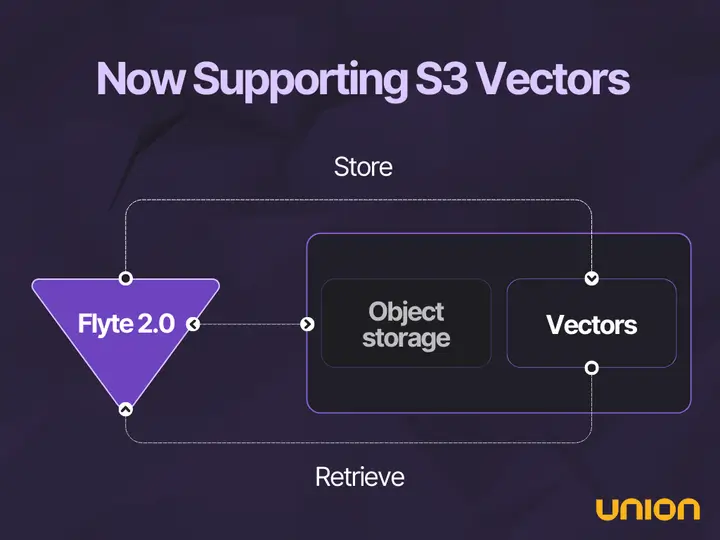
Amazon S3 Vectors is the first cloud object store with native support for storing and querying vectors. That’s a big deal; no need for a separate vector database if you’re already on AWS. And it's cost-effective too. AWS claims up to 90% cost reduction compared to traditional options.
If you’re using Flyte or Union on AWS, chances are you’re already leveraging S3 as your object store. Now with native vector support in S3, adding vector storage support to your workflows is effortless.
The fastest way to build agentic apps
Flyte 2.0 introduced a flexible agentic runtime built specifically for modern AI workflows: RAG, semantic search, multi-agent systems, and more. The best part is if you're using Flyte 2.0 today, you can start using S3 Vectors right away.
To set it up:
- Use Boto’s dedicated APIs to store and query vectors.
- Your S3 IAM roles are already in place. Just update permissions.
Get up to speed on Flyte 2.0 with this overview.
What does this unlock?
Let’s walk through an example. Say you’re building a multi-agent trading simulation – one of our more advanced tutorials. You’ve got multiple agents interacting with each other, simulating strategies, learning from experience.
To make this realistic, you’ll want each agent to retain “memories”, its learnings from previous iterations. These aren’t just logs; they’re semantic artifacts the agent should refer back to in future steps.
What’s the best way to store those? Vectors make the most sense.
After each round:
- Embed the agent’s learnings into vector representations
- Store them in S3 using S3 Vectors
- Retrieve them later during subsequent executions for contextual grounding
With Flyte 2.0, your agents already run in an orchestration-aware environment. And now, S3 becomes your vector store: cheap, fast, and fully native. No need to plug in another database.
In the multi-agent trading simulation example, we show how to:
- Create a vector bucket if it doesn’t already exist
- Set up an index
- Generate OpenAI embeddings and store vectors
- And query those vectors, all using Amazon S3 Vectors
You can check out the full setup code in trading_agents/memory.py from the unionai-examples repo.
These methods can be called directly from a Flyte task with no extra boilerplate needed. If you’re using Flyte’s `reusable` policy, you can wrap the boto3 client setup in an `@alru_cache` for even better performance.
And because you control exactly what goes into and comes out of the vector store, it’s easy to track. For even more observability, you can wrap your calls with `flyte.trace`. Say you're querying vectors during agent execution, just trace it. It’s a lightweight way to get fine-grained visibility inside a task. Here’s how it works.
Less tooling, more power
The combo of Flyte 2.0 and S3 Vectors means less fragmentation. You don’t need separate vector DBs or integration layers. Just the tools you’re already using, now doing even more.
And don’t forget: Flyte 2.0 is deeply extensible. You can integrate just about any tool or library: from LangChain to Spark to OpenAI agents, and if you need a lower-level integration (like neoclouds or distributed training), Flyte’s SDK and plugin system make it possible.
Want to go deeper?
We’re actively exploring deeper native integrations for S3 Vectors to make things even smoother. If you're experimenting with S3 Vectors, or want to plug it into a Flyte 2.0 pipeline, we’d love to collaborate!