I first learned about DataFrames very early in my data-science journey, learning Python and R in tandem. At the time, I was in graduate school doing a Master’s degree in Public Health, but as a code-curious student in the social and behavioral sciences, I cross-registered for classes in the CS and stats department.
A long-time spreadsheet user, I learned how to load tables into memory as DataFrames and manipulate them programmatically using Python’s pandas or R tidyverse libraries. Being able to capture all of the data transformations in code seemed like a superpower, and my mind was blown by how flexible and powerful these tools were for reproducible data manipulation and analysis.
Does it quack like a DataFrame?
After starting my first industry gig as a data scientist, I quickly came to realize that dynamically typed languages have certain “gotchas.” Date-time columns would often be implicitly represented as strings, or my floating-point columns would have null values where I didn’t expect them.
This is because, for programming languages like R and Python, types are dynamic. Famously, Python adopts the duck-typing philosophy, where values are of a particular type if it supports a certain set of operations, e.g., “Numerical types should support addition by implementing the <span class="code-inline">__add__</span> special method.” In practice this means that, at runtime, a variable containing some value may or may not be the type you expect: You have to “coerce” variables with explicit calls to <span class="code-inline">float(value)</span>, and you have to rely on runtime errors to let you know when invalid operations occur between, say, a string and a floating-point number.
This problem only compounds with more complex data containers like DataFrames, n-dimensional arrays, and other data structures that we use as data science and machine learning practitioners.
Types for statistical data testing
Data testing helps catch many of these silent errors. It’s the practice of validating not only real data, but also the functions that produce them — and this is where Pandera enters the picture.
Pandera is a statistical data testing toolkit that enables you essentially to write schemas for your DataFrame-like objects in a concise yet flexible way. Suppose you have a dataset containing measurements of penguins that contains four columns: species, weight and beak length. You can express the type of your dataframe like so:
As you can see from the schema definition above, we’re explicitly stating the data types and properties of the fields in the dataset, including domain-specific knowledge about the species of penguins contained in the dataset and some basic value checks to make sure weight and beak length are positive numbers.
You can think of a Pandera schema as a fancy assertion statement that you can integrate into your existing code:
The <span class="code-inline">@pa.check_types</span> decorator allows you to check the properties of the inputs and outputs of your functions as data passes through them.
Pandera effectively gives you the ability to specify types for pandas dataframes, but it also supports geopandas, modin, dask and pyspark.pandas. We’re working on supporting many other dataframe-like objects.
Data testing is an iterative process
In practice, data testing is time-consuming because creating checkpoints that verify properties of this data involves exploratory data analysis (EDA): you iteratively build domain knowledge about your data, encoding that knowledge into explicit assumptions that are validated at some point during your analysis pipeline.

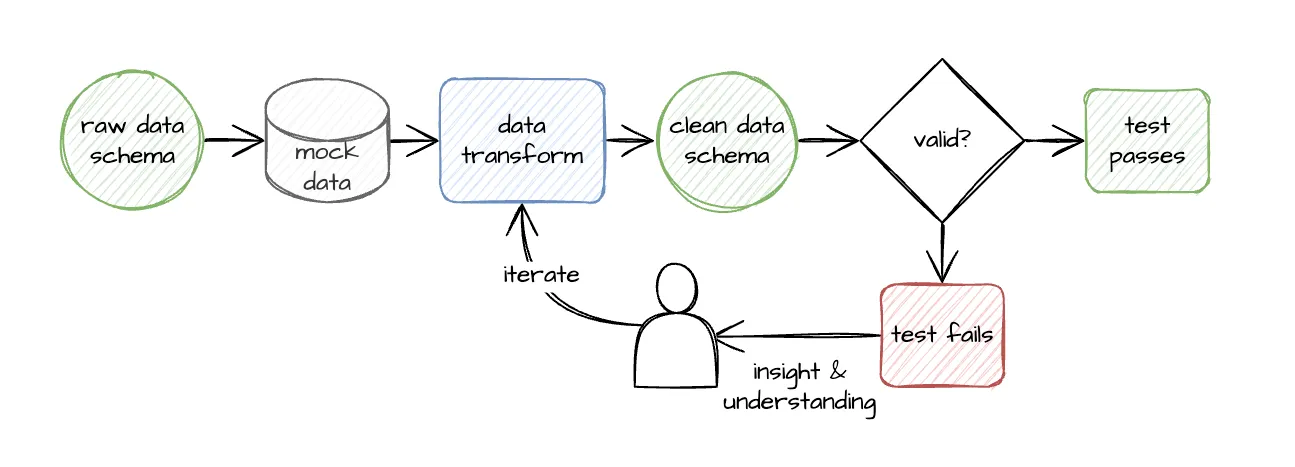
However, making the investment to specify types for your datasets not only renders your analysis and modeling pipelines more robust against data corruption and silent errors, it helps you and your team gather around a source of truth about what the data ought to look like. This facilitates an ongoing process of data quality refinement — one I think is sorely missing based on my experiences working in data science and machine learning organizations.
What next?
In summary, this introductory blog showed you the basics of data testing and how you can use Pandera to make your data pipelines more reliable and robust. You only learned about a few of the things you can do with Pandera, but there are a lot more abilities it can provide, like schema inference, lazy validation, and integrations with frameworks like FastAPI and Pydantic.
<a href="https://pandera.readthedocs.io/en/stable/try_pandera.html" class="button w-button" target="_blank">Try Pandera</a>
👆 Click on the button above to try out pandera in your browser, or <span class="code-inline">pip install pandera</span> on your machine today! You can also find resources to learn more about it here:
- Try pandera: pandera.readthedocs.io/en/stable/try_pandera.html
- Github repo: github.com/unionai-oss/pandera
- Documentation: pandera.readthedocs.io
Join the Discord community if you have any questions! See you there! 👋