Introduction: The Dynamic Advantage of Flyte 2.0
Flyte 2.0 represents a fundamental shift in workflow orchestration, moving from static DAG composition to truly dynamic workflow execution. This evolution unlocks powerful programming patterns that were previously impossible or constrained in Flyte 1 and other mainstream orchestrators.
Key Architectural Improvements
- Dynamic Workflows: Unlike Flyte 1's static DAG compilation, Flyte 2.0 workflows execute as native Python code with full control flow capabilities. This eliminates the promise-based limitations of traditional orchestrators, where operations on task outputs required complex workarounds.
- Arbitrary Task Nesting: Tasks can now invoke other tasks at any depth, enabling recursive and compositional patterns. Previously, this required cumbersome dynamic workflows with significant limitations.
- Native Python in Driver Tasks: Driver tasks execute as standard Python functions, allowing developers to use familiar constructs like loops, conditionals, and exception handling without DAG compilation constraints.
- Direct Output Manipulation: Task outputs are immediately available as Python objects, not promises. This enables real-time decision making and complex data flow patterns that Flyte 1 could not support.
These improvements collectively enable a new class of workflow patterns: higher-order functions that operate on tasks themselves, providing reusable abstractions for common orchestration challenges.
Higher-Order Functions: Reusable Orchestration Patterns
Higher-order functions in the context of workflow orchestration are functions that accept tasks as parameters and return new behaviors or results. This pattern allows developers to separate orchestration logic from business logic, creating reusable components that can be applied to any compatible task.
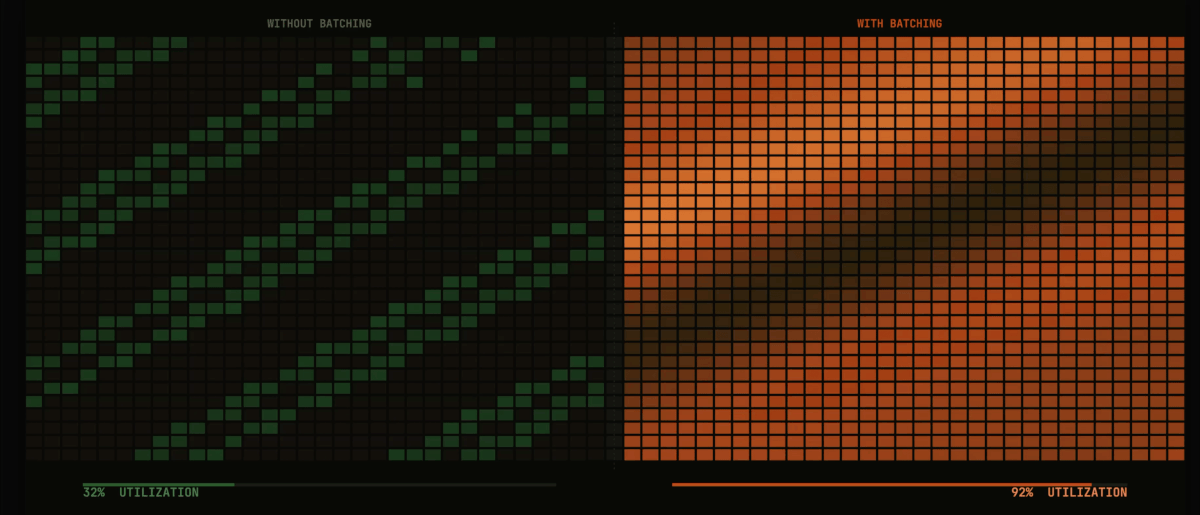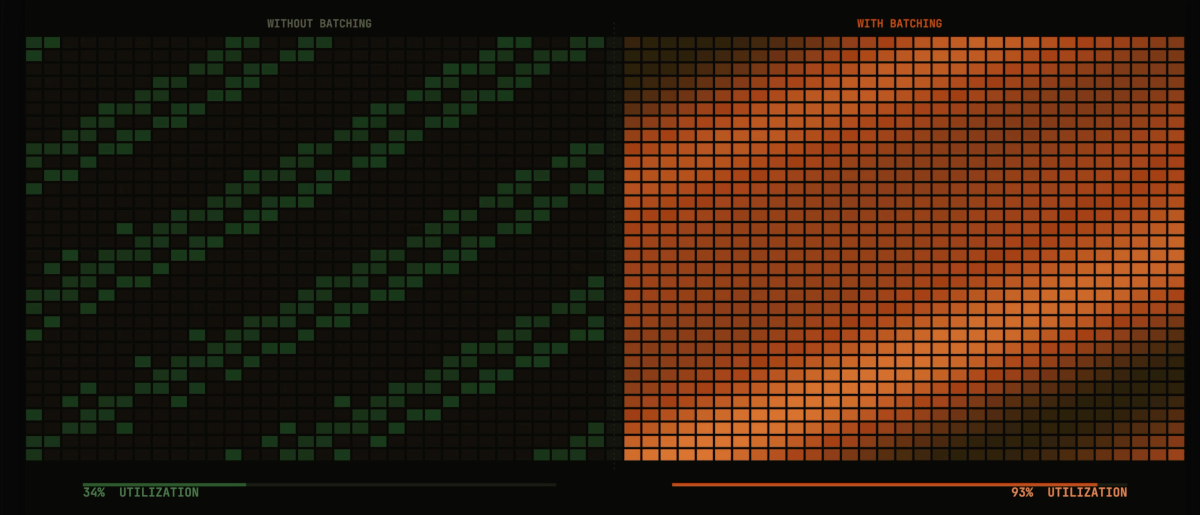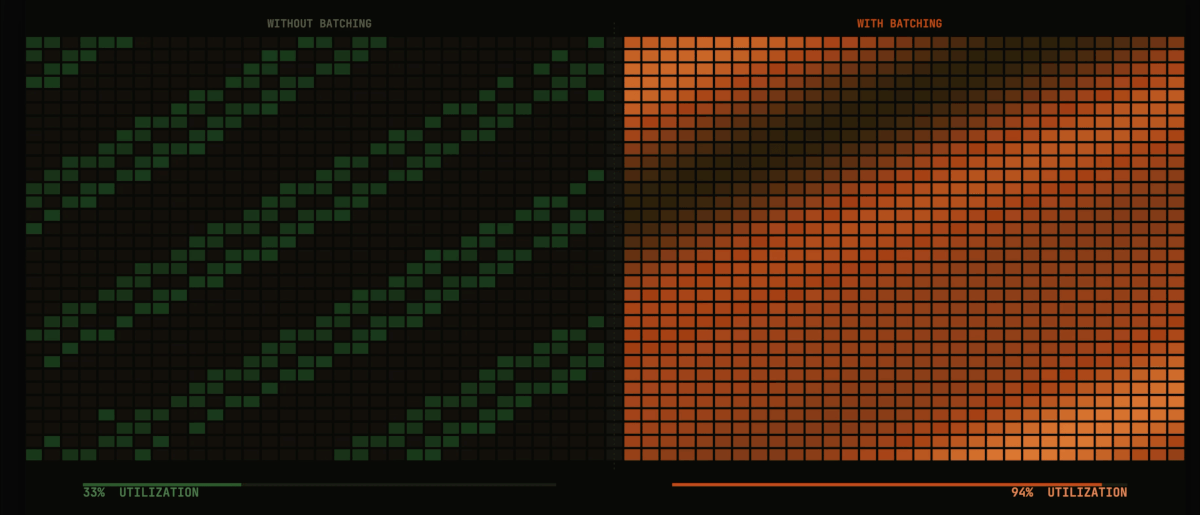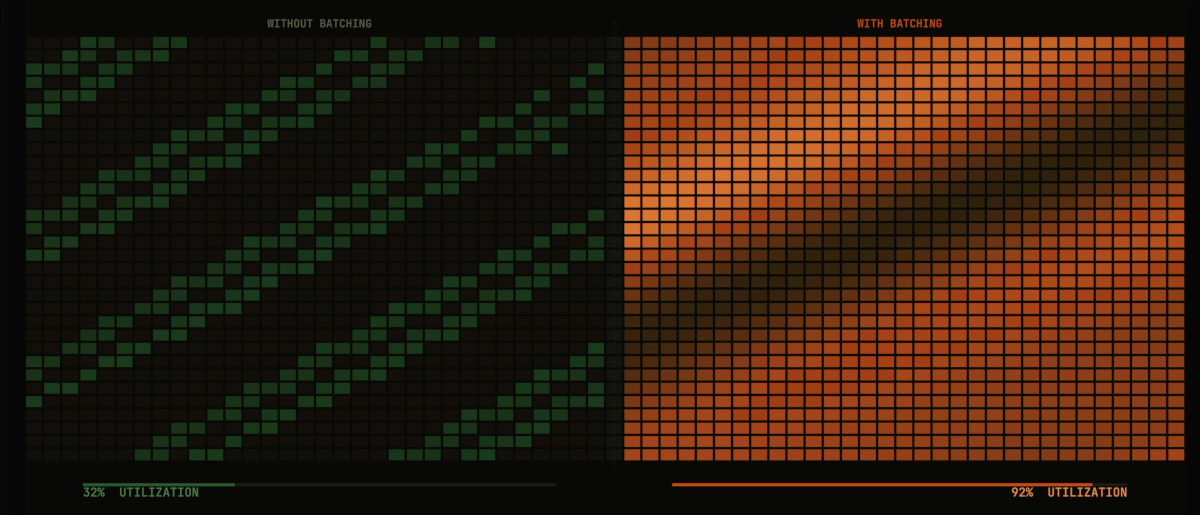
Consider the common need for batch processing with fan-out parallelism. In Flyte 1, each workflow requiring this pattern would implement its own batching logic, leading to code duplication and inconsistent behavior. With Flyte 2.0's higher-order functions, a single batch_process implementation can be applied to any task, standardizing the pattern across an organization.
This compositional approach offers several advantages:
- Separation of Concerns: Business logic remains focused on domain-specific processing
- Reusability: Common patterns are implemented once and reused across workflows
- Maintainability: Updates to orchestration patterns propagate automatically
- Testability: Orchestration patterns can be unit tested independently
Practical Examples
The following examples demonstrate higher-order functions that address real-world orchestration challenges. Complete implementations are available in this repository. The complete, runnable code for these patterns is available in the official Flyte examples repository: https://github.com/flyteorg/flyte-sdk/tree/main/examples/higher_order_patterns.
Automatic Memory Scaling (OOM Retrier)
Memory requirements for AI workloads often vary significantly based on input characteristics. Traditional approaches either over-provision memory for all executions (increasing costs) or risk frequent out-of-memory failures. The OOM retrier pattern provides automatic memory scaling, starting with minimal resources and increasing allocation only when necessary.
In Flyte 1, overriding task arguments required dynamic workflows with limited flexibility. Flyte 2.0's native Python execution makes this pattern straightforward to implement and allows overriding any task attribute, not just resource specifications.
Usage:
This pattern significantly reduces infrastructure costs by avoiding over-provisioning while maintaining reliability through automatic scaling. Organizations can optimize for typical workloads while gracefully handling outliers.
Circuit Breaker for Fault-Tolerant Parallelism
Parallel task execution often involves external dependencies that may experience partial failures. A circuit breaker pattern provides controlled failure handling, allowing workflows to fail fast when error thresholds are exceeded while preserving partial results when possible.
Different organizations have varying requirements for failure handling: some need count-based thresholds, others percentage-based; some want partial results, others prefer placeholders. Flyte 2.0's flexibility allows complete customization of these behaviors.
This implementation leverages asyncio's native wait() function with FIRST_COMPLETED to monitor task completion in real-time. The circuit breaker immediately cancels remaining executions when the failure threshold is exceeded, preventing resource waste on operations likely to fail.
Key Features:
- Real-time Monitoring: Uses asyncio primitives to detect failures as they occur
- Immediate Cancellation: Stops remaining tasks when threshold is exceeded, not after hundreds potentially fail
- Native Integration: Works seamlessly with Python's asyncio ecosystem
- Configurable Behavior: Adaptable to different failure tolerance requirements
Usage:
The pattern demonstrates Flyte 2.0's seamless compatibility with standard Python concurrency patterns, eliminating the need for custom orchestration primitives.
Additional Patterns
This repository includes several other higher-order patterns:
- Auto Batcher: Automatically batches large datasets for parallel processing with configurable batch sizes and map-reduce operations.
- Fallback Runner: Provides automatic fallback to alternative implementations when primary tasks fail with specific exceptions, with intelligent exception unwrapping for Flyte error types.
Each pattern demonstrates different aspects of Flyte 2.0's flexibility and the power of treating tasks as first-class values in higher-order functions.
Conclusion
Flyte 2.0's transition to dynamic execution and native Python semantics enables powerful compositional patterns that were impossible in previous versions. Higher-order functions provide a mechanism for creating reusable orchestration components that separate infrastructure concerns from business logic.
The examples presented demonstrate practical applications of this pattern for common challenges in AI workflow orchestration: resource optimization, fault tolerance, and parallel processing. By leveraging Python's native concurrency primitives and Flyte 2.0's dynamic execution model, these patterns provide robust, efficient solutions that scale across diverse workloads.
The shift from static DAG compilation to dynamic execution fundamentally changes how developers can approach workflow composition, enabling patterns that bring the full power of Python's ecosystem to workflow orchestration.