<div class="text-align-center">This article was originally posted on our Substack, The AI Loop.</div>
<div class="button-group is-center"><a class="button" target="_blank" href="https://unionailoop.substack.com/">Follow The AI Loop</a></div>
If you’ve ever shipped on the OpenAI API stack, you already know the story. It dazzles in a demo, maybe even holds up for a prototype. But the moment you push to production, the wheels start to come off: latency spikes, context limits, compute costs explode.
This experiment-to-production gap is driving teams crazy, so much so that it’s given the hype train a new destination: small language models (SLMs).
“Small language models (SLMs) are sufficiently powerful, inherently more suitable, and necessarily more economical for many invocations in agentic systems, and are therefore the future of agentic AI.” —NVIDIA Research
The SLM Advantage
Unlike their heavyweight LLM cousins, SLMs typically only go up to a few billion parameters and are optimized for speed, cost-efficiency, and narrow-task accuracy as a result. That makes them attractive for businesses that want to ride the AI wave without paying the performance and compute tax of massive models. SLMs can also offer privacy benefits, as many are small enough to run on local devices, instead of requiring a cloud environment to function.
So, in short, you give up some power to make room for more agility. Like a katana instead of a greatsword. Like a ranger archer instead of an orc barbarian. Too nerdy?

Who Loves SLMs?
Some industries and use cases have emerged as SLM first-movers. These applications usually have specialized knowledge, a healthy source of quality data, and the need to move fast.
- Customer chatbots: fast, cheap, CPU-deployable.
- Fintech fraud detection: retrained daily as data shifts.
- Logistics optimization: tuned to narrow vocabularies and constraints.
- On-device/edge AI: healthcare devices, cars, industrial systems needing privacy + offline operation.
- Biotech & clinical research: parsing trial data, summarizing lab reports, genomic search — SLMs tuned on domain data outperform generic LLMs, while keeping PHI secure.
In all of these, an SLM is faster, cheaper, domain-specific, private.
But Here’s the Catch
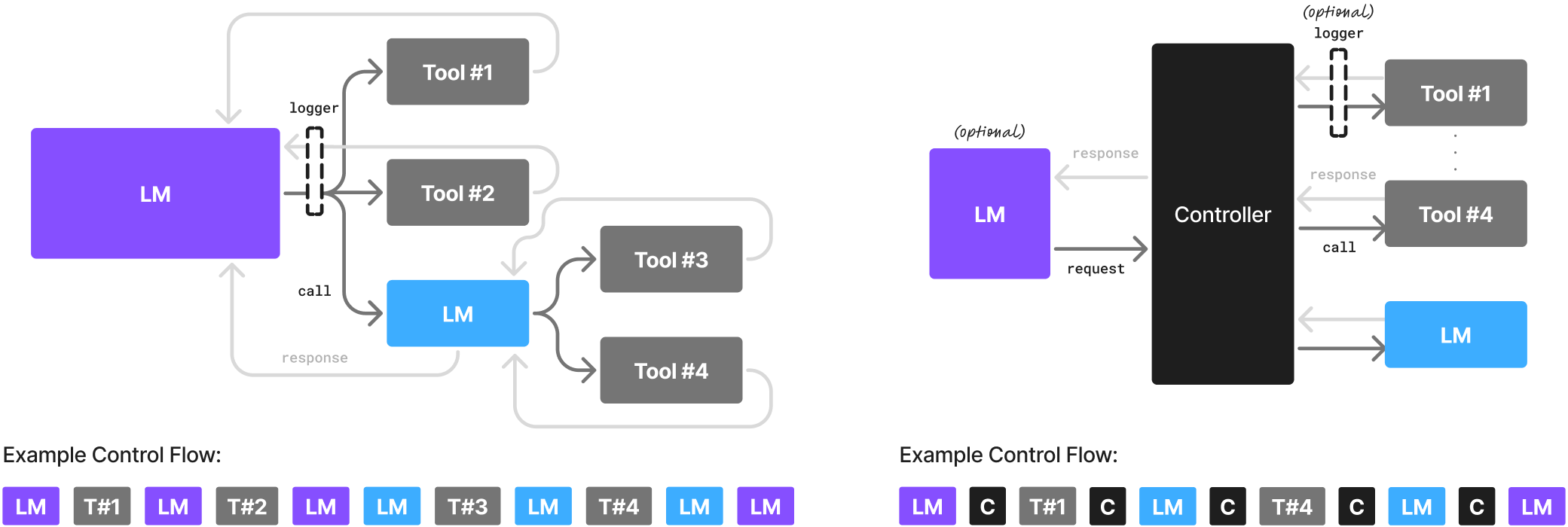
The advantages of SLMs are only real if you orchestrate your AI system correctly.orchestrate your AI system correctly.
Using SLMs is a lot closer to ML Engineering than using LLMs. You’re going from software engineering with foundation models hosted via API to contending with data, data quality, fine-tuning, model evaluation, and of course model selection. Bad orchestration will kill your SLM hopes and dreams (not to be dramatic).
Let’s unpack why.
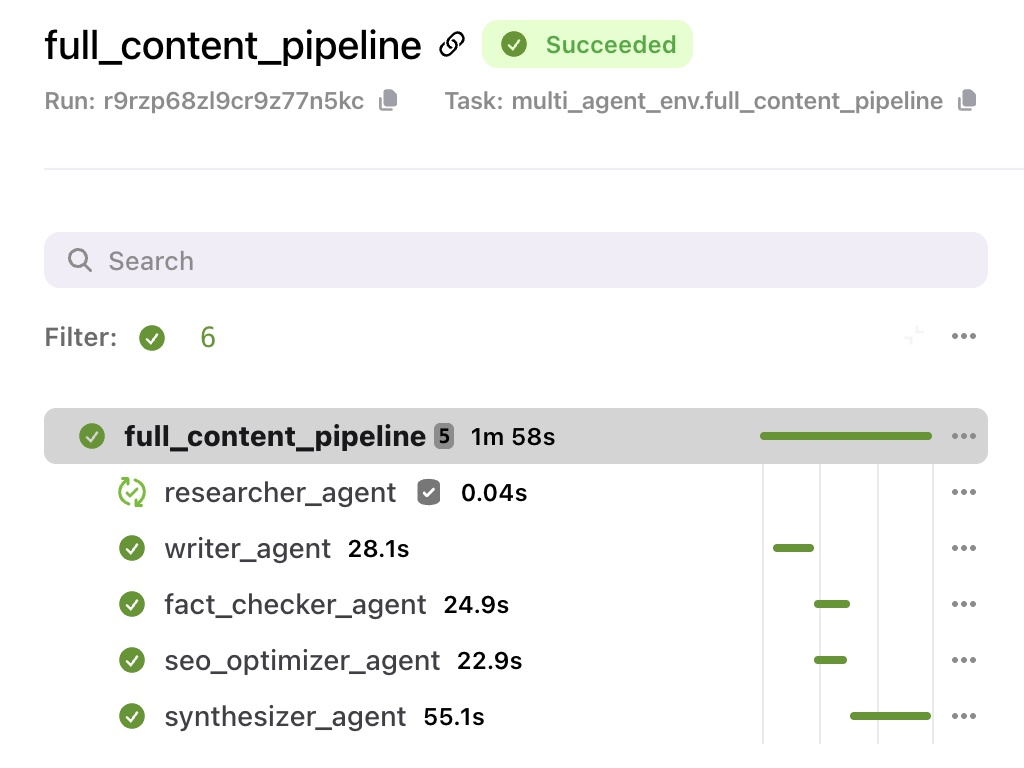
1. Speed: Fine-Tuning and Iteration at Scale
Because of their smaller size, SLMs can be re-trained and fine-tuned more frequently than LLMs. This makes them ideal for industries where data shifts quickly, such as financial services, supply chain, or healthcare. It’s also part of the appeal for enterprises that want to train their AI on custom datasets.
But re-training or fine-tuning frequently can be a time-suck (or worse, break your system in production) without the right underlying infrastructure to support it:
- Workflows should be able to parallelize training runs across multiple containers
- Results should be cached and reused, where possible, instead of always being recomputed from scratch
- Task fanout should be supported (like for hyperparameter sweeps or recursive feature elimination) so that retraining is as efficient as possible
Here’s the bad news: traditional orchestration tools, especially ones that call themselves “data orchestrators” (*cough* Coldplay concert *cough*) are not AI-native. That means your speedy, agile SLM-powered workflows run slower because your orchestrator is repeating processes and introducing latency.
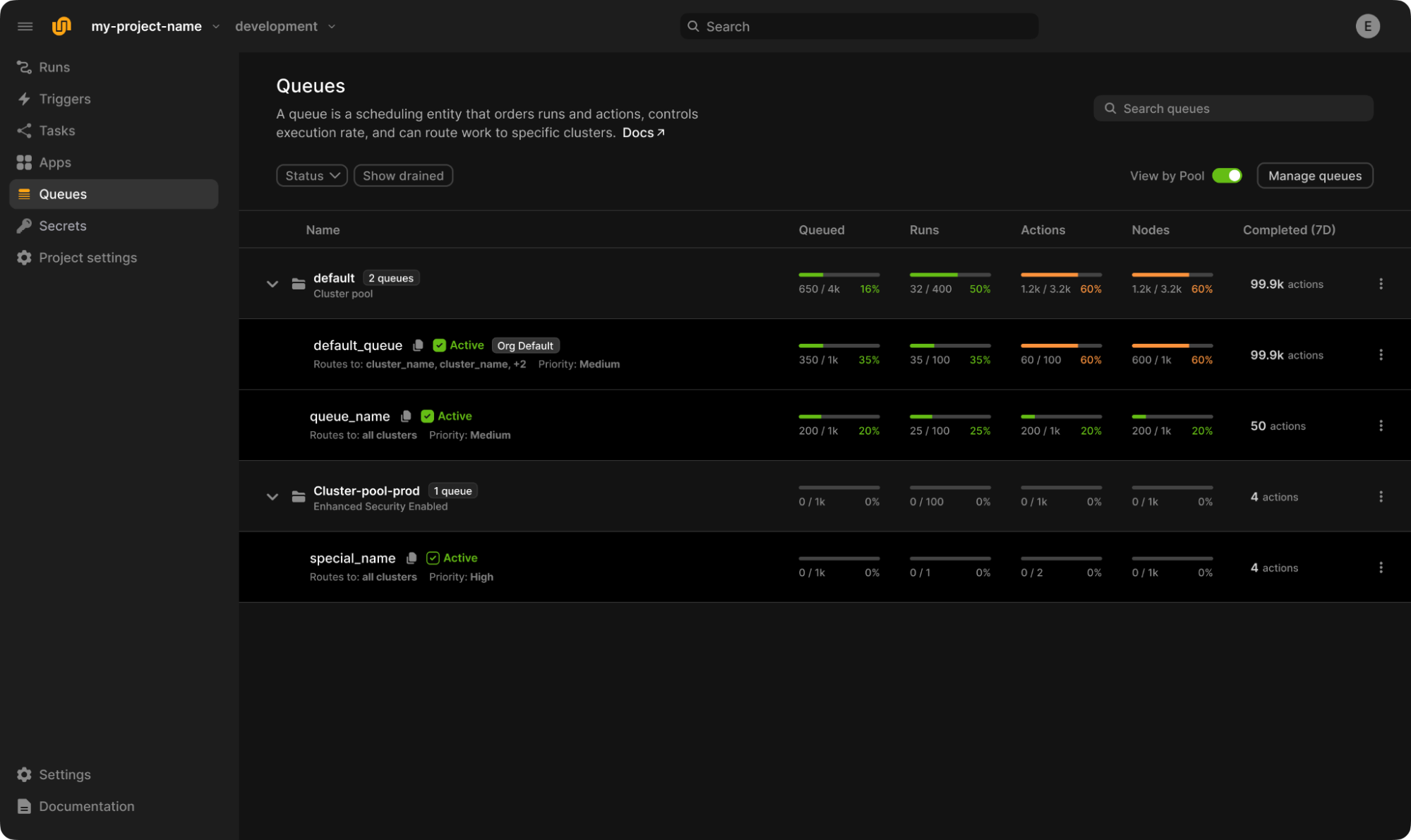
2. Cost-Efficiency: Don’t Waste What SLMs Save
One of the strongest selling points of SLMs is cost reduction. SLMs are way less compute-hungry than LLMs.
But here’s the problem. You’re going to light your cost savings on fire if you’re not orchestrating your workflows correctly. In our time working on open-source Flyte, we’ve seen teams burn through budgets because of avoidable mistakes:
- Running a lightweight workload on a GPU instead of a CPU
- Reprovisioning resources from scratch after a failure
- Paying for idle infrastructure between jobs
Modern AI orchestration should be resource-aware, smart enough to match workloads to the right compute at runtime, scale to zero when idle, and recover from errors without starting over. Otherwise, SLM might as well mean Shamelessly Losing Money (did that joke land? I’d be amazed).
3. Accuracy: Infrastructure as a Multiplier
SLMs are often more accurate on narrow, domain-specific tasks than general-purpose LLMs. Like picking a specialty tool instead of a one-size-fits-all option. But accuracy isn’t just about the model itself; it’s about the system surrounding the model.
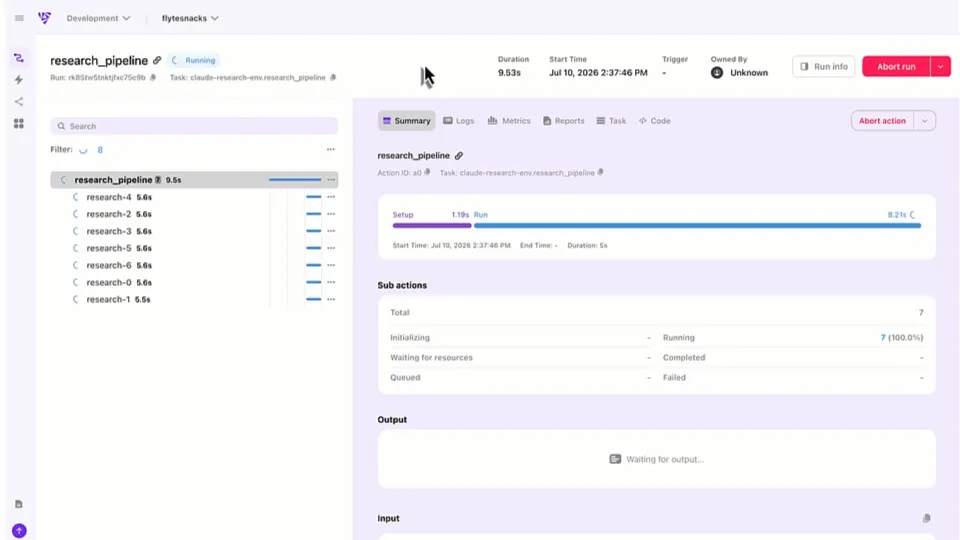
RAG (Retrieval-augmented generation), for instance, combines a smaller model with external data sources to improve its accuracy on specific use cases. But orchestrating this well means:
- Unifying data pipelines, compute environments, and inference tasks in a single workflow
- Handling long-running, stateful processes without brittle failures
- Supporting agents that make runtime decisions about which tools or data to call
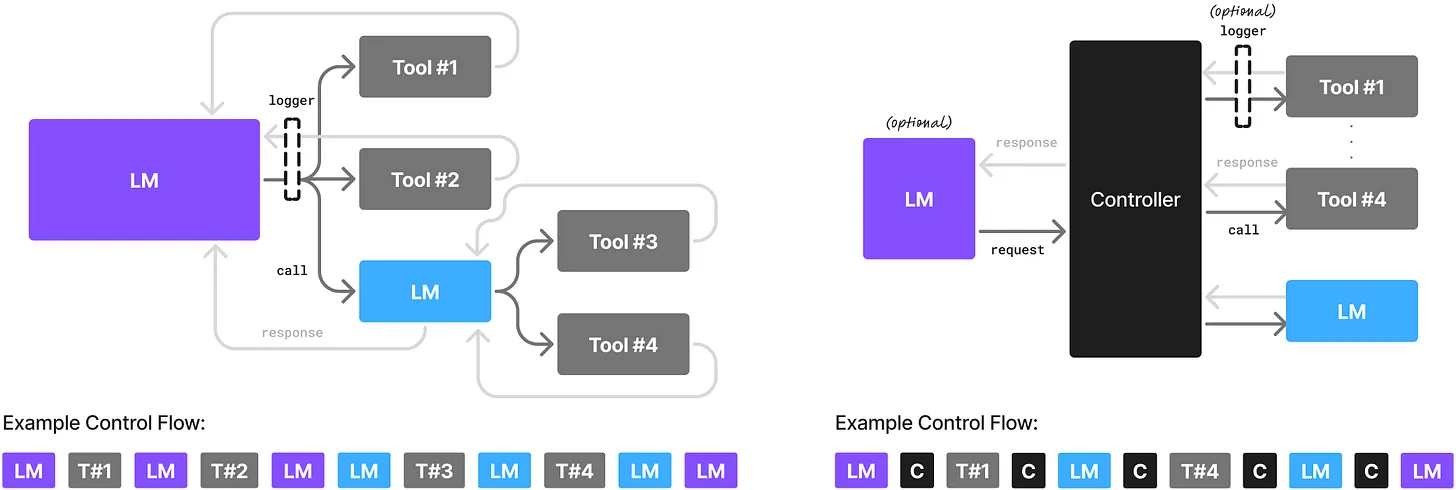
SLMs + AI-Native Orchestration
When orchestration is AI-native, it becomes the central nervous system for your AI development.
AI-native orchestration takes all the goodness SLMs promise and makes it a reality. You sidestep the shortcomings of old-school data orchestrators (or the absolute money pit that is not using an orchestrator at all), and you give your SLM-powered system the sustainability it needs to go from experiment to production. You can build systems that are durable, dynamic, and flexible enough to coordinate the flow of data, models, and decisions.
The hyper-growth startups and big enterprises who have realized this are now measurably outpacing their less adaptable competition. Just in our Union.ai ecosystem, we’re seeing companies like Toyota, Spotify, and Coupang pulling ahead in their AI strategy because they treat AI orchestration as the command center of their systems. In the recently launched Flyte 2.0 beta, engineers are building agentic systems that use AI orchestration as an agent runtime.
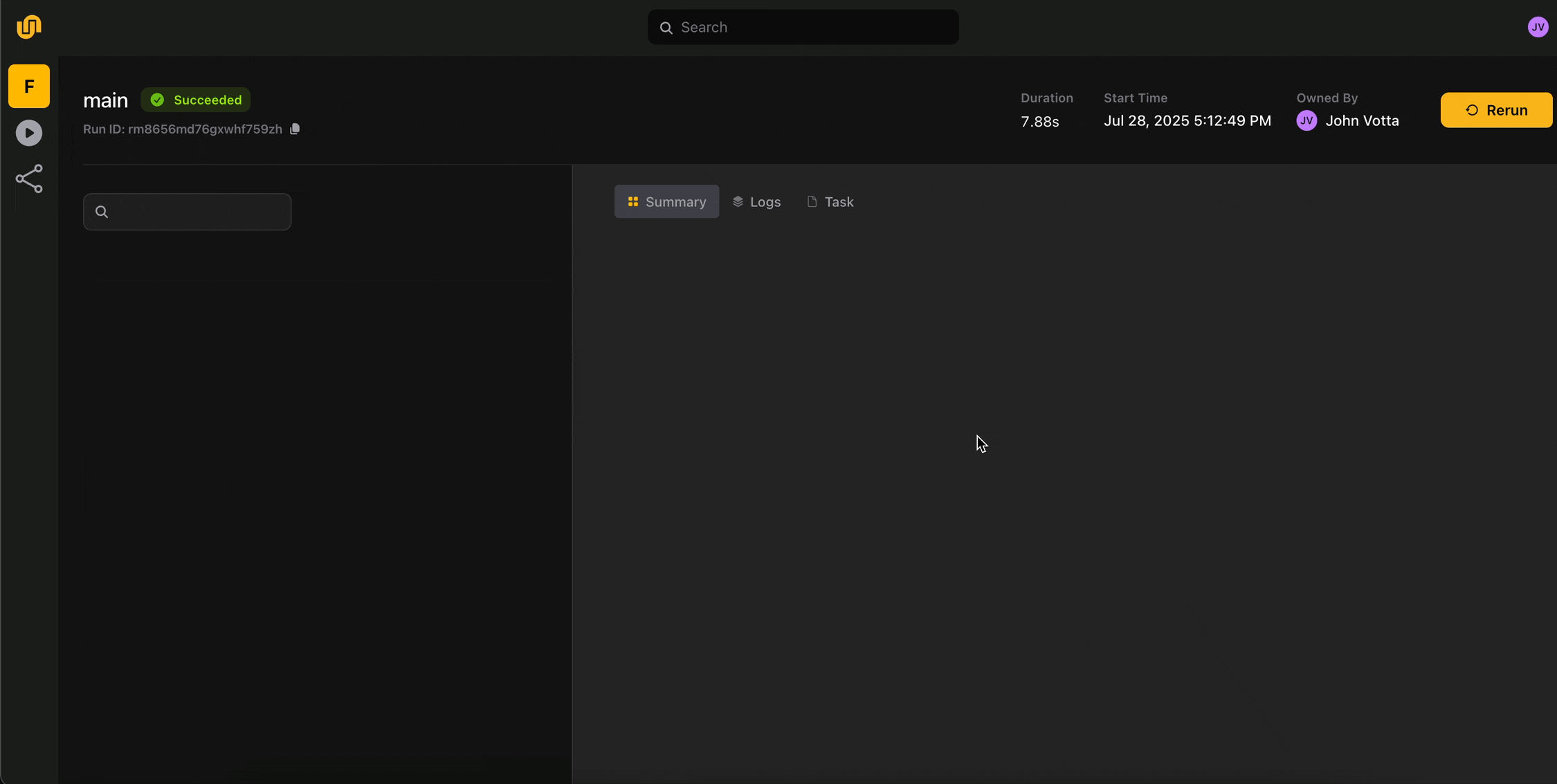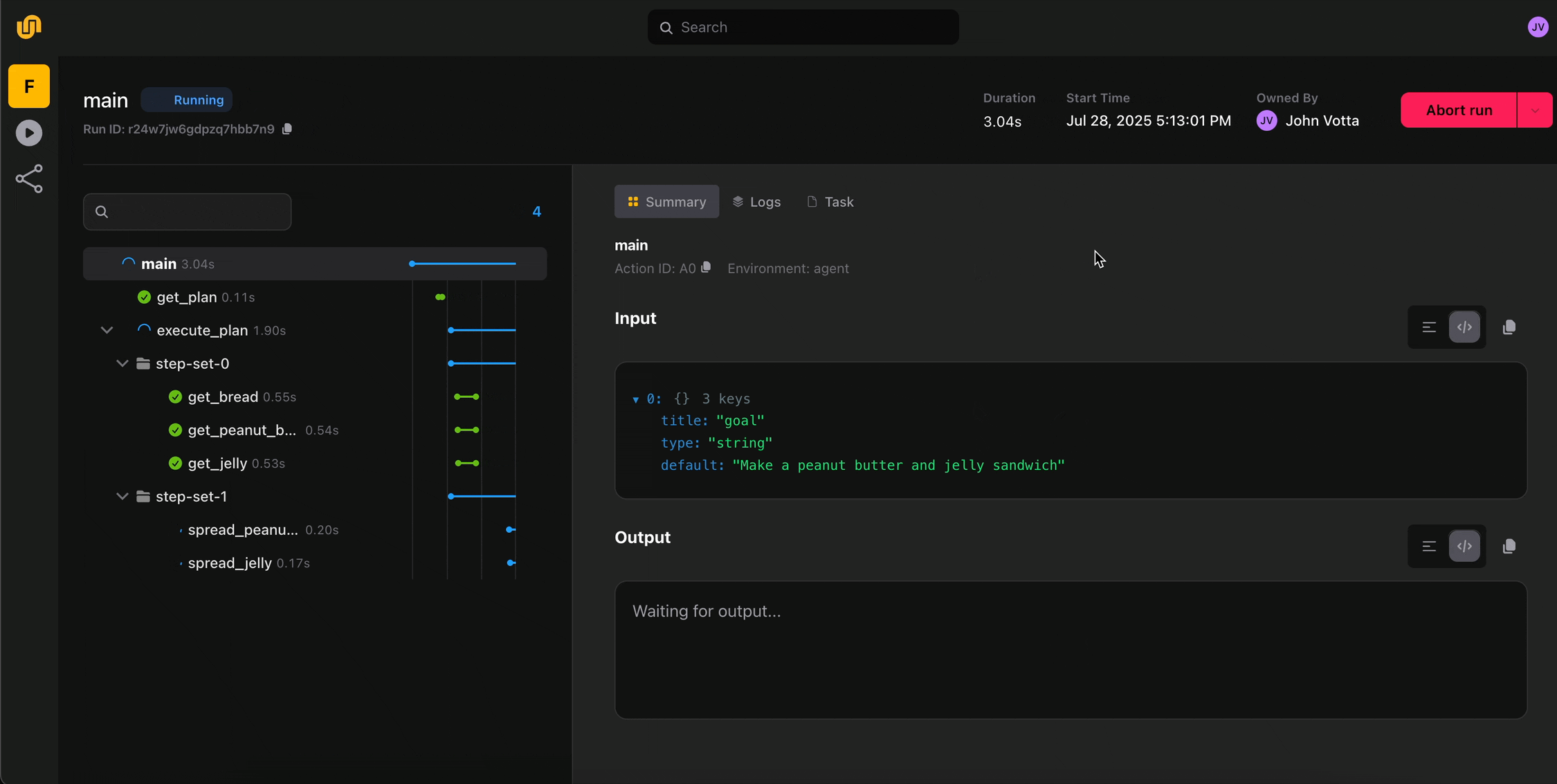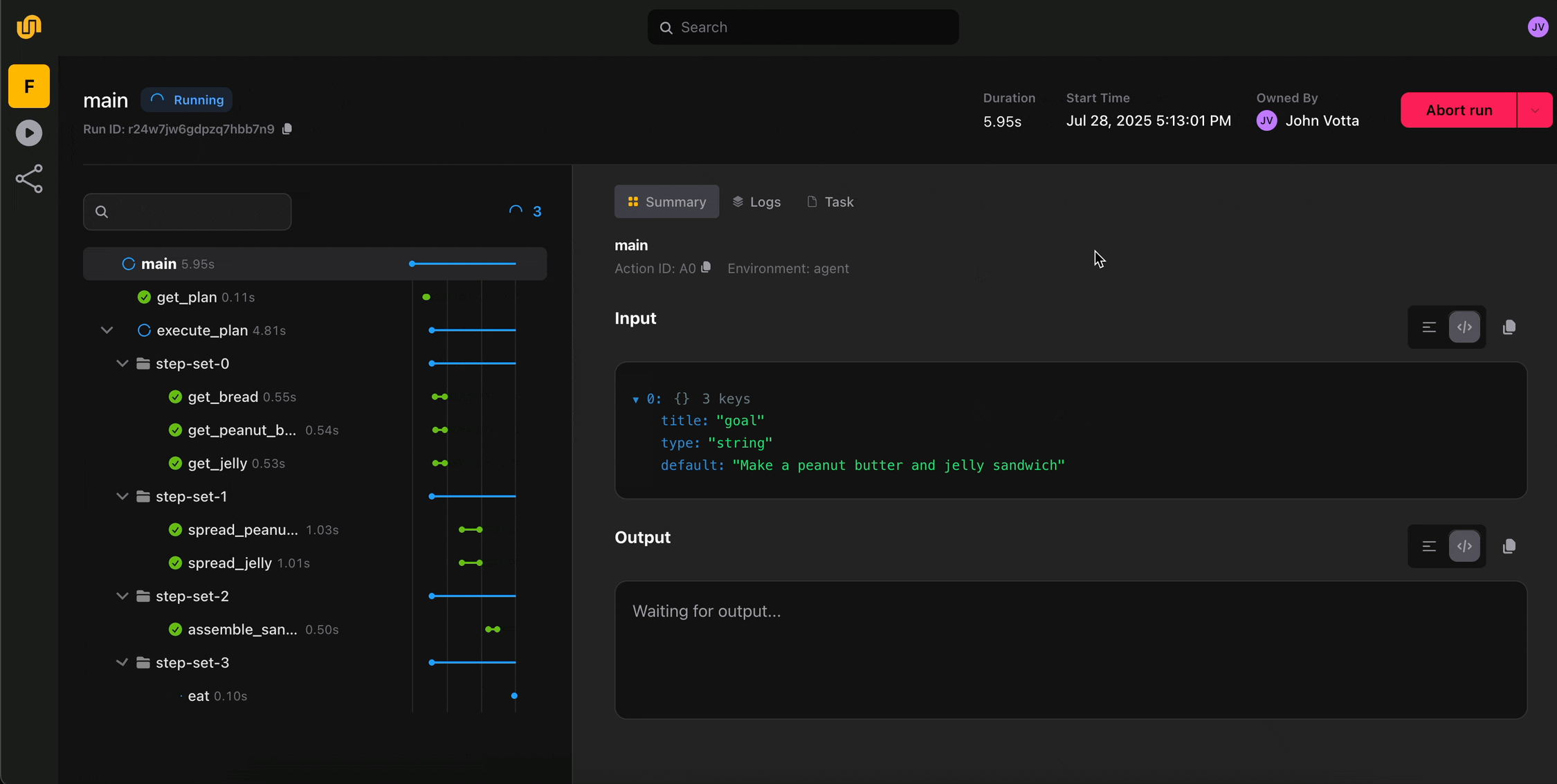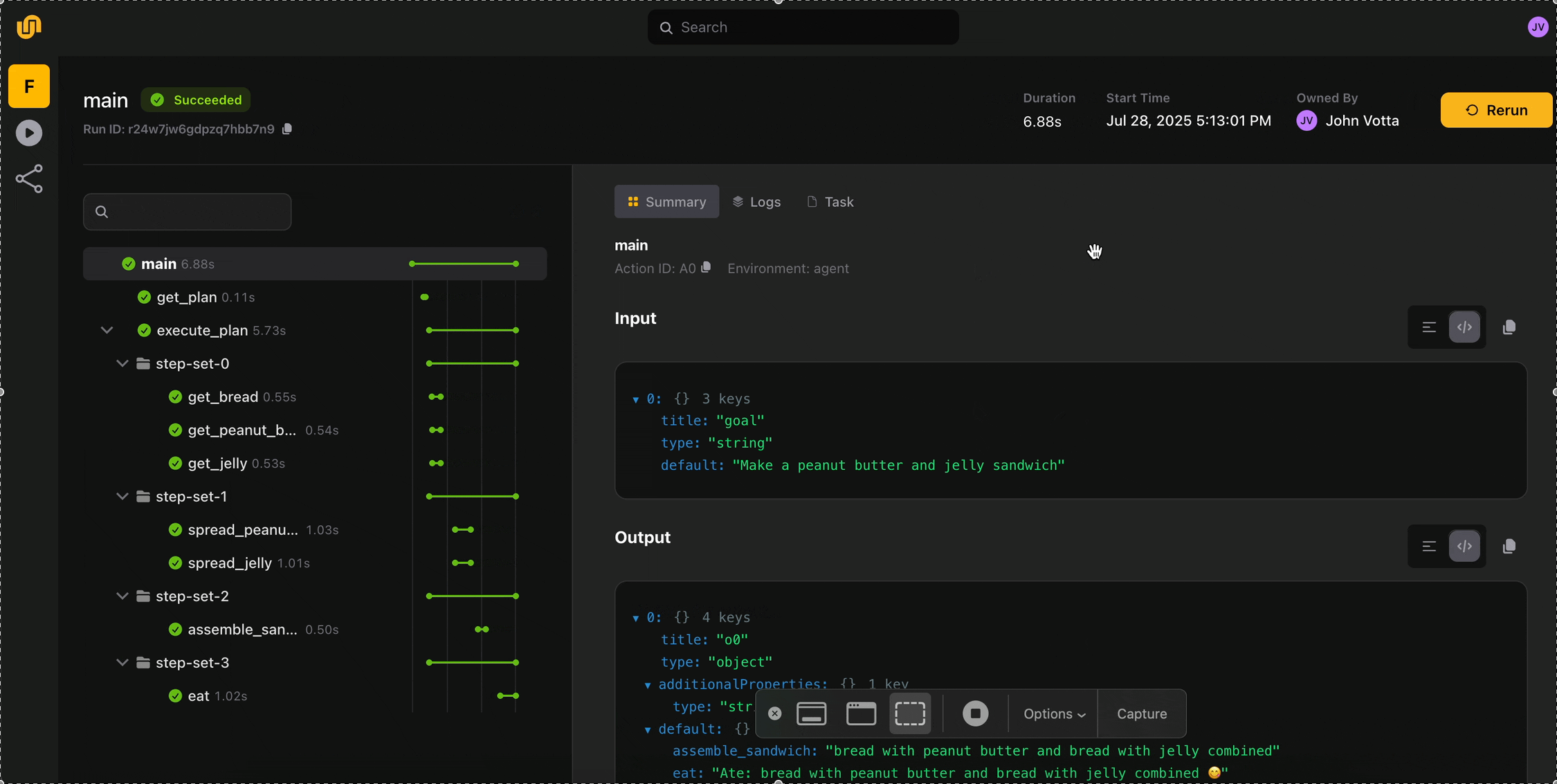
The Bottom Line
Building a production-ready AI system means valuing agility in your model(s) and in your AI infrastructure. As AI engineers step up their game, SLMs can be a great way to move from experiment to production. They’re more nimble and affordable when deployed the right way.
The right way means the right orchestration strategy. AI-native orchestration compounds the value of SLMs for the engineers savvy enough to recognize the advantages.
The future of AI won’t be decided by who has the biggest models, but by who builds the strongest foundations.
Thanks for reading The AI Loop! We’d sincerely appreciate if you shared this post.
<div class="button-group is-center"><a class="button" target="_blank" href="https://unionailoop.substack.com/p/so-you-want-to-use-slms-can-you-really?utm_source=substack&utm_medium=email&utm_content=share&action=share">Share</a></div>