Summary
- Developing AI workflows locally, then deploying to remote environments can lead to problems and slow downs. This is often due to differences in configuration, infrastructure, and permissions between the two environments.
- Interactive Tasks, originally contributed as FlyteInteractive to the Flyte open source project by LinkedIn Engineering, addresses these challenges by enabling users to interactively debug remote executions.
- In Union, Interactive Tasks offer a fully-integrated way to debug remote executions through a VS Code IDE or Jupyter notebook securely hosted in the dataplane and routed to the UI.
Local versus Remote Execution
The AI development lifecycle is often a tale of two environments. Development starts in a local environment, where practitioners define initial code logic, validate the shape of their workflows, and test on small datasets. After this phase, they are run in a remote environment, where users can scale up workloads in the cloud, leverage larger or more secure data assets, and bring their workflows closer to production. While this paradigm helps users get initial workloads off the ground relatively quickly (perhaps using local notebooks for fast iteration), problems can arise due to the differences between local and remote environments. These can include:
- Image management: The process of building images, pushing images to a remote image registry, and pulling images down into the execution can sometimes introduce overhead, especially when dealing with large images containing AI-oriented dependencies like torch. Permissions must be properly configured between the local environment, the image registry, and the remote execution service.
- Infrastructure differences: Local environments are typically single-machine and may or may not include specialized hardware such as GPUs, while remote environments may scale out to multi-GPU machines or multiple machines. Bugs that emerge due to the complexities of distributed environments may only appear once the execution is run remotely.
- Access and Security: Local executions may not have access to large-scale and/or production data assets, so issues that arise only when operating on production data may be difficult to debug locally. Similarly, local systems may not have access to secured or third-party APIs which require secrets only available to the remote environment. Remote executions can therefore be required for end-to-end testing.
Local-Remote Parity with Flytekit
At Union, we are developing tools that minimize the gap between local and remote execution. While the gap is difficult to remove entirely, the `flytekit` SDK contains the following features in this vein:
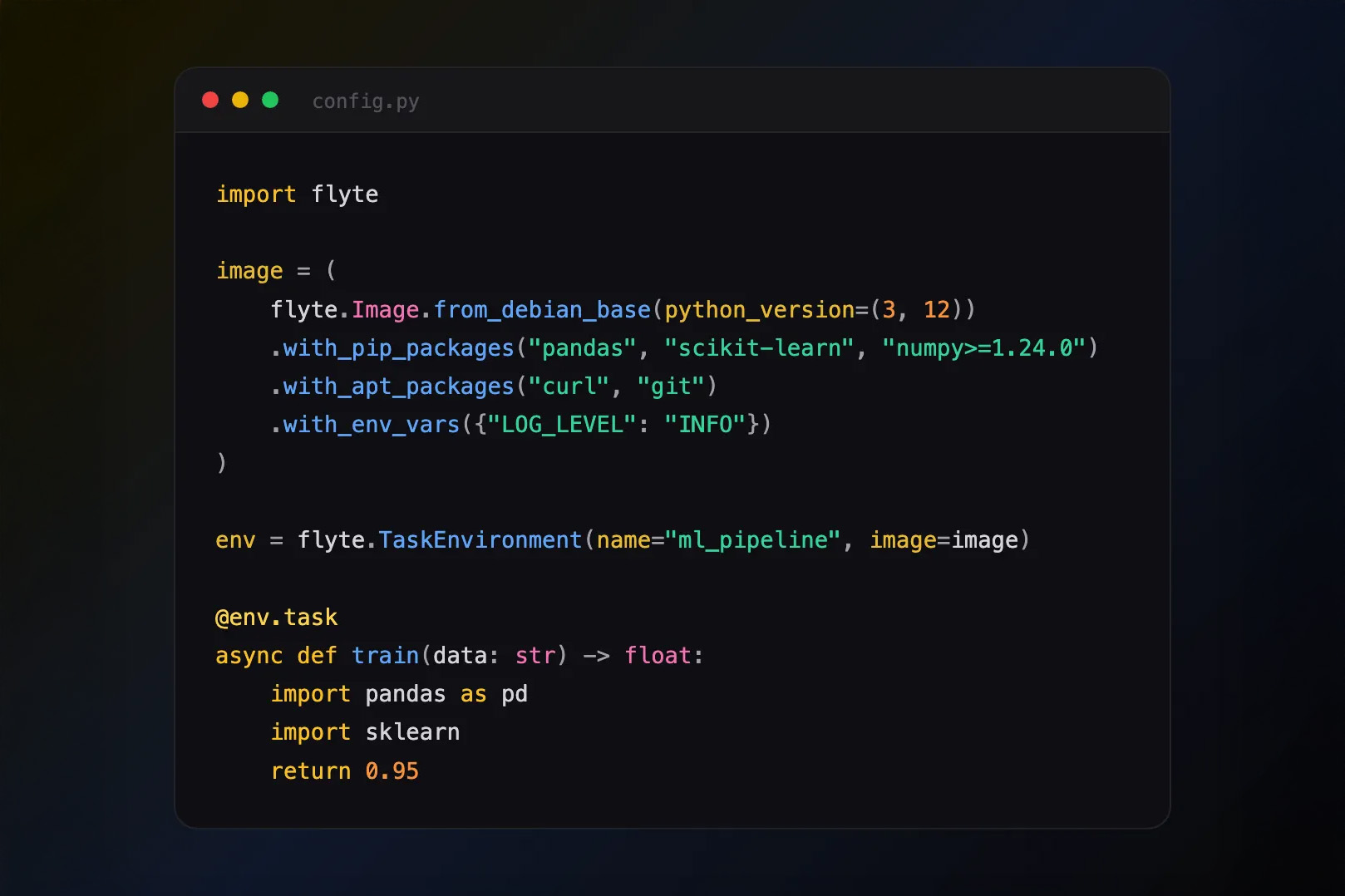
- ImageSpec: Instead of requiring users to write Dockerfiles, build, and push images separately, ImageSpec allows users to define dependencies in code and directly map images to the Flyte tasks which will use them to create containers. Images are then built on the fly (if necessary) and automatically referenced by remote workflows.
- Local Execution: Flyte workflows are written in a Pythonic SDK and can be run locally in Python. The same code can then be run remotely with all the benefits of a cloud-scale workflow orchestrator, including containerized tasks, automatic data offloading to object store, caching of inputs and outputs, and more.
- Agents: Flyte Agents make use of the Flyte Agent framework for orchestrating calls to third party services, are written in Python, and can be run locally. This means that even complex computations managed by distributed compute providers such as Snowflake and Databricks can be run locally, greatly reducing the gap between local and remote execution.
While these features improve the ergonomics of local and remote development, in many cases there is no substitute for being able to directly interact with the remote environment. For example, large data processing jobs may scale out to many Spark executors. ML training jobs may rely on multi-GPU nodes. Bioinformatics use cases may require huge amounts of memory to perform sequence alignment. In these situations, being able to introspect into the remote environment can be invaluable.
Introducing Interactive Tasks
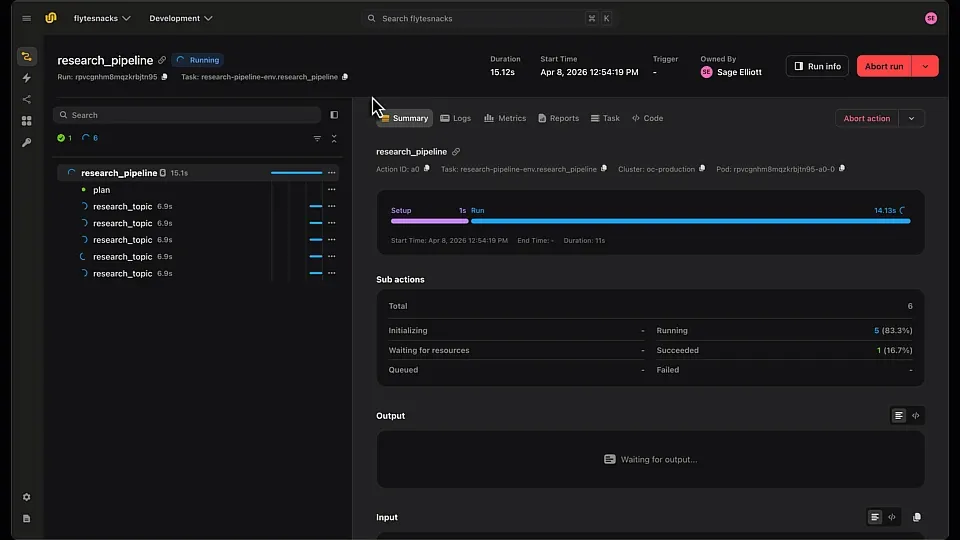
With Interactive Tasks, users of Union can now attach a VS Code IDE to a running remote execution and interactively debug the job. Users can add the `@vscode` decorator to any task, trigger a remote execution, navigate to the execution in the UI, and click `vscode` in the right sidebar of the task. At this point, a VS Code IDE will load in a new tab, enabling the user to edit code, set breakpoints, and step through line-by-line to develop remotely.


This feature allows users to interactively debug any remote execution, even those leveraging cutting-edge AI frameworks like CUDA, torchrun, or multi-node Ray. Most significantly, the data context is maintained. This is especially important to AI workflows where data is as important, or more, than the code. This ability significantly shortens the development lifecycle, which previously might have required many steps to affect even minor code changes. This dramatically improves development velocity by enabling users to experiment at scale in near-production environments.
Interactive Tasks Demo
The following example shows how users can leverage Interactive Tasks in their development workflow.
Source repository: github.com/jpvotta/union_demo/tree/main
First, import the necessary dependencies. Note the dependency on `vscode` from `flytekitplugins.flyteinteractive`:
Next, define an ImageSpec, `custom_image`, which points to the `requirements.txt` file defined here.
Note that `registry` can point to any registry that both your local environment and Union have access to. In this example, we are using GitHub Containers. To run this code, ensure there is an environment variable (`DOCKER_REGISTRY`) pointing to a GitHub container repository. This can be done by running a command such as:
Finally, define a workflow that generates a dataset, trains a model, and calculates the loss:
Note that we have added `@vscode(port=8080)` below the `@task` decorator for the train_model_and_calculate_loss task in the workflow.
In order to run the workflow in a Union cluster, ensure the Docker daemon is running and run the following:
At this point, the image containing torch and the other dependencies is built locally, pushed to GitHub Containers, and automatically pulled down into the containers running the `get_data` and `train_model_and_calculate_loss` tasks.
Navigating to the URL displayed in the console opens up the execution in the Union UI:
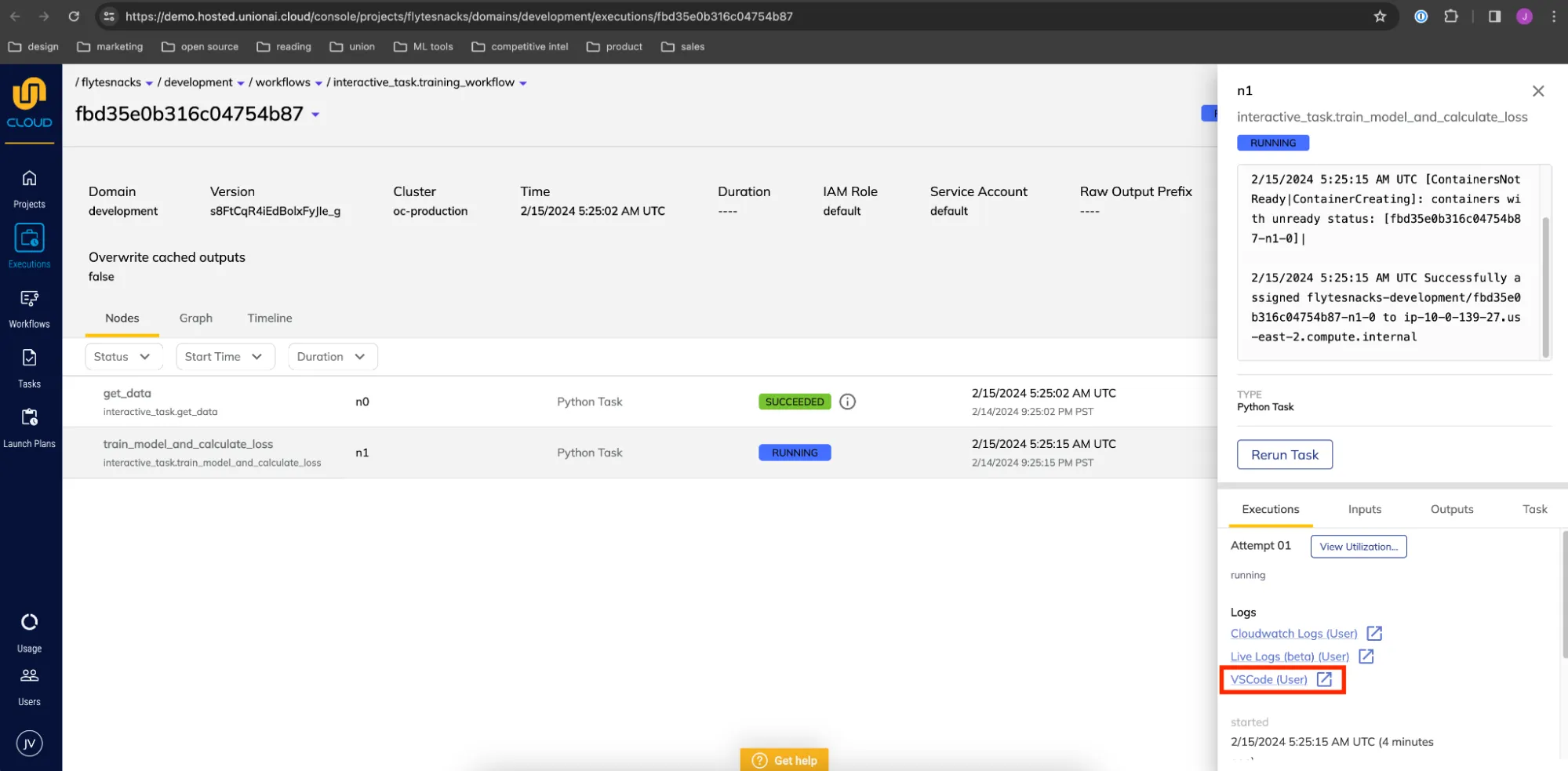
Clicking `VSCode (User)` in the right sidebar opens the code editor. You can set breakpoints within the task code like so:

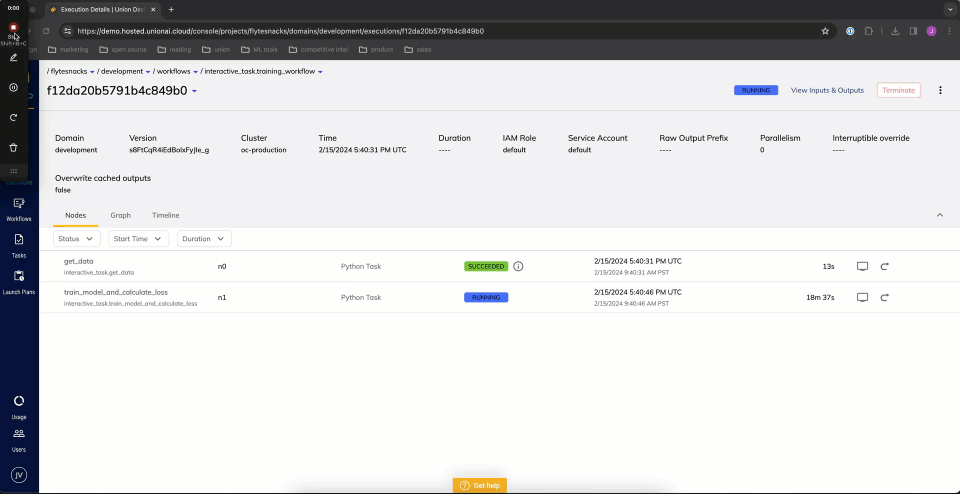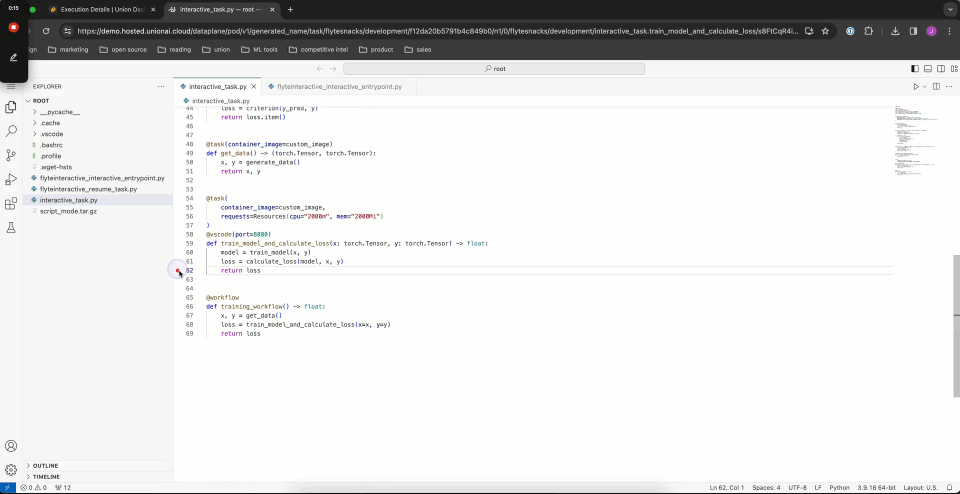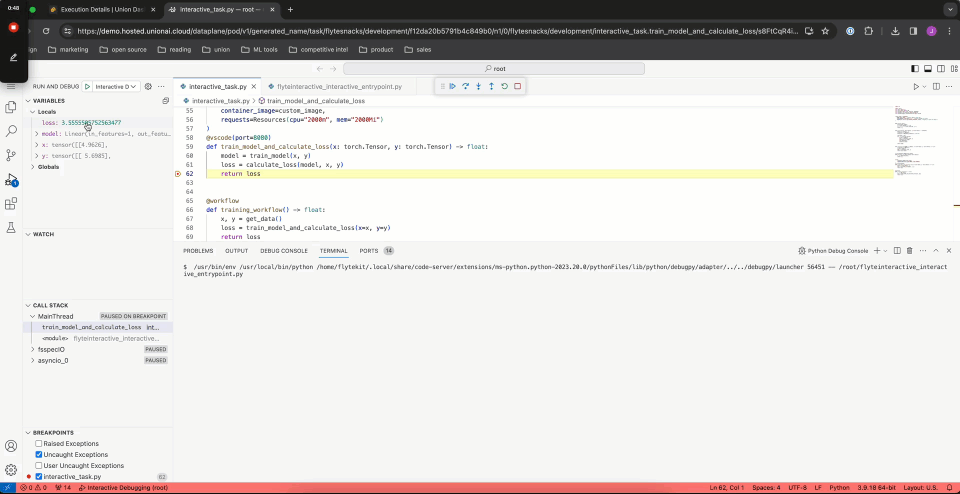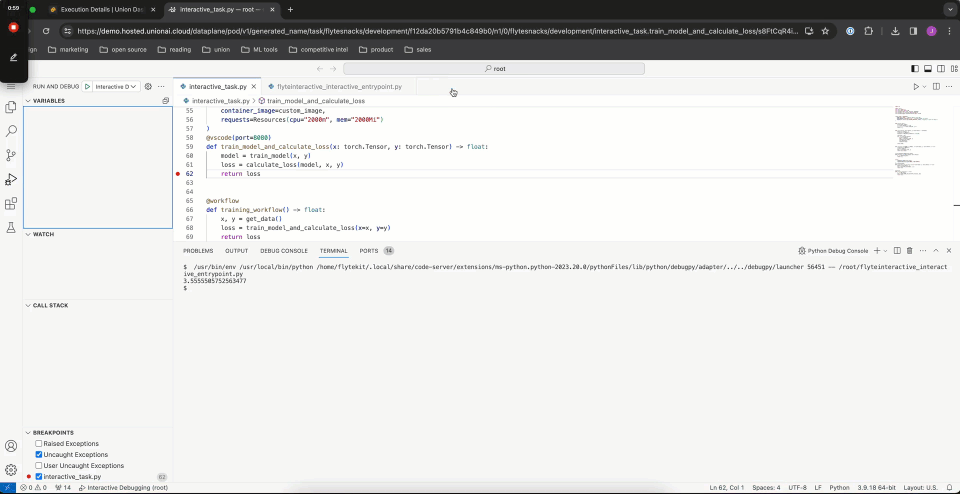
In order to debug, navigate to the automatically-generated `flyteinteractive_interactive_entrypoint.py` file and click the play button next to "Interactive Debugging":

Running the task in debug mode causes the breakpoint to be hit. Full debugging functionality is available, including variable inspection.

A task execution annotated with `@vscode` will be kept alive for 10 hours after the last user interaction. The timer resets if a user interacts with the IDE. Be sure to terminate or complete the execution once finished debugging to avoid cloud provider charges associated with long-running pods.
Conclusion and Credits
Interactive Tasks in Union offer a fully-integrated way to develop at scale by enabling direct access to remote executions. By side-stepping many of the repeated steps in the local to remote development process, this feature enables users to accelerate their development velocity and bring AI products to production faster. To learn more about Union, visit union.ai.
The core functionality of Interactive Tasks, as well as the example adapted for this blog post, was developed as FlyteInteractive by the LinkedIn Engineering team and donated to the Flyte open-source project. Flyte relies on strong contributions like this from the community to continue to evolve as a leading AI orchestration platform. To learn more about Flyte, please visit flyte.org.
See Also
- LinkedIn team demo of FlyteInteractive at the Flyte Community Sync: youtu.be/YFaM-y8UWIo?feature=shared&t=3768
- LinkedIn example repository for FlyteInteractive: github.com/troychiu/flyteinteractive_demo/tree/main
- FlyteInteractive documentation: docs.flyte.org/en/latest/flytesnacks/examples/flyin_plugin/index.html
- VSCode decorator documentation: docs.flyte.org/en/latest/flytesnacks/examples/flyin_plugin/vscode.html