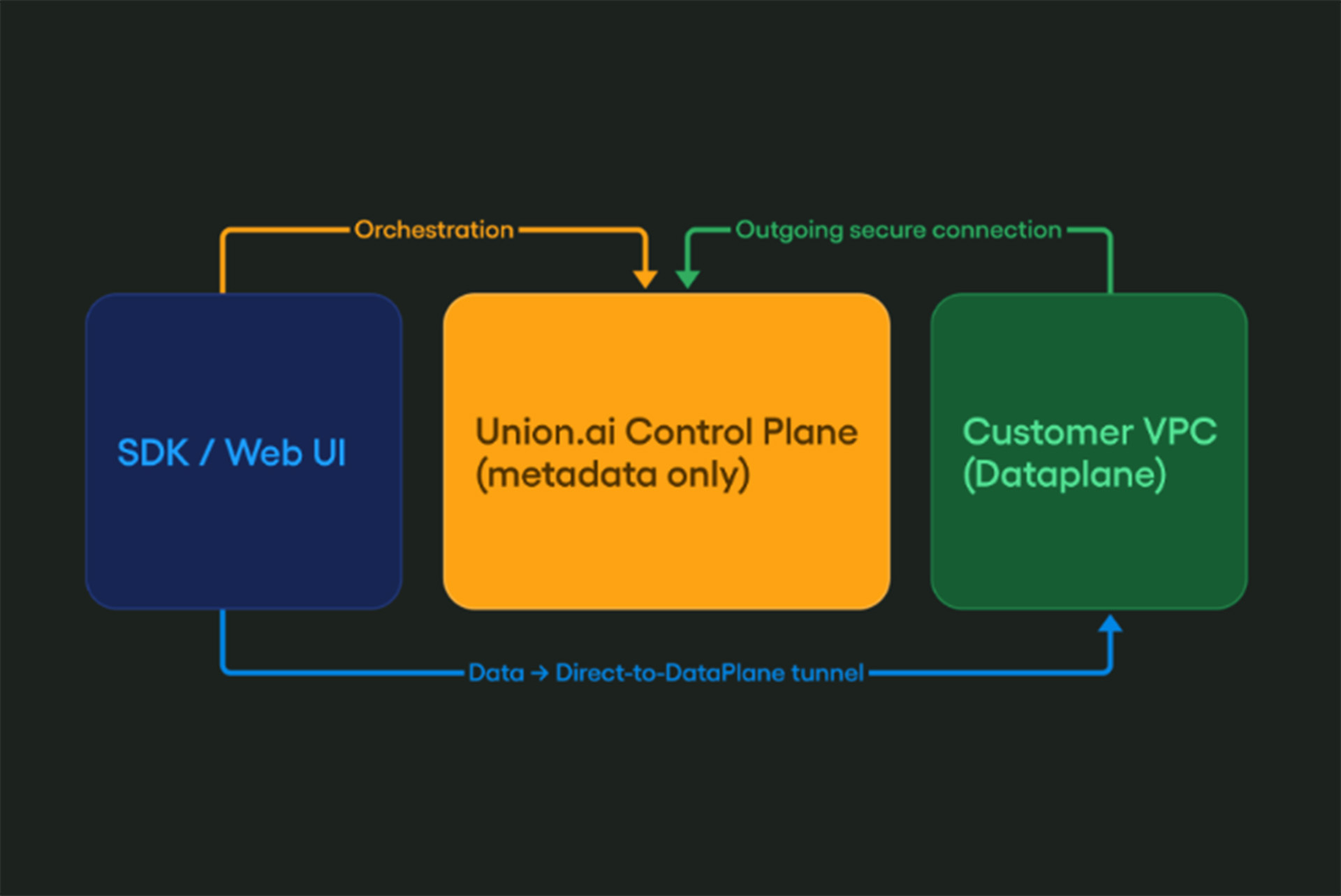
I founded Union.ai with a singular mission: to make orchestration of machine learning so easy and repeatable, teams of any size can use it to create products and services.
That mission is itself the product of years spent working across industries ranging from banking to high-frequency trading and logistics. Along the way, I’ve had a chance to deliver complex software products that integrate data pipelines and ML.
Those experiences shaped my understanding of ML and data products. Initially, I approached their development with the rigor of a software engineer. Then I realized a fundamental difference: Software engineers need to make systems that last, while ML and data science must be transient enough to support fast-changing business requirements.
ML products start with experimentation and quickly transform into production software that changes in response to new demands from the businesses they support. Recognizing this gap, my team and I created Flyte, an orchestration platform that melds the rigor of the engineering process with the Data Scientist's highly iterative needs.
Lyft and other large organizations have adopted Flyte for mission-critical ML workflows. With the release of Union Cloud — a managed version of Flyte — Union.ai is making this technology accessible to every organization that wants to build world-class MLOps platforms.
In this post, I’ll describe the personal journey that led me to bootstrap Union.ai.
Lessons in ML
As a rookie engineer at Amazon 15 years ago, I was enthralled by the endless possibilities of distributed systems, services that could grow to thousands (now, it’s millions!) of requests per second, and novel database architectures. But eventually, I discovered that achieving scalability in production is far more challenging than writing distributed algorithms.
Among other capabilities, we needed deployment pipelines, monitoring, observability, and pager duty to handle tradeoffs between services and ensure they converged behind a robust solution.
I recall the hurdles we faced to deliver Amazon's most extensive scaling services at the time. Building services is considerably easier today: We've figured out how to engineer stateless and efficient services at any scale. Thanks to cloud providers and vendors, databases are profoundly available, scalable, and simple to use.
When I joined Lyft in 2016, my team was tasked with delivering high-quality ML models at a regular cadence. We soon realized that the existing tooling was not in line with how modern ML and data applications are built and delivered.
Productionizing a data-driven ML product at Lyft, I faced the tension between engineering best practices and the highly iterative, experimental nature of machine learning. Initially, I approached the task with the rigor of software, trying to fit existing solutions to solve my team’s problems. Only after careful observation and years of failure, I realized that delivering ML products is fundamentally different from delivering pure software products.
ML projects are often hindered by procurement of infrastructure, the inability to experiment, and measurement of outcomes. Compared with software development, the production of ML models is often more art than engineering; models and data are interdependent and mutable over time. That reflects a fundamental difference between ML systems and software: More often than not, software matures over time, while ML and data products deteriorate.
More often than not, software matures over time, while ML and data products deteriorate.
ML and data products can be fragile. They require constant iteration and experimentation. As ML models become more complex — requiring heterogeneous, multi-modal solutions with large amounts of training data — it becomes harder to engineer them.
The Birth of Flyte and Union
At Lyft, we responded to these challenges by creating Flyte, a platform for orchestrating ML and data processing jobs. Specifically, the Lyft team launched Flyte in late 2016 to deliver models for a core product — estimated time of arrival (ETA).
Lyft open-sourced Flyte in early 2020, and it joined the Linux Foundation AI & Data as the organization’s 25th hosted project. In earlier posts — Flyte Joins LF AI and Data and From Incubation to Graduation, and Beyond: FlytePath — I discuss how Flyte evolved, the difficulties that necessitated a new workflow automation platform, Flyte's journey from incubation to graduation, and the key characteristics that set it apart. They also offered my perspective on the future of Flyte.
After open-sourcing Flyte in 2020, the world changed. The pandemic impacted all organizations, including Lyft. The Flyte team and Lyft’s ML team at Lyft went through a period of turmoil. Towards the end of the year, I was faced with a choice: I could join a different company to re-do things I had done at Lyft, or continue the work that I had started.
I chose the latter path. I realized many emerging ML product teams faced the same struggle my team had, and I felt my work was undone. I wanted to build a truly open ecosystem that could help them.
I’d never thought about starting a business, but after careful consideration, I felt the best way to move the needle forward was to create a company dedicated to making every ML and data team as agile and efficient as possible. In that effort, I was fortunate enough to connect with the most humble, smart, and long-term focused investors — Scott Sandell and Greg Papadopoulos — who share my long-term outlook and care deeply about open source ecosystems.
Meet Union Cloud
As the Flyte community grew, we observed that many users were having problems setting up Flyte. Once they overcame that initial hurdle, however, adopters were impressed by how well it worked, scaled, and delivered benefits. To encourage a new world of ML products, we want to help teams get started with Flyte quickly and easily.
Specifically, we wanted to address gaps in ML and data security, reliability, and production readiness. And in order to reach a wider audience, we decided to offer a service that would make it much easier for teams to embrace Flyte, learn about the benefits of cloud-native development, and move ahead swiftly.
We recognize the challenges to rolling out open source technology to the enterprise. We want to make it as easy as possible to use Flyte.
So say hello to Union Cloud. Over time, we will add more features that will benefit the community at large, including global sharing, better visualization, and services that will hypercharge their Kubernetes deployments.
We invite enthusiastic partners to join our Union cloud private beta to help us shape our cloud offering and deliver methodical experimentation to your organizations.
Introducing Flyte 1.0.0
Meanwhile, we’ve got big news about Flyte itself.
Union.ai has been and will continue to be the largest contributor to Flyte. We’ll keep innovating to make Flyte the best free and open ML orchestration product around. Today, I am ecstatic to share the official release of Flyte 1.0.0 — a number that represents our confidence in the platform's APIs and stability.
The 1.0.0 release is a significant step forward for the community, but it doesn’t imply that we’ve arrived at our goal. As Amazon frequently states, it's still Day 1.
Furthermore, I am pleased to announce that we are open-sourcing a new framework built on Flyte, codenamed micro-learn. It eliminates the need to think about workflows. Micro-learn provides a unified experience for building machine learning models and deploying them to production with little to no effort. More on this soon!
Join us!
All this activity represents our commitment to a tidal shift in modern software development. Simply put, we expect ML and data products to overtake software as we know it. If this challenge excites you too, join the Union team. We’re hiring!
I want to thank all of the amazing engineers, data scientists, and early adopters of Flyte at Lyft, teams from Spotify Engineering, and many members of the Flyte community. Without your feedback and contributions Flyte would not be possible. Thank you, Nelson, Hongxin, Babis, Gleb (Spotify), Jeev (Freenome), Soren (USU), Kenny (Latch), Jake (Striveworks), Aria (GoJek), Arno (Blackshark), and many more.
— Ketan Umare, Union.ai Founder and CEO