

A high-level look at first-class Weights & Biases support in Flyte 2.
Modern ML stacks are composable almost to a fault. You can wire together orchestration, training, evaluation, and experiment tracking however you like, but too often, the glue code becomes the system. Experiment tracking, in particular, tends to live adjacent to orchestration: bolted on, manually initialized, and easy to forget when pipelines scale or evolve.
Flyte 2.0 (and Union.ai, the enterprise Flyte platform) takes a different stance. By being fully Pythonic AI development infrastructure, Union.ai and Flyte 2.0 are opinionated about developer experience. You should be able to integrate any third-party service or open-source dependency without ceremony. And more importantly, those integrations shouldn’t feel like afterthoughts.
That philosophy is what led to first-class experiment tracking as a native concept in the orchestrator. Our goal with the Weights & Biases integration is to make experiment tracking disappear into the workflow with no boilerplate, no custom setup code, and no mental context switching between pipeline logic and tracking logic. Just experiments, tracked automatically, where they belong.
This integration brings experiment and model tracking directly into the Flyte SDK and Union.ai UI, making it feel less like an external service and more like a built-in capability. It’s a small shift in ergonomics, but a big shift in how pipelines are authored, reasoned about, and debugged.
When experiment tracking is just an integration away, it stops being something you must add to pipelines, and starts being something pipelines simply do.
This is our first deep integration of this kind, and Weights & Biases is the proving ground. Let’s take a look at what this enables, why it matters, and why native experiment tracking in the orchestrator is more than just a convenience feature.
What native experiment tracking enables
The easiest way to understand what this integration unlocks is to look at the Flyte 2.0 SDK, and notice what isn’t there anymore.
Here’s what using Weights & Biases inside a Flyte 2.0 pipeline looks like with the native integration:
At a high level, here’s what’s happening, and just as importantly, what isn’t happening:
- You import the W&B Flyte plugin.
- You add the package to your task image and pass in the API key as a Flyte secret.
- You decorate your task with `@wandb_init`.
- Inside the task, you call `get_wandb_run()` and start logging.
- You provide project-level configuration once at runtime via `wandb_config`.
In practice, this removes a few common sources of boilerplate:
- No explicit `wandb.init()` calls inside tasks
- No repeated W&B configuration in individual tasks; define it once and reuse it across the workflow
- No need to generate or pass run IDs between Flyte and W&B
- No manual linking between task executions and W&B runs
- No explicit run finalization or cleanup logic
When this runs, Flyte automatically wires the W&B run to the task execution. The Union.ai UI shows a direct link to the W&B dashboard for that task, and the lifecycle of the run is tied to the lifecycle of the task itself.
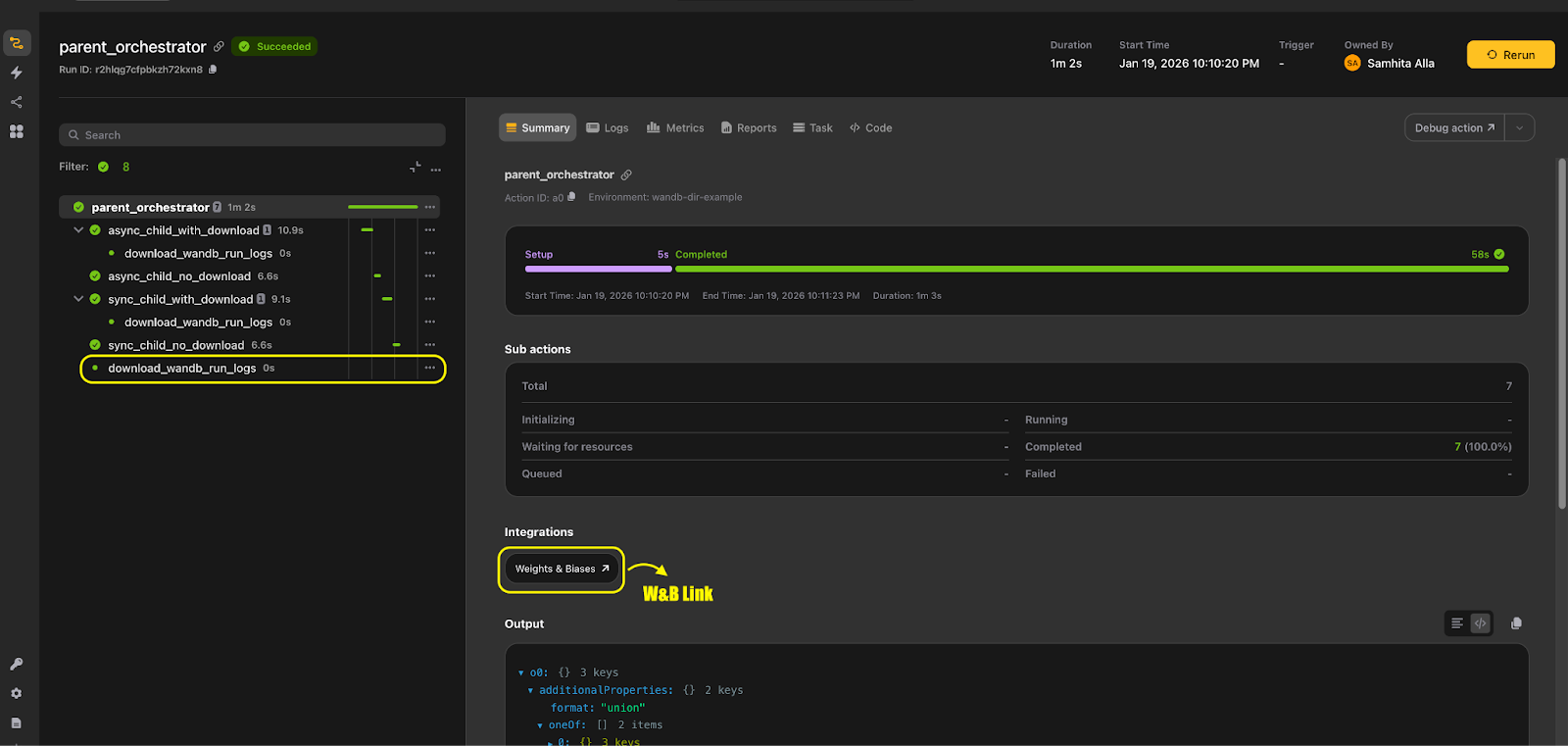
This is what we mean by “experiment tracking disappearing into the workflow”.
Why native experiment tracking matters
The interesting part here isn’t that W&B works in Flyte; you could already do that. The interesting part is that the orchestrator now owns the integration boundary.
Flyte already has the full picture of the execution state. It knows when a task starts, when it retries, when it fails, and when it finishes. Once the orchestrator has that context, it’s the right place to manage experiment tracking as well.
That means Flyte can take care of initializing runs, tying them to the correct execution, surfacing them directly in the UI, and cleaning things up when the task completes or retries. All of that happens outside your task code.
The end result is simpler task logic. Your code focuses on training and evaluation, not on setting up, synchronizing, or managing tracking infrastructure.
What native experiment tracking replaces
To really appreciate the difference, it helps to see what this looks like without the integration.
Here’s a simplified version of a manual setup. We still use the Wandb link class and wandb_config from the Flyte plugin to send W&B configuration, but the run lifecycle is managed manually.
There’s nothing wrong with this but notice how much mental bookkeeping is involved:
- You manually create and manage run IDs.
- You have to ensure the Flyte link and `wandb.init()` stay in sync.
- You explicitly finish the run.
- Your training logic is tightly coupled to tracking lifecycle details.
- This example still relies on `wandb_config` from the Flyte plugin. If you remove that abstraction and manage configuration manually, you would need to pass configuration values as task inputs to make it configurable at runtime.
This approach works, but it does not scale well as workflows grow. Once you add multiple tasks or configure distributed training, the amount of coordination and repeated setup increases quickly. Configuration gets duplicated across tasks, tracking logic spreads throughout the codebase, and even small changes, like updating a parameter, require touching multiple places. Over time, experiment tracking becomes something you have to manage carefully instead of something that stays out of the way.
The shift
What this integration really represents is a move toward orchestrator-centric experiment tracking, where the workflow system, not the task code, owns the run lifecycle and visibility.
With the Weights & Biases plugin in Flyte:
- Runs and hyperparameter sweeps can be created, configured, and linked automatically using decorators and context configs rather than manual SDK calls.
- Flyte surfaces direct links to both individual W&B runs and sweeps in the UI, making traceability immediate without extra annotation in logs.
- Parent/child task relationships can reuse the same experiment context, so you don’t have to propagate run IDs manually if you want a child task’s logs to contribute to the same experiment.
- You can define hyperparameter sweeps declaratively inside workflows, then execute multiple agents in parallel, all coordinated by Flyte and tracked back to W&B.
Put another way: instead of thinking “I need to write code to track this experiment”, you now think “this workflow should be tracked” and Flyte handles the rest. That’s a subtle but meaningful shift in how tracking becomes embedded into pipeline logic.
This shift has some practical implications for real workloads as well:
- Consistent configuration: Instead of embedding W&B config parameters inside task logic, you provide them once at workflow invocation (e.g., via `wandb_config(...)`).
- Sweeps as first-class workflows: Hyperparameter sweeps aren’t ad-hoc scripts anymore; they’re tasks with structured definitions that can be reused, parameterized, and scaled.
- Cross-task observability: Child tasks can inherit or create new runs cleanly, so artifacts and metrics can flow from one step to the next without manual plumbing.
- UI-driven exploration: Flyte’s UI now surfaces experiment links directly, reducing context switching between systems.
All of this enables patterns that were possible before, but not natural. With this integration they become first-class constructs in your pipeline authoring experience.
To see how this plays out in practice, it helps to look at sweeps and distributed training more closely.
Sweeps
The integration treats sweeps as a natural extension of workflows. Flyte runs individual sweep agents as tasks, passes the W&B context into each agent, and associates every run with the correct sweep in Weights & Biases. Flyte also surfaces links to the sweep directly in the UI.
You no longer need custom loops, external agents or ad hoc job launch scripts. Sweep definitions stay declarative, execution stays reproducible, and everything lives alongside the workflow definition.
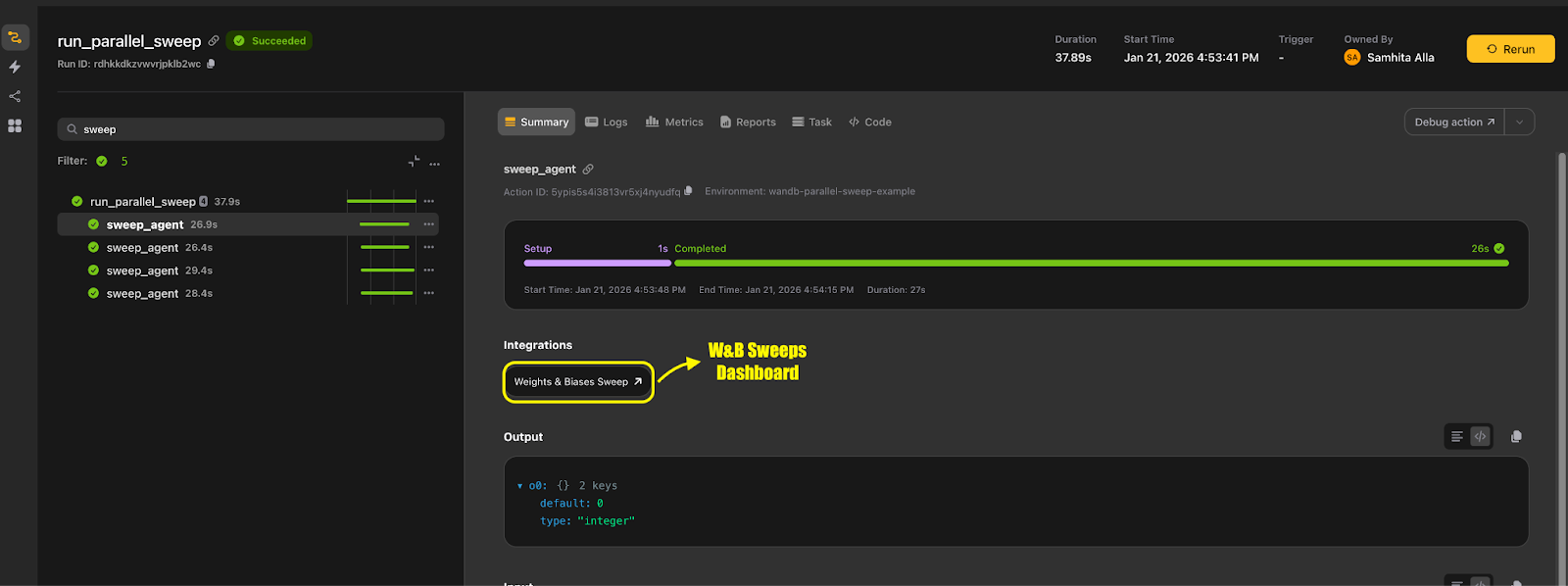
Distributed training
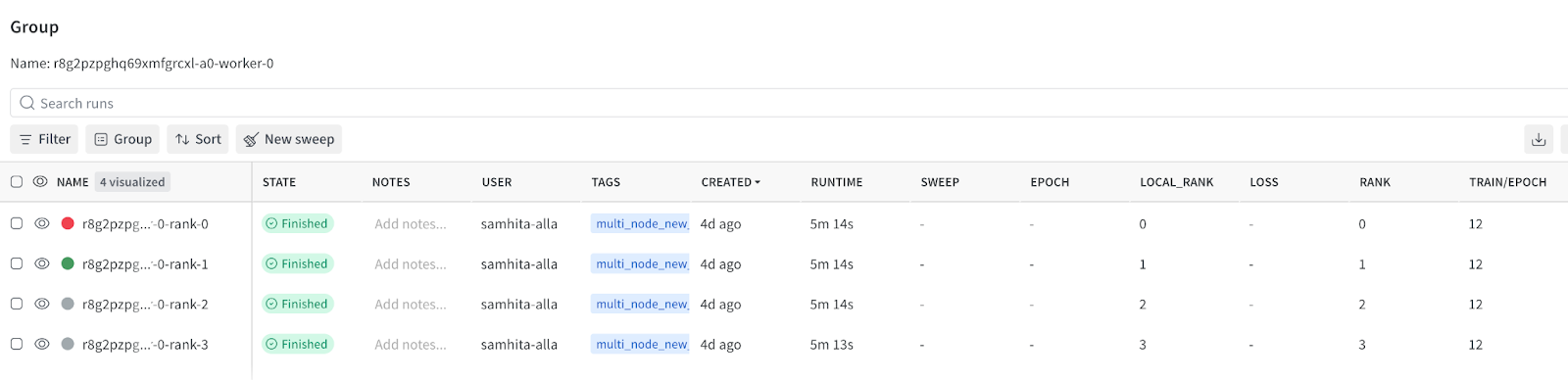
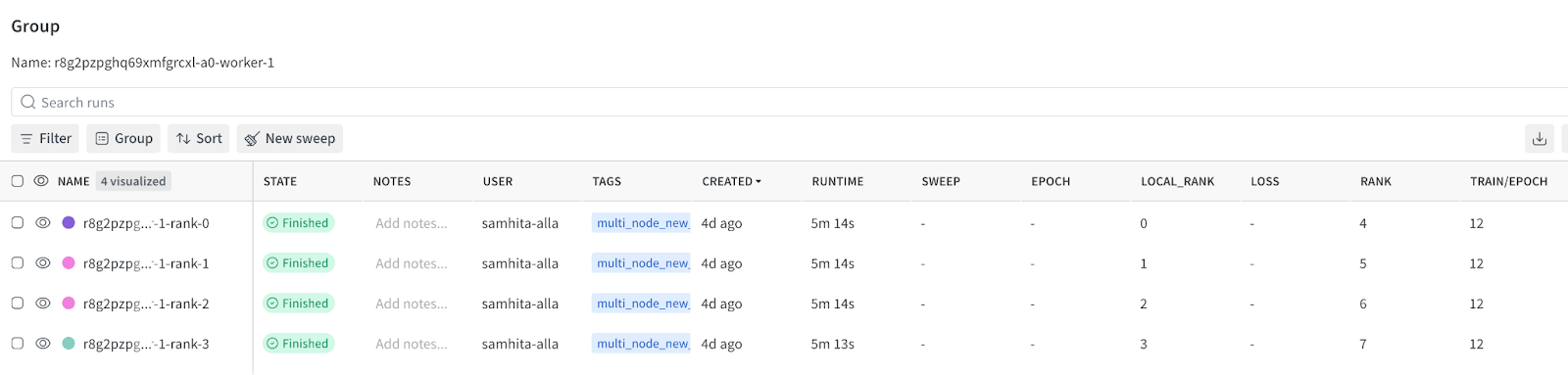
Distributed training follows the same principles. Tasks can run across multiple GPUs or workers, in both single-node and multi-node setups, without changing how experiment tracking is configured.
You control how runs are scoped. You can share a single run across all workers, create one run per worker, or create runs per rank and group them as needed. You configure this behavior explicitly using `run_mode` and `rank_scope`, which keeps the tracking model predictable.
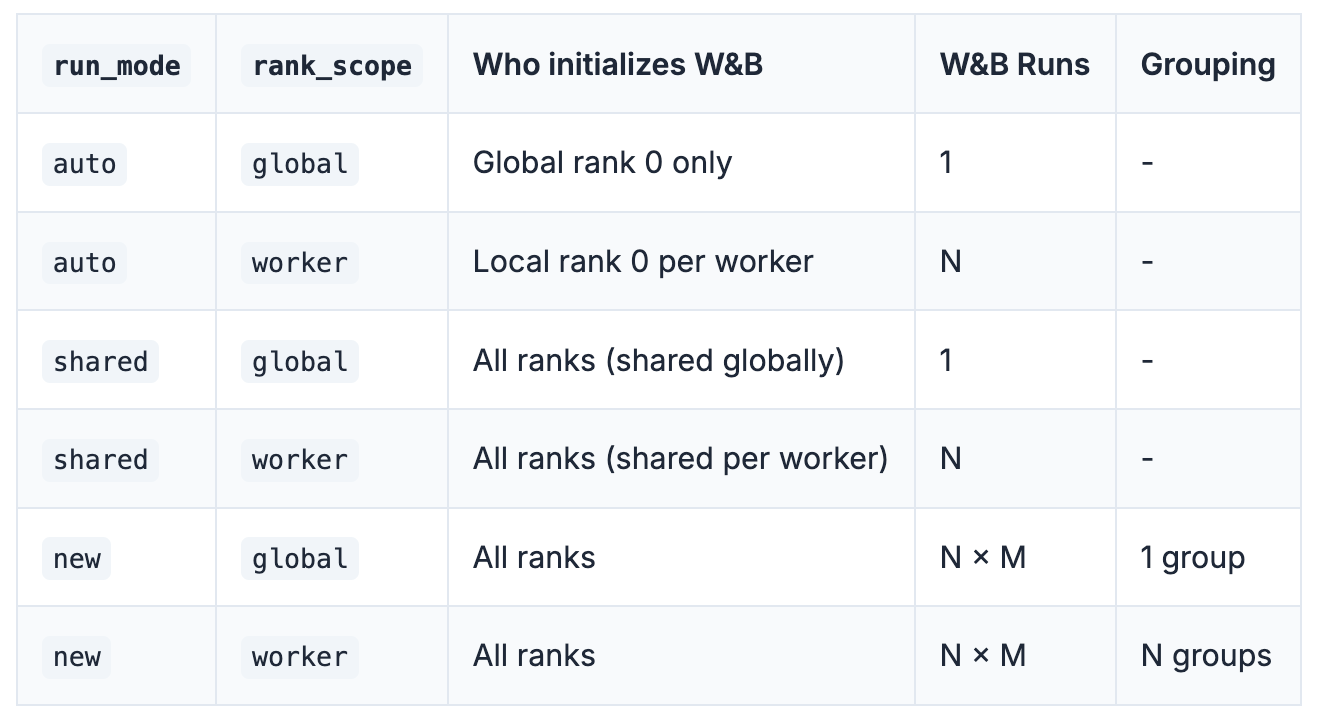
The important part is that this logic lives outside the training code. You are not encoding assumptions about rank zero, worker identity or run grouping inside the task itself. Instead, Flyte manages execution topology, and the W&B integration maps that topology onto a clear experiment tracking structure.
This keeps distributed training code focused on computation, while experiment structure remains configurable, consistent, and visible at the workflow level.
Here’s an example showing how to track a single-node, multi-GPU distributed training job with Weights & Biases.
To enable W&B tracking, all that’s required is adding the `@wandb_init` decorator to the relevant task and retrieving the run. By default, this uses `run_mode=auto` and `rank_scope=global`, which initializes the run on rank 0 and makes it available there. You use the same pattern for multi-node training. What changes is when and where the run is initialized, and how many run links appear in the UI.
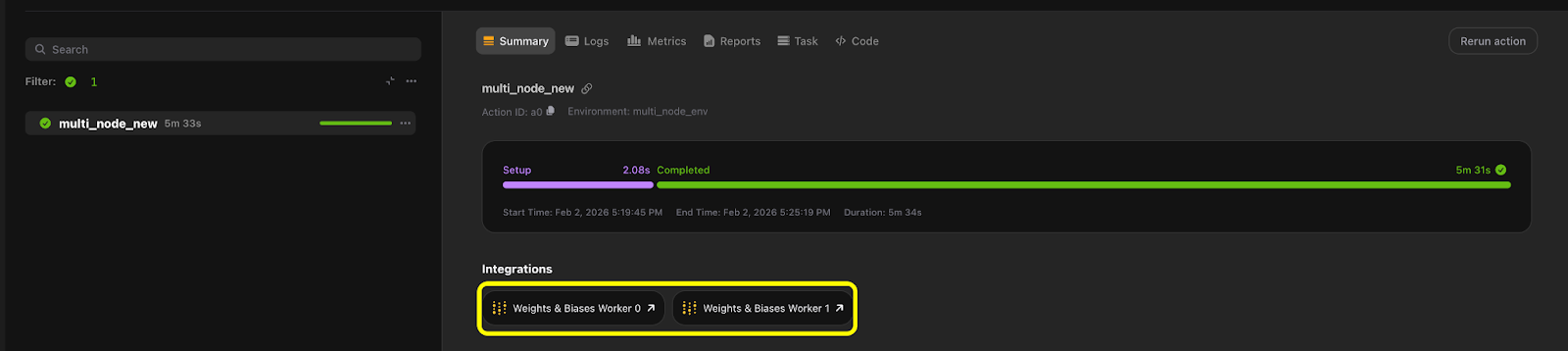
Closing thoughts
Making experiment tracking native to the orchestrator moves the run lifecycle and configuration out of task code and into the workflow system. This becomes more important as workflows grow beyond a single training script. Software infrastructure is evolving to become AI development infrastructure, and simplifying experiment tracking is a perfect example of this.
This approach scales naturally. Whether you are running a single task, a multi-stage pipeline, a sweep, or a distributed training job, the tracking model stays the same. You do not rewrite tracking logic as the workflow evolves. You declare intent once and let the orchestrator enforce it.
We plan to extend this model to other experiment trackers with the same goal: integrations should feel native and predictable. You write workflows. Flyte handles execution and tracking.
Next steps
Check out the Weights & Biases integration documentation for setup details, configuration options, sweeps, and distributed training examples.
.png)

