Parallel Audio Transcription: Using Whisper, JAX and Flyte Map Tasks for Streamlined Batch Inference
Samhita Alla
Table of Contents
Table of Contents
Imagine you have a dataset of thousands of audio files that need to be transcribed. Running the transcription process sequentially for each file can be time-consuming and resource-intensive. By leveraging parallel batch inference, you can significantly reduce the overall processing time by transcribing multiple files simultaneously. It also lets you leverage the power of modern hardware, such as GPUs, more efficiently. However, setting up and scaling the necessary infrastructure for parallel batch inference can be a complex challenge to overcome.
In this blog post, we’ll demonstrate how you can use map tasks to perform parallel batch inference efficiently within Union Cloud, the managed offering of Flyte. We’ll also present an experiment we conducted to showcase this approach, using a JAXWhisper model for audio transcription. The end result will be a production-level batch-inference pipeline that can process large amounts of audio data with ease.
We opted for JAX because:
JAX offers seamless scalability to run on one or multiple GPUs.
JAX provides robust support for large-scale data parallelism through its `pmap` function.
JAX encompasses numerous other advantages, including automatic differentiation of arbitrary functions, JIT compilation for performance optimization and automatic vectorization for efficient computation.
Note: The complete code and detailed instructions for running the pipeline can be found on our GitHub repository.
A closer look at batch inference
Batch inference is a technique to process large amounts of data in parallel in order to base predictions on a batch of inputs rather than one at a time. In batch inference, a model is fed a group of data inputs all at once, which allows the system to optimize the processing of the data, reduce latency and improve the efficiency of the prediction process.
Implementing batch processing for inference can be a challenging task in production; it requires careful consideration of how to balance compute resources to avoid out-of-memory errors and optimize the use of specialized hardware like GPUs. Other factors to consider include caching repetitive operations, handling partial execution failures without needing to start from scratch and monitoring resource utilization. Building all of these features from scratch can be a time-consuming and tedious process.
Google Colab and Kaggle Notebooks are excellent environments for prototyping machine learning models — but running inference pipelines at scale requires a reliable infrastructure is needed. That's where Union Cloud comes in: It provides a robust platform for running batch inference pipelines at scale. In this post, we'll show you how to create Flyte workflows that use map tasks to run a Whisper JAX model on a V100 GPU. So let's get started!
But first, Whisper PyTorch in a single container
JAX and PyTorch are both widely used deep-learning frameworks, but JAX can often provide better performance than PyTorch. Before we move on to running Whisper JAX on Flyte, let's first run the Whisper PyTorch pipeline on Flyte.
Copied to clipboard!
import json
import os
import numpy as np
import requests
import torch
from flytekit import Resources, task, workflow
from flytekit.types.file import FlyteFile
from transformers import pipeline
from transformers.pipelines.audio_utils import ffmpeg_read
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:512"
@task(requests=Resources(gpu="1", mem="15Gi", cpu="2"))
def torch_transcribe(
checkpoint: str,
audio: FlyteFile,
chunk_length: float,
batch_size: int,
return_timestamps: bool,
) -> str:
pipe = pipeline(
"automatic-speech-recognition",
model=checkpoint,
chunk_length_s=chunk_length,
device="cuda:0" if torch.cuda.is_available() else "cpu",
)
local_audio_path = audio.download()
if local_audio_path.startswith("http://") or local_audio_path.startswith(
"https://"
):
inputs = requests.get(inputs).content
else:
with open(local_audio_path, "rb") as f:
inputs = f.read()
if isinstance(inputs, bytes):
inputs = ffmpeg_read(inputs, 16000)
if not isinstance(inputs, np.ndarray):
raise ValueError(f"We expect a numpy ndarray as input, got `{type(inputs)}`")
if len(inputs.shape) != 1:
raise ValueError(
"We expect a single channel audio input for AutomaticSpeechRecognitionPipeline"
)
prediction = pipe(
inputs, batch_size=batch_size, return_timestamps=return_timestamps
)
return json.dumps(prediction)
@workflow
def torch_wf(
checkpoint: str = "openai/whisper-large-v2",
audio: FlyteFile = "https://huggingface.co/datasets/Samhita/whisper-jax-examples/resolve/main/khloe_kardashian_podcast.mp3",
chunk_length: float = 30.0,
batch_size: int = 8,
return_timestamps: bool = False,
) -> str:
return torch_transcribe(
checkpoint=checkpoint,
audio=audio,
chunk_length=chunk_length,
batch_size=batch_size,
return_timestamps=return_timestamps,
)
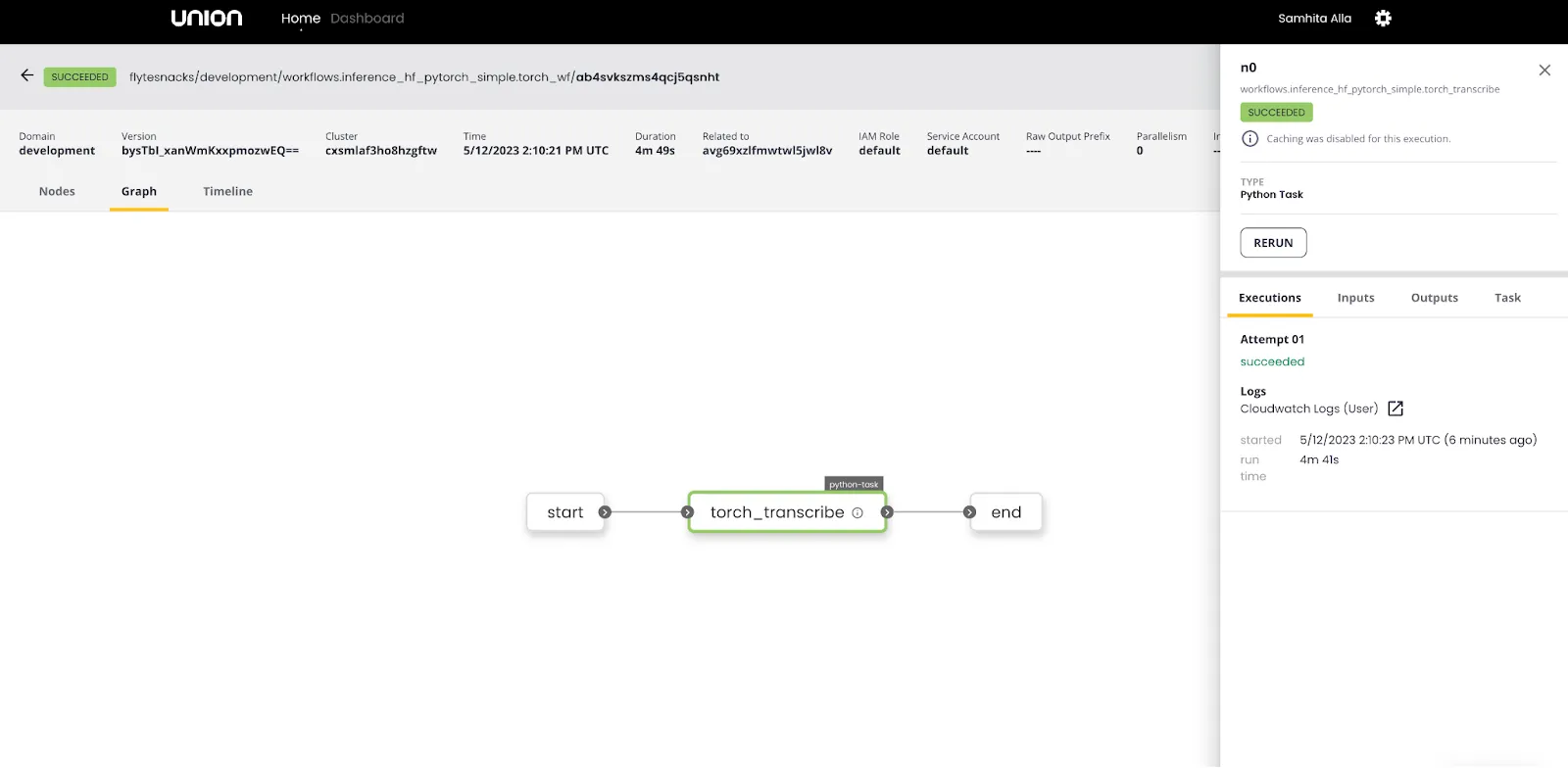
The pipeline in this example implements a chunking algorithm that allows for transcription of audio samples with arbitrary lengths. When triggered on the Flyte backend, the workflow is allocated 1 GPU, 2 CPUs, and 15 GB of memory for the transcription task. A batch size of 16 resulted in a CUDA out-of-memory error, but reducing the batch size to 8 allowed the workflow to complete successfully. The inference time for a 59-minute audio was approximately 5 minutes with a batch size of 8. It's worth noting that this pipeline runs entirely within a single container.
Whisper JAX in a single container
Now, let's proceed to running Whisper JAX on Flyte, in a single container.
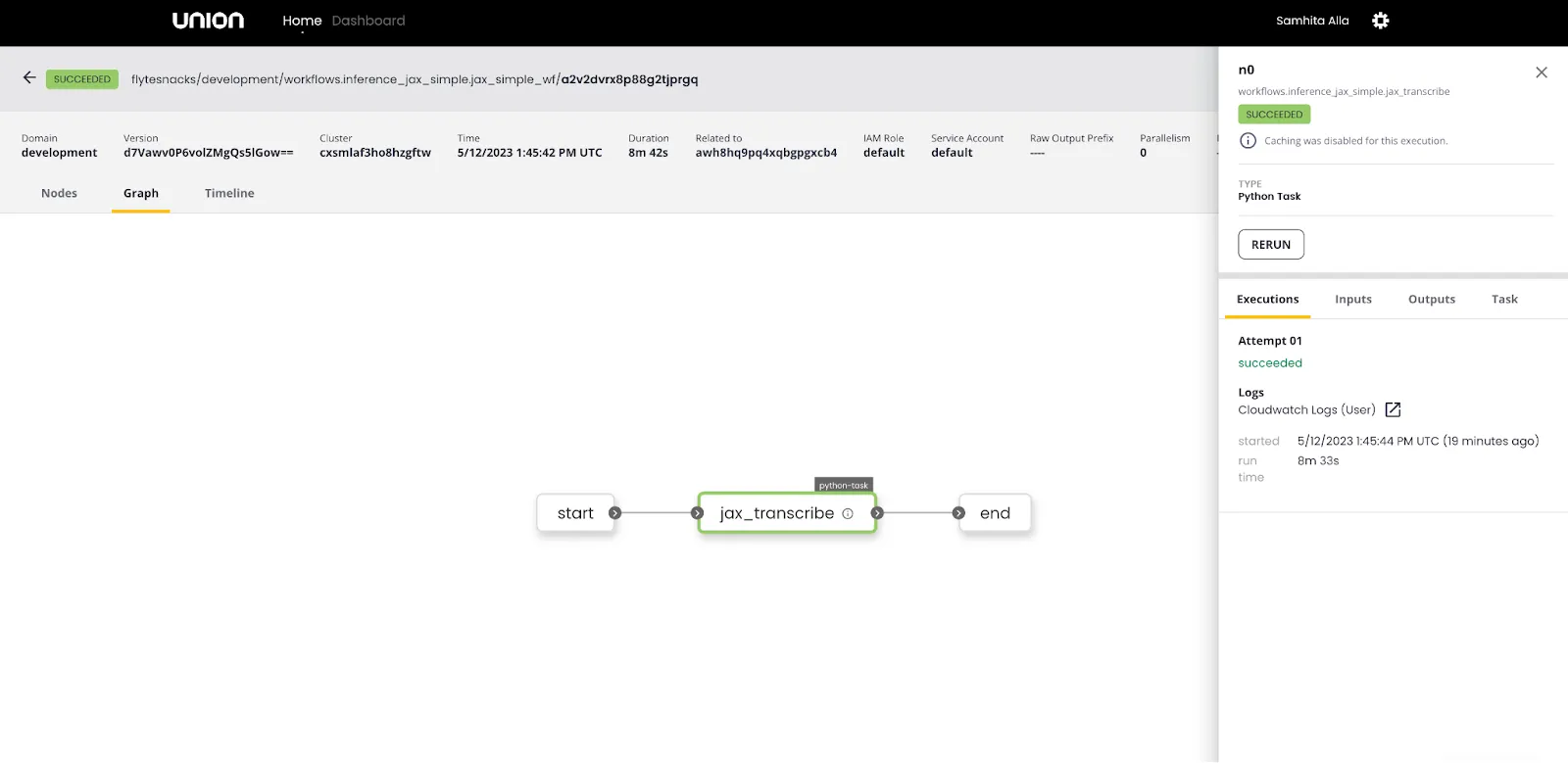
The Whisper JAX pipeline also utilizes a chunking algorithm and leverages JAX's `pmap` function for data parallelism across GPU/TPU devices. The JAX transcription task is assigned 1 GPU, 2 CPUs, and 15 GB of memory. With a batch size of 8, the pipeline was able to transcribe the same 59-minute audio file in about 9 minutes on a V100 GPU.
When using a batch size of 16, the inference time averaged approximately 8 minutes.
Whoa, turns out JAX is slower than PyTorch because we can't tap into those compilation cache speed boosts. Understanding the factors that trigger JAX cache hits and misses is currently challenging. However, if the caching process becomes more configurable, we could potentially leverage it to achieve even better performance.
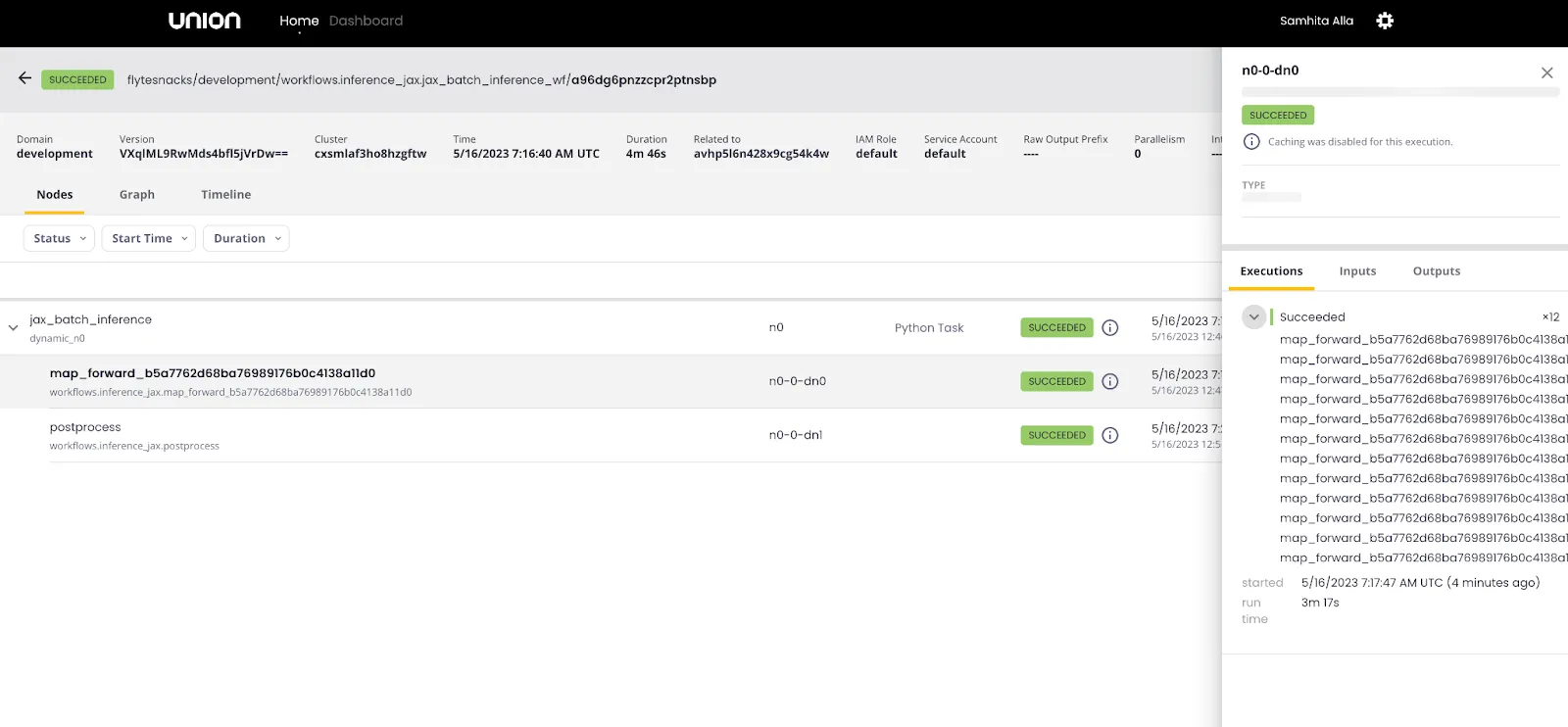
Parallel task fusion with map tasks
In production scenarios, it is common to generate transcriptions for a batch of audio inputs. To accomplish this efficiently, you can leverage map tasks. Flyte's map tasks allow for parallel transcription, leading to significantly faster processing times compared to running transcriptions sequentially. We've taken the code and made minor adaptations from the original Whisper JAX code.
`forward` task
For the most part, the `forward` task remains true to the original code. To achieve parallel execution, we'll employ a map task that ensures the necessary resources are allocated when the task is invoked.
Copied to clipboard!
@task
def forward(
model_inputs: List[np.ndarray],
batch_size: Optional[int],
language: Optional[str],
task: Optional[str],
return_timestamps: Optional[bool],
max_length: Optional[int],
checkpoint: str,
) -> List[np.ndarray]:
model, params = FlaxWhisperForConditionalGeneration.from_pretrained(
checkpoint, _do_init=False, dtype=jnp.float16, cache_dir="whisper-models"
)
max_length = model.generation_config.max_length if max_length == 0 else max_length
params = jax_utils.replicate(params)
model_inputs = {
"input_features": model_inputs[0],
"stride": model_inputs[1].tolist(),
}
# We need to keep track of some additional input arguments for post-processing so need to forward these on after running generation
input_features = model_inputs.pop("input_features")
input_batch_size = input_features.shape[0]
if input_batch_size != batch_size:
padding = np.zeros(
[batch_size - input_batch_size, *input_features.shape[1:]],
input_features.dtype,
)
input_features = np.concatenate([input_features, padding])
pred_ids = forward_generate(
input_features=input_features,
model=model,
max_length=max_length,
params=params,
language=language,
task=task,
return_timestamps=return_timestamps,
)[:input_batch_size]
# tokenizer's decode method expects an extra dim - we insert it here for convenience
out = {"tokens": pred_ids[:, None, :]}
stride = model_inputs.pop("stride", None)
if stride is not None:
out["stride"] = stride
return [out["tokens"], np.array(out["stride"])]
`postprocess` task
Post-processing involves consolidating the transcriptions of audio chunks, which remain mostly unchanged from the original code, except for the task decorator and resource allocation.
Copied to clipboard!
@task(requests=Resources(mem="5Gi", cpu="2", gpu="1"))
def postprocess(
model_outputs: List[List[np.ndarray]],
chunk_length: int,
sampling_rate: int,
max_source_positions: int,
tokenizer: WhisperTokenizer,
return_timestamps: bool,
) -> str:
unpacked_model_outputs = []
for output in model_outputs:
model_output = {"tokens": output[0], "stride": output[1].tolist()}
for t in zip(*model_output.values()):
unpacked_model_outputs.append(dict(zip(model_output, t)))
time_precision = chunk_length / max_source_positions
# Send the chunking back to seconds, it's easier to handle in whisper
for output in unpacked_model_outputs:
if "stride" in output:
chunk_len, stride_left, stride_right = output["stride"]
# Go back in seconds
chunk_len /= sampling_rate
stride_left /= sampling_rate
stride_right /= sampling_rate
output["stride"] = chunk_len, stride_left, stride_right
text, optional = tokenizer._decode_asr(
unpacked_model_outputs,
return_timestamps=return_timestamps,
return_language=None,
time_precision=time_precision,
)
return json.dumps({"text": text, **optional})
Bringing it all together
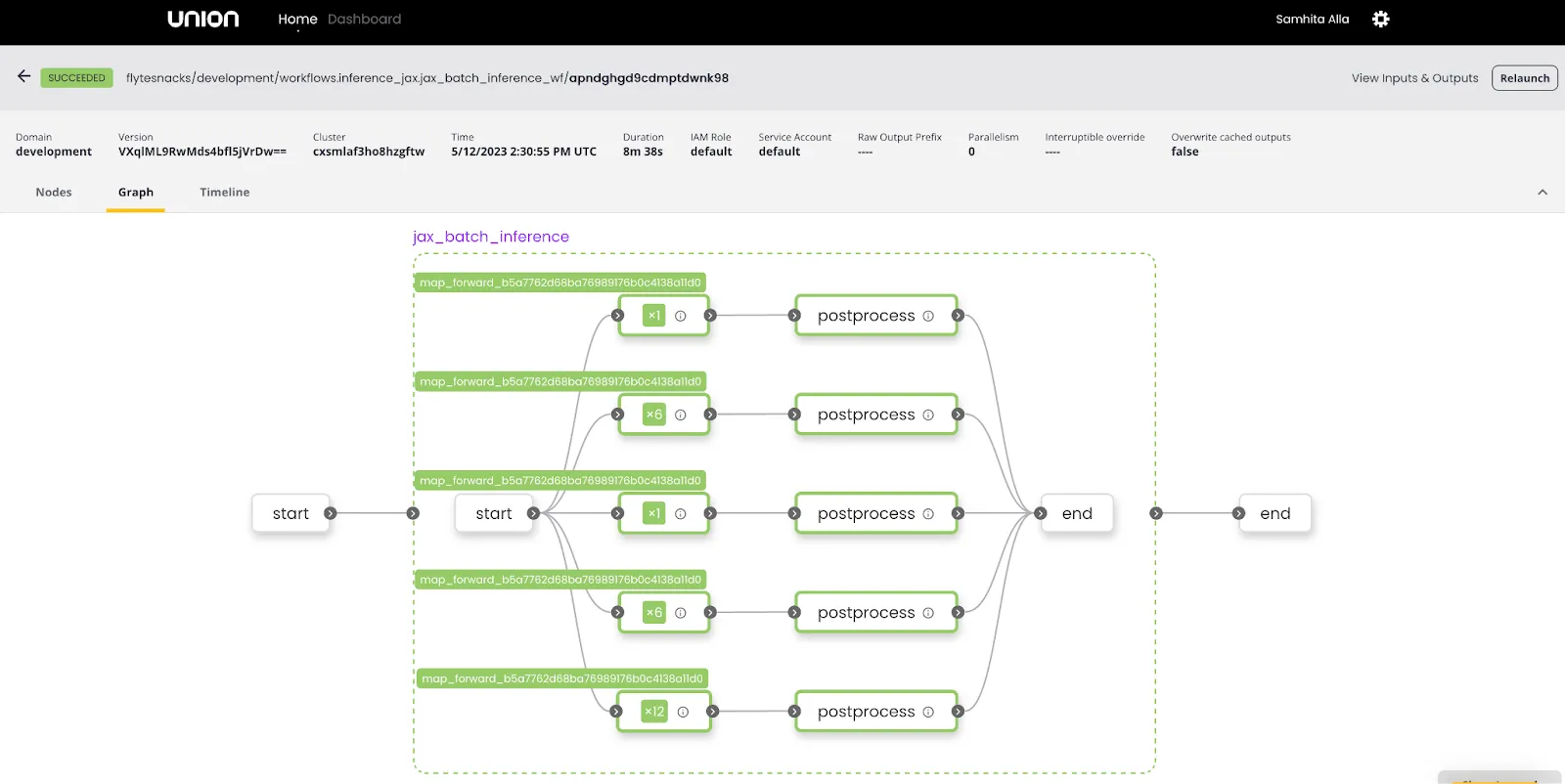
The last step entails invoking the `forward` and `postprocess` tasks on the audio chunks to run the transcription.
In addition to parallelizing the audio transcriptions, we're also running the audio chunks concurrently. This boosts speed, and it’s ideal for handling large-scale batch inference in a production environment.
The exact total runtime of the end-to-end workflow is hard to determine since map tasks run in parallel. However, it took the previous 59-minute audio 6 to 7 minutes to complete (keeping concurrency in mind). Just for comparison, when transcribing the same audio individually, it took about 5 minutes.
Support for multiple GPUs works seamlessly out of the box. You can specify the desired number of GPUs in the task decorator, such as `gpu=2`, and Flyte and JAX will handle the rest.
Thanks to the magic of map tasks, we unleashed the power of parallel processing. Batch inference is a whole different ball game compared to single model prediction, particularly concerning latency and efficient resource utilization. Union cloud lets you process large amounts of data, run batch inference and train complex models, including large language models seamlessly, all while enabling load balancing, resource allocation, scalability and optimal performance.
It's time to rev up those GPUs and make them go brrrr!