The only AI runtime that runs in your cloud, not ours.
One platform to orchestrate durable AI workflows, real-time apps, and compute optimization. Your data never leaves your infrastructure.





Results, proven in production.














Accelerate pilot to production
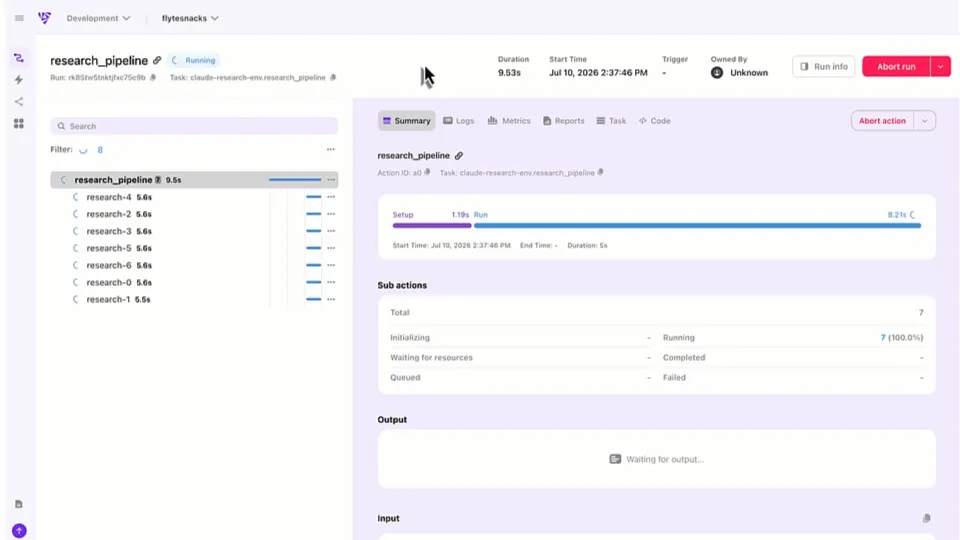
Build high-velocity workflows with dynamic AI orchestration, real-time inference, and infra-awareness.
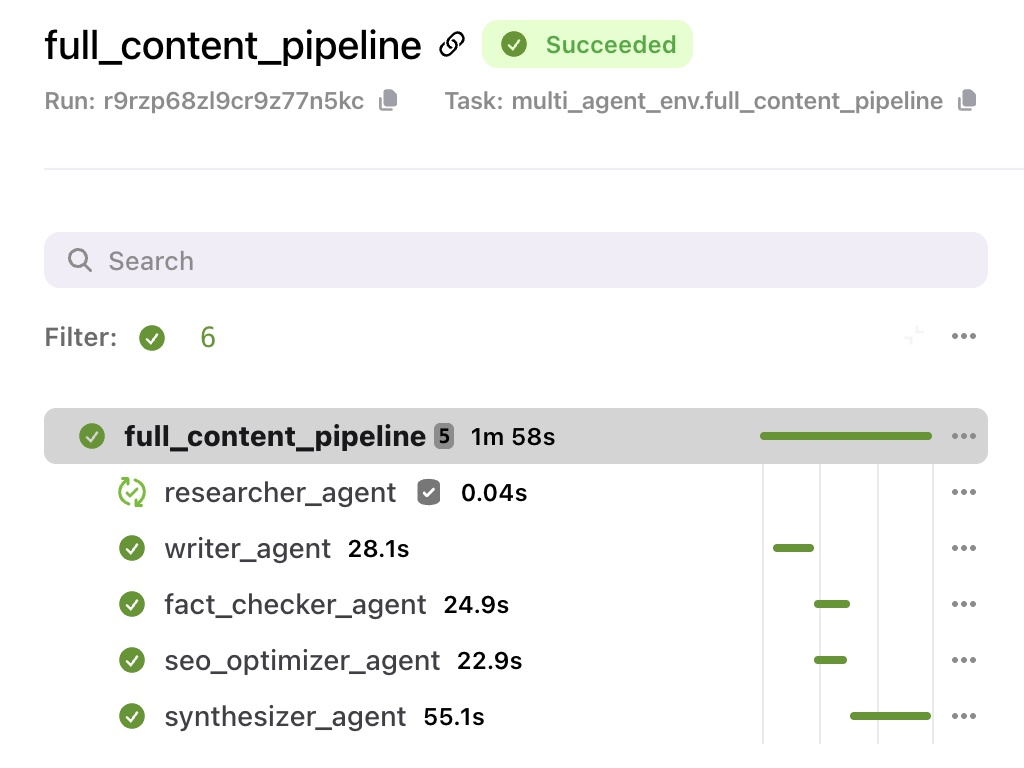
Reliable, reproducible workflows
Automatic failure recovery, caching, and versioning. And a developer-loved debug button.
Zero Trust security architecture
Your data never transits our infrastructure. Workflow inputs, outputs, logs, and code bundles are served directly from inside your own cloud.
Dynamic workflows & agent runtime
Author in pure Python and enable on-the-fly branching, loops, and error-handling.
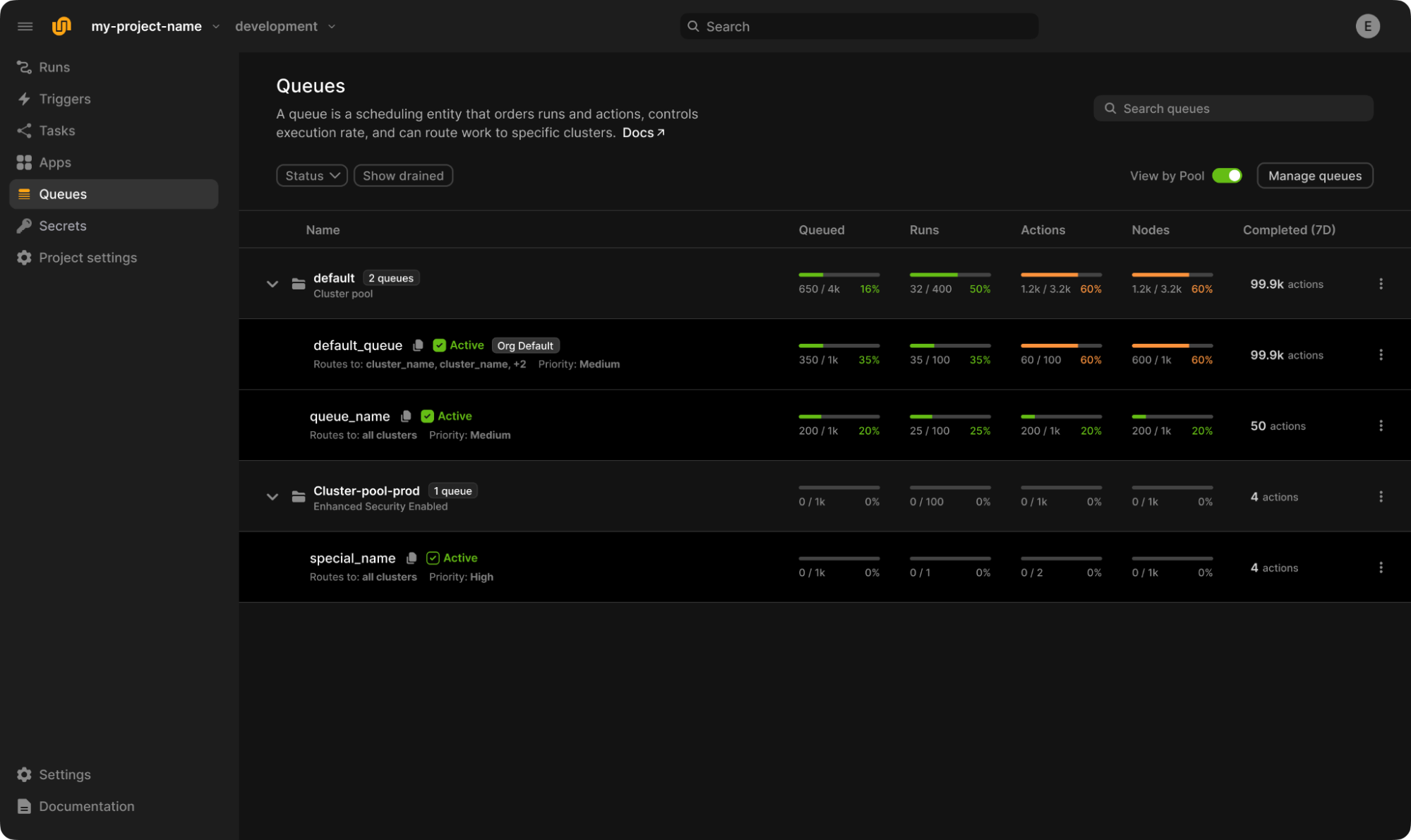
High performance, low latency
Scale to 50k+ actions/run, achieve <100ms task startup time, and provision jobs dynamically.
Develop anywhere, run anywhere
Build workflows locally, then run them remotely and securely in your own cloud(s).
Unify your AI infrastructure.
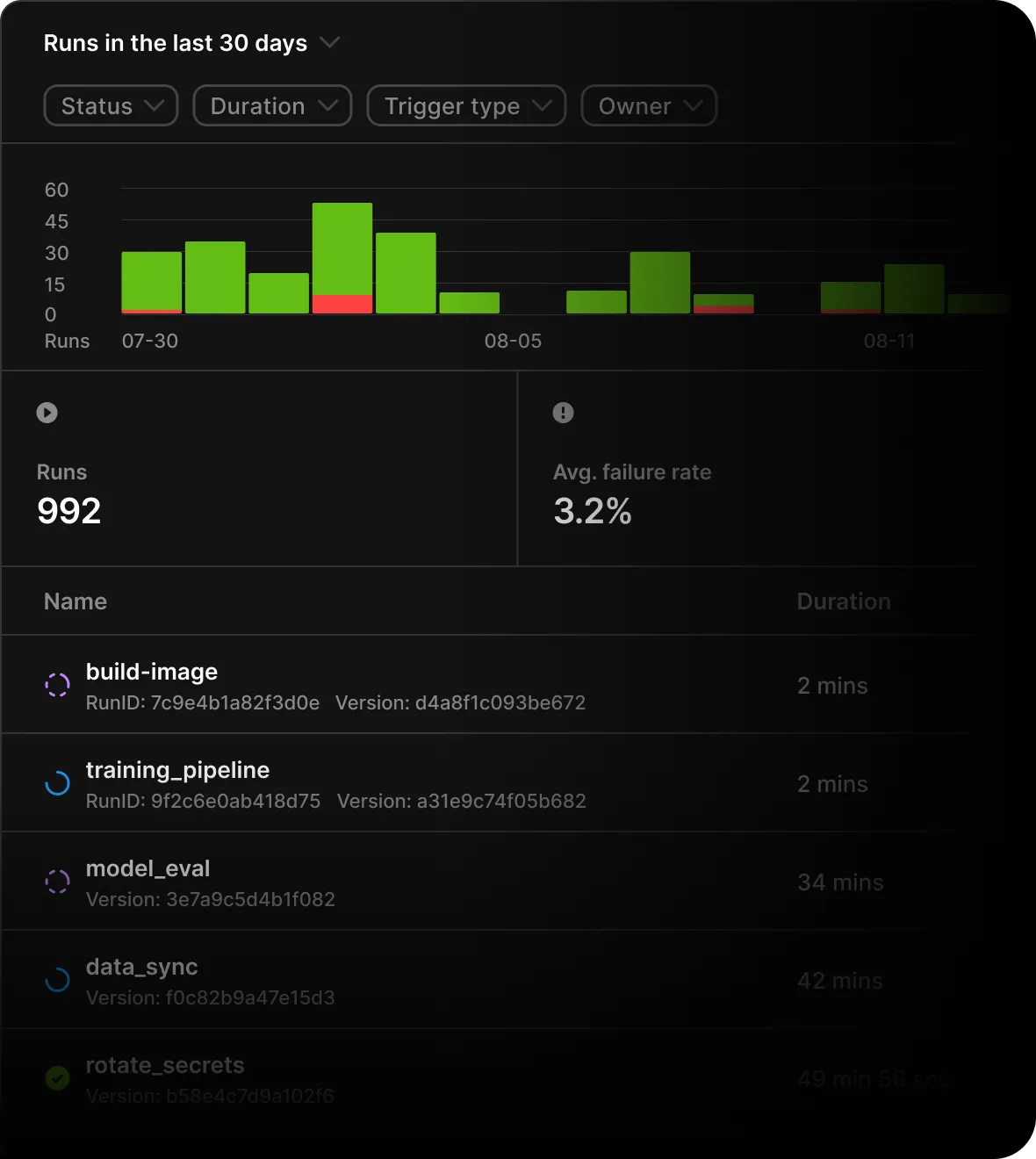
Learn the latest about Union.ai and Flyte
Union.ai achieves 9.8x ROI according to analysts.
