely possible to construct dynamic graphs (in other systems) but this comes at the cost of the shareability and reproducibility of static graphs. Flyte is one of the only workflow-engines-of-its-kind that generates dynamic graphs with the same properties as static graphs.
These can be compared to higher-level languages like JAVA, which perform JITing to create fast dynamic execution graphs. Thus, the dynamically-generated graphs are compiled, preventing late caught errors abound in a fully-dynamic system. It also allows the system to remain fully serverless for the user.
Static graphs can be assumed to be similar to compiled languages, which can improve performance by introducing both compile-time and runtime optimizations. This feature of Flyte is something we are extremely excited about. If you want to help us improve this feature, please join our community.
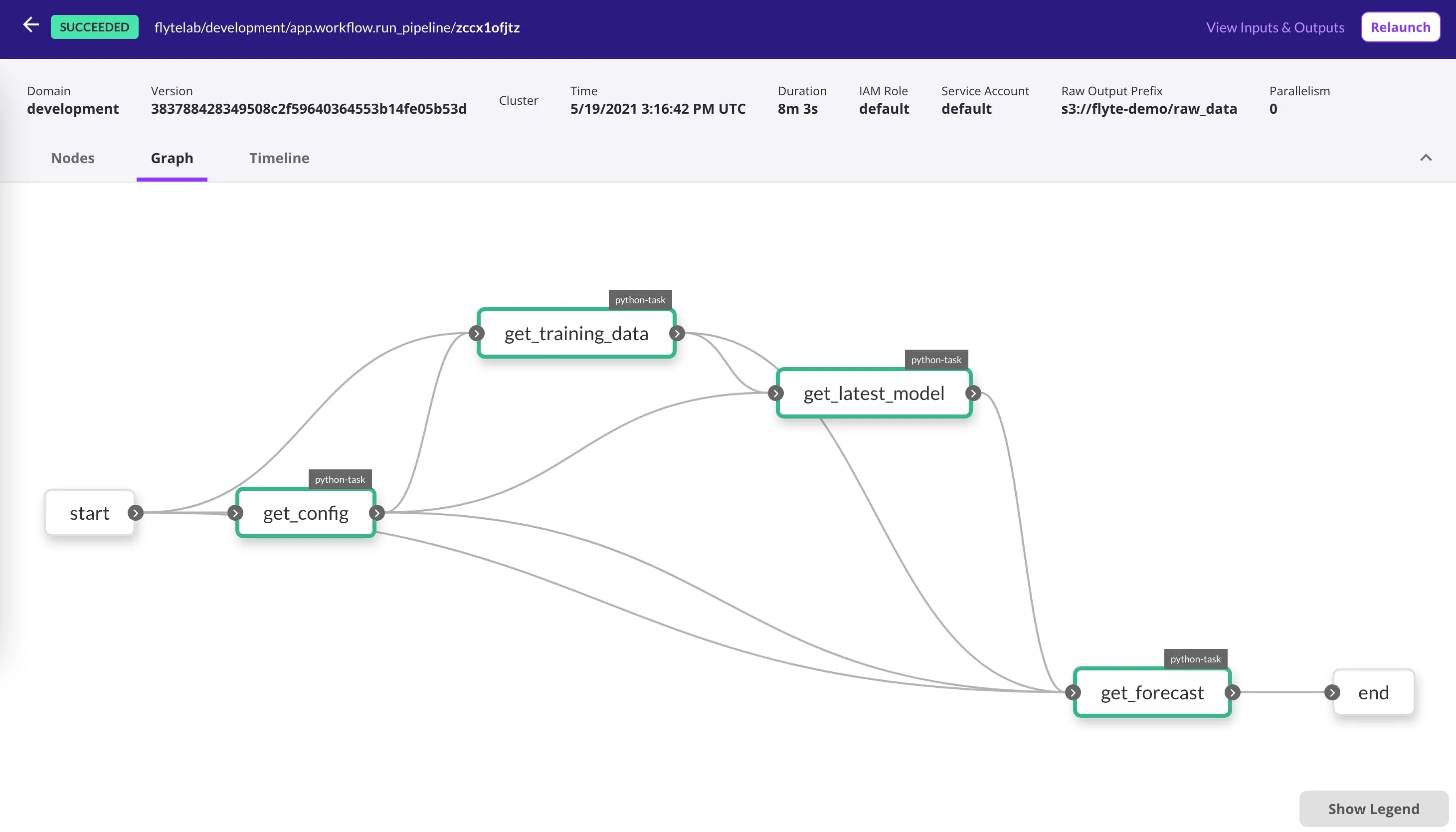
Separate Infrastructure From Business Logic
One significant design decision of Flyte is its multi-tenant architecture. Multi-tenancy provides the required infrastructure to manage different teams, all working on the same platform.
The multi-tenancy feature was inspired by AWS, where a large number of startups found it easy to manage their infrastructure because AWS helped commoditize the infrastructure by providing a centralized managed infrastructure, while the builders could just build. This specific analogy, where development and infrastructure management could be separately handled and the infrastructure for multiple teams could be centralized, motivated us to make Flyte multi-tenant. This allowed our platform partners to offer Flyte as a PaaS within their organizations.
Flyte’s multi-tenancy starts with projects and domains. There is no need for separate environments for development, staging, and production (domains), or individual projects to distinguish team concerns (projects). Moreover, all the infra can be managed by a central infrastructure team!
Flyte also enables environment isolation and separation of concerns. It draws a line between infrastructure and the actual business logic, empowering teams to innovate and scale quickly. Also, in cases like GDPR and other regulatory requirements, Flyte is designed to easily segment the use cases and isolate them in separate clusters without needing to replicate the management infrastructure.
Resource Awareness
One of the challenges of deploying new applications to production is the ramp to bootstrap the infrastructure. The discipline of DevOps has streamlined the process of deploying services to production, but for ML and data pipelines, such an approach does not exist. Moreover,
- infrastructure requirements vary from one use case to the other,
- provisioning can be ad hoc,
- systems may need many GPUs or memory, and in some cases,
- it may be desirable to use different software stacks like Spark, Flink, etc.
Assigning resources based on the maximum requirement of all jobs in a workflow isn’t a cost-effective solution, as it doesn’t lead to the complete utilization of resources. We need an optimal solution that allows users to assign and utilize what’s required.
Flyte provides complete support to control the resource awareness of workflows. Indeed, the resources can be set at multiple levels depending on the requirement.
Users might also want to invoke external services like Snowflake, etc. These have global/account-wide rate limits. To ensure fairness, one needs to use client-side throttling and fairness algorithms. Consider a scenario where Snowflake allows n concurrent queries and there are m tenants. If each tenant requests for n queries, it is possible that one tenant (first come, first serve) will win and block all other tenants. A better approach would be to cap one tenant and allow other tenants to execute within their caps; then when there’s a lack of global activity, one tenant can be scaled to a more significant number.
Flyte can handle all this! It supports automated backpressure management and throttling and has algorithms to ensure fairness across multiple tenants.
Platform Integrations
An off-the-shelf package may not be available when you want to connect Flyte to an external service. Flyte isn’t an engine that presents everything you possibly need. However, it does provide an essential foundation to integrate with other tools or services.
Extending Flyte through plugins/integrations is natively supported. Flyte is extensible in every component: the programming SDK, backend, UI, etc.
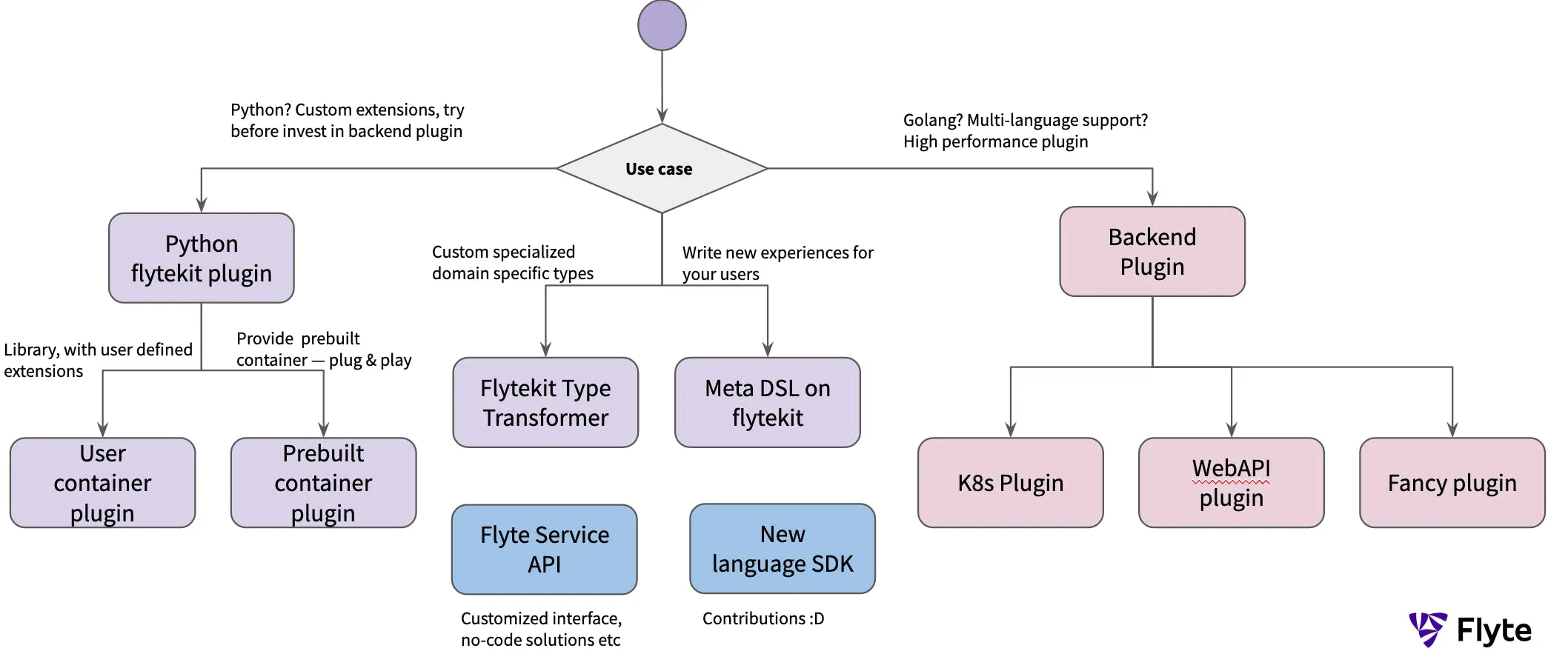
Today, Flyte is integrated with:
- Feast: Simplifies feature engineering with Feast-provided feature stores
- Horovod: Runs distributed training with multiple deep learning frameworks
- Great Expectations: Validates files, schemas, SQL databases
- Pandera: Runs data quality checks on DataFrames
- Weights & Biases: Runs model tracking within the Flyte pipelines
- Dolt: Constructs SQL databases with Git-like capabilities
- Modin: Speeds up Pandas
- Kubeflow PyTorch: Natively runs distributed PyTorch jobs
- Kubeflow TensorFlow: Natively runs distributed TensorFlow jobs
- Kubeflow MPI Operator: Provides all-reduce style distributed training on Kubernetes
- AWS Sagemaker: Runs Sagemaker jobs within Flyte
- AWS Athena: Queries AWS Athena services (Presto + ANSI SQL support) from within Flyte
- AWS Batch (Single and Array jobs): Runs thousands of batch computing jobs on AWS
- GCP BigQuery: Handles big data seamlessly
- Snowflake: Provides data-warehouse-as-a-service within Flyte
- Kubernetes Spark: Runs Spark jobs natively on Kubernetes
- Kubernetes Pods: Abstracts Kubernetes pods to run multiple containers
- Hive: Connects to Hive services from within Flyte
- SQL: Runs SQL queries by connecting to SQLite3, SQLAlchemy
- Papermill: Executes Jupyter notebooks as Flyte tasks
Enter the World of ML-Aware Orchestration
Flyte intends to solve orchestration problems specific to ML practitioners. In this regard, it implements several features that aid in the ML lifecycle, such as intra-task checkpointing.
Workflow engines are naturally checkpointing systems, but these checkpoints can be expensive and do not fit with the tight iterative nature of ML training loops. But checkpointing in ML is crucial, as a long-running training job could be useless if it failed just before completion because of an infrastructure issue. Flyte makes it easy to checkpoint a long training loop and recover from it in the face of failures. This also makes it possible to leverage ephemeral infrastructure like Spot or preemptible instances for training, which can dramatically reduce the cost of training.
Another critical feature for ML practitioners is visualization. Flyte tracks data and its movement through the system (data lineage), but we want to offer a lot more flexibility to the users to visualize this according to their requirements. For example, users should be able to:
- Customize the visualization of the training processes
- Track model drift and computed data drift
- Choose any of the multiple visualization options in the open-source ecosystem
There are a couple more features in the works which simplify running ML pipelines:
- Model portability and optimization
- Extending Flyte to support manual/semi-supervised labeling use cases
- Making datasets a first-class entity in the system, to help with sampled sets or golden test sets
- And some really exciting ecosystem projects that simplify the world of MLOps
Use Cases
Practical case studies about production-level deployments of Flyte are well underway. Learn from the thought leaders!
Ecosystem
We have planned many integrations and exciting ecosystem projects, documentation improvements, and collaborations. Stay tuned!
Flyte is on a mission to empower every organization to build scalable and reliable machine learning and data platforms. It is an engine informed by practical use cases collected from 100s of users from various organizations that address different aspects of the industry.
We realize many infrastructure teams have migrated or are thinking of migrating to Kubernetes soon. Flyte is the perfect solution to leverage Kubernetes to tremendously accelerate the development of ML and Data products for teams and stay compliant with the rest of the infrastructure in the organization.
We have come a long way, but there is still a long road ahead! If you are excited about Flyte, its vision, and growth, we invite you to join our Slack channel to connect with the Flyte team and Twitter to stay tuned. Please visit our repo and check out our docs to learn more about Flyte.
.webp)
