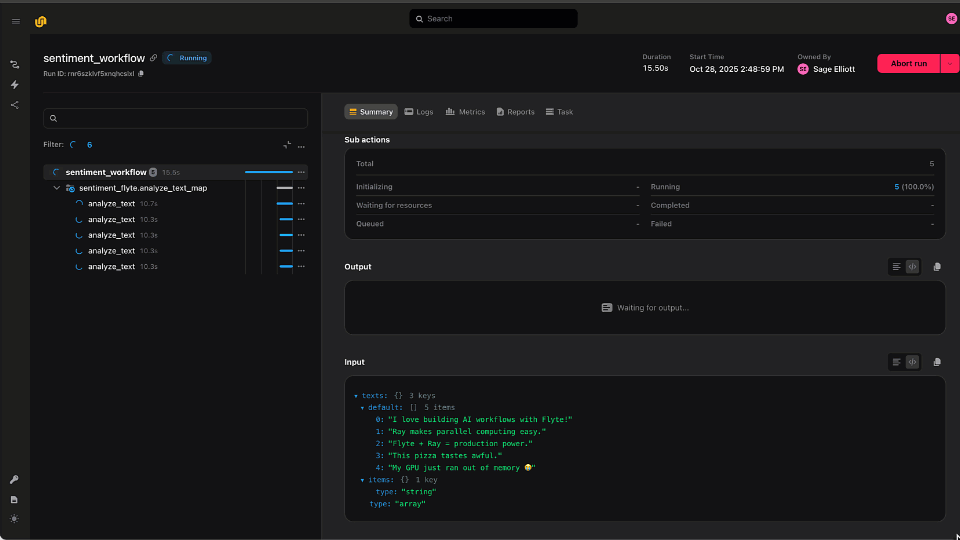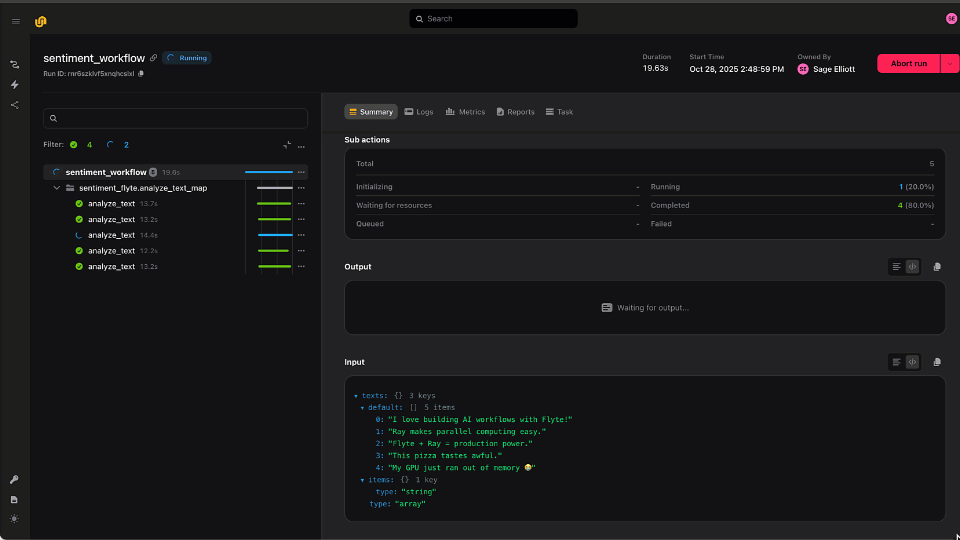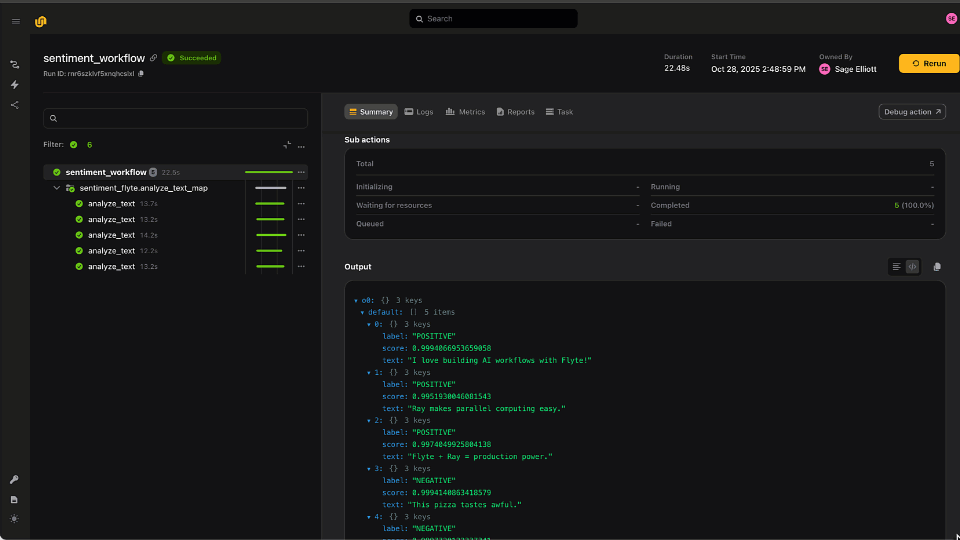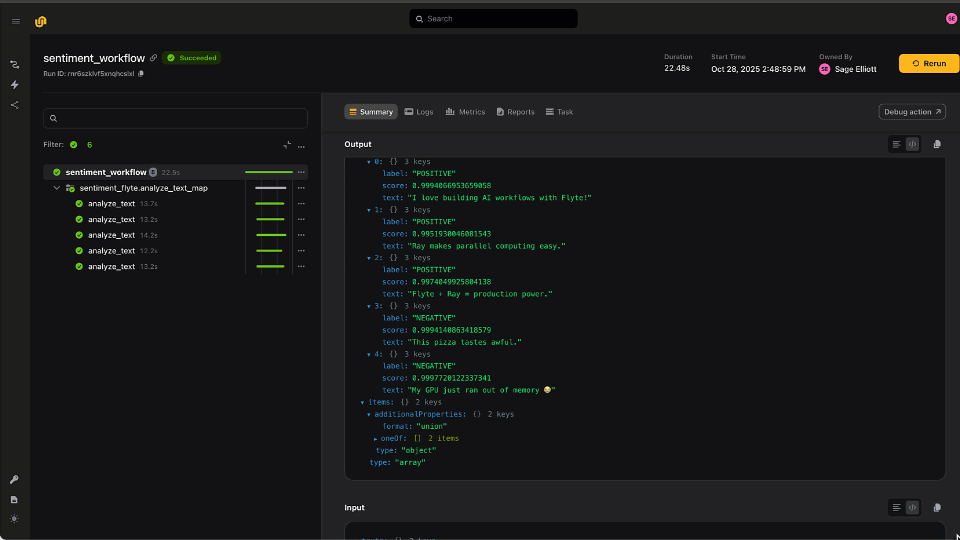
Distributed computing is one of those “good problems to have.” It means your ML models, AI pipelines, or simulations are big enough that a single machine just won’t cut it! But the question quickly becomes: How do you actually scale an AI workflow?
Two popular answers are Ray and Flyte. They often get compared, but in reality, they were born for different jobs. And with the arrival of Flyte 2.0, the comparison looks very different than it did a year ago.
What Flyte 2.0 Brings to the Table

At its core, Flyte has always been about AI orchestration done right. It’s the tool that turns experiments into reliable, production-grade AI systems.
Flyte makes it easy to define workflows that are reproducible, versioned, and cached, automatically managing artifacts, datasets, models, and outputs across runs. It enforces structure so pipelines are type-safe, observable, and debuggable, while handling retries, scaling, and resource scheduling seamlessly across Kubernetes.
Flyte 2.0 re-imagines orchestration for the modern AI stack offering dynamic, parallel, fault-tolerant, and fast workflows. You can write plain Python workflows with for loops or asyncio.gather, scale them automatically across your clusters, and know every run is versioned, cached, and reproducible.
Highlights of Flyte 2.0
- Dynamic Orchestration – Define, branch, and modify workflows at runtime using native Python.
- Durability & Reproducibility – Built-in caching, retries, and lineage tracking for every task.
- Parallelism at Scale – Fan-out via asyncio.gather, dynamic tasks, or map-style patterns, that are as fast or faster than Ray for most AI workloads.
- Resource-Aware Scheduling – Flyte assigns CPU/GPU/memory and scales to zero when idle.
- Reusable Containers – Union’s warm-container model eliminates cold starts and cuts cost across runs
- No more DSL workflow limitations (if you’re familiar with Flyte 1)
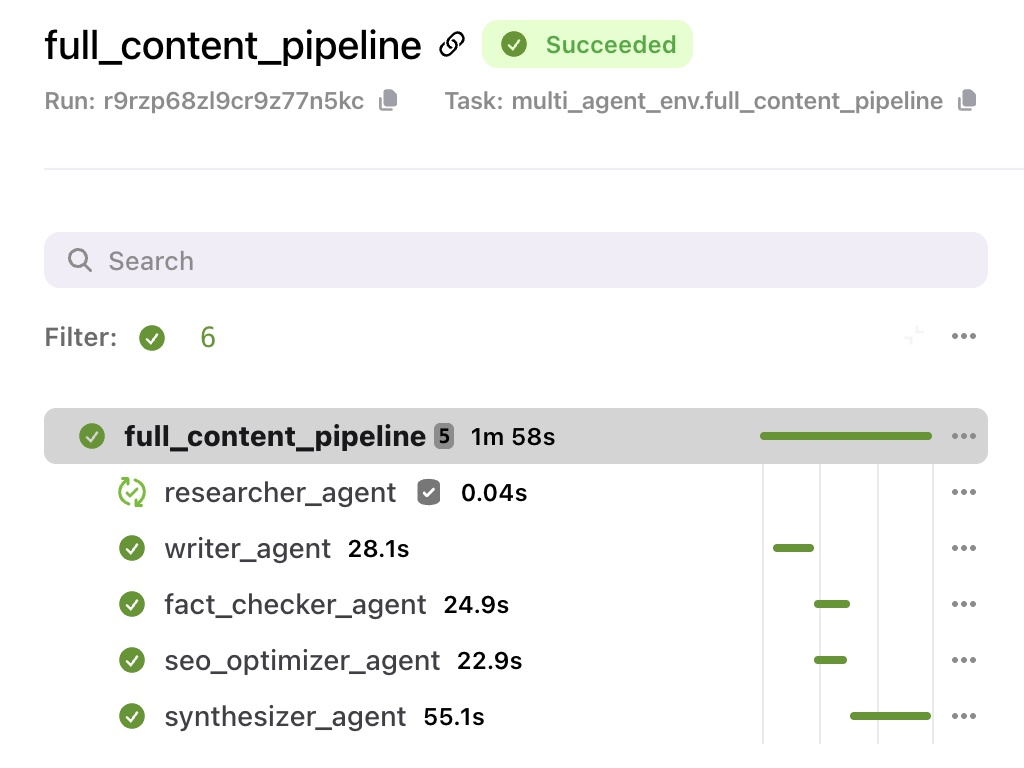
Flyte keeps every step captured, reproducible, and efficient, from data prep to training to evaluation within one simple Python SDK. Flyte 2.0 extends these features to fully dynamic workflows allowing for both scalable traditional AI workflows and Agentic applications.
Engineers love Flyte because it feels just like building with Python, but it’s production-ready out of the box! Create a reproducible environment, and declare a Flyte task
Without Flyte, you’re left wiring fragile scripts, tracking versions manually, and hoping nothing fails mid-run.
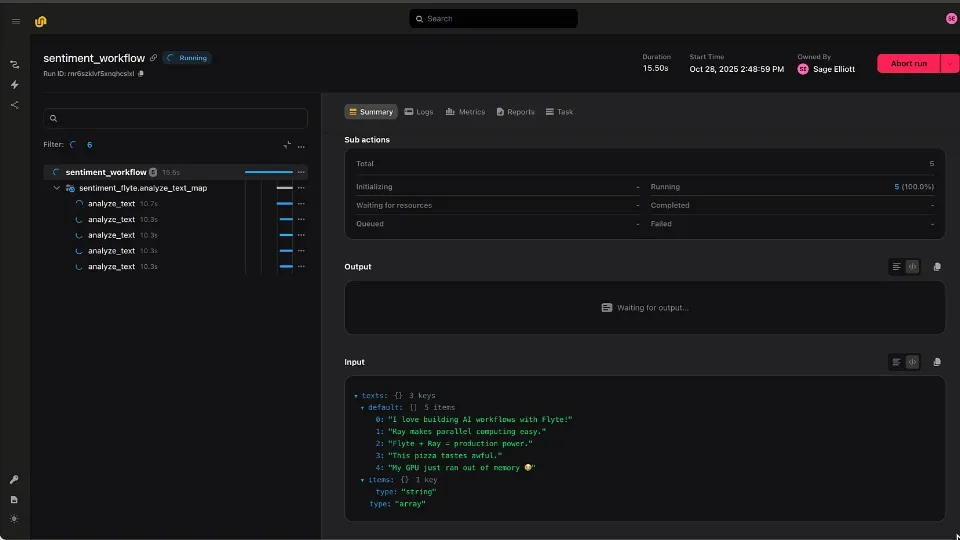
With Flyte 2.0, those headaches disappear. replaced by a durable, dynamic, Python-native platform built for scale.
What Ray Brings to the Table

Ray gives you fine-grained control over distributed tasks and stateful actors, letting you scale from a laptop to a cluster in seconds. With ray.remote() primitives, Ray excels at handling up to millions of small, parallel tasks that may share state, and it shines in high-speed shuffle operations where data must move rapidly between workers.
It also comes with an ecosystem of built-in libraries:
- Ray Data for distributed data loading and preprocessing
- Ray Train for distributed deep learning
- Ray Tune for hyperparameter search
- RLlib for reinforcement learning
Researchers often love Ray because it feels like building with Python, but parallel. Open a notebook, call ray.init(), and you’re scaling across nodes. It’s lightweight, flexible, and great for experimentation.
However, the trade-off is that Ray doesn’t provide durability or orchestration. If your cluster crashes, your progress, state, and lineage are lost, forcing you to restart from scratch. That’s why in production environments, teams often pair it with Flyte, which brings the missing durability, caching, and observability guarantees, turning Ray’s fast but ephemeral compute layer into a truly reliable distributed system.
Flyte + Ray: The Best of Both Worlds
Both Flyte 1 & Flyte 2.0 natively support Ray through its plugin system, giving you the power of Ray’s high-speed distributed execution without the operational headache.
With this integration Flyte automatically spins up a Ray cluster for each task and tears it down when finished, eliminating manual cluster management.
You can also mix Ray and non-Ray tasks in the same workflow for example:
- Preprocess data → Flyte
- Train → Ray Train inside Flyte
- Evaluate → Flyte
You get Flyte’s durability, retries, versioning, and observability, while Ray can handle the fast, in-memory compute and shuffle where it shines when needed.
Flyte 2.0 keeps the AI workflow in order: lineage, caching, reproducibility, and compute resource management while Ray powers the parallelism inside those workflows.
If you’re using Ray in production without Flyte, you’re leaving reliability and efficiency on the table.
Together, Flyte + Ray can deliver a scalable, fault-tolerant, end-to-end foundation for modern distributed AI workloads.
Why Teams Choose One (or Both)
Choose Flyte 2.0 if you care about what actually gets AI into production.
Flyte 2.0 gives you durability, reproducibility, retries, caching, lineage, and observability out of the box, plus dynamic fan-out and resource-aware scaling. It’s built for teams shipping real AI systems, not just running experiments.
If you’re not explicitly doing heavy data shuffling or millions of micro-tasks, Flyte 2.0 is the smarter default.
Choose Ray only if you really need raw distributed execution and shuffle-heavy workloads.
Ray shines when you’re moving data aggressively between nodes, like in simulation-heavy workloads, streaming reinforcement learning, or stateful actor patterns. But you give up durability and orchestration. Once the cluster goes down, so does your progress.
Choose Flyte 2.0 + Ray if you want the full-stack distributed combo.
Flyte 2 gives you durability, orchestration, and structure, Ray gives you the raw distributed horsepower for that rare class of compute-intensive, shuffle-bound workloads. Together, you get fast, reliable, reproducible distributed AI without the fragility of running Ray alone.
Closing Thoughts on Flyte & Ray
Flyte 2.0 and Ray now have a lot of overlap but they're not always competitors, they can be complementary to each other for building Distributed AI Workflows
Flyte 2.0 brings the rhythm, orchestration, durability, caching, reproducibility, and resource-aware scaling
Ray brings raw distributed horsepower, fast actors, in-memory shuffle, and Pythonic parallelism.
Most teams don’t need to reinvent reliability, they need to ship AI that actually runs.
So start with Flyte 2.0, plug in Ray if your workloads demand it, and enjoy a workflow that’s fast, fault-tolerant, and finally production-ready.
Curious to see it in action?
- Sign up for the Flyte 2.0 Beta and try one of the Flyte + Ray examples
- Book a session with an AI engineer to explore how your workloads could scale with Flyte 2.