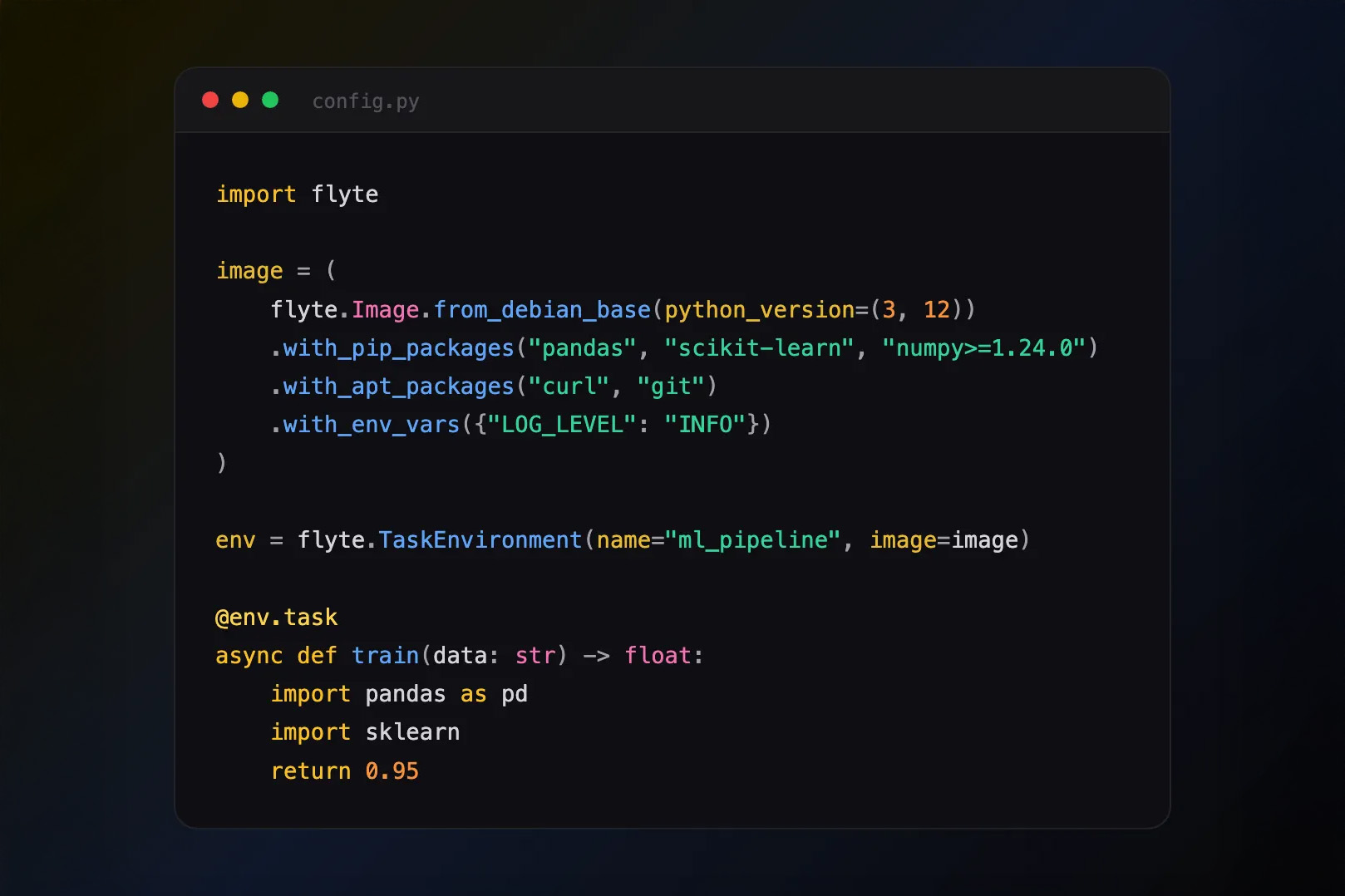
Pandera 0.18 introduces two new configuration settings that control how validation happens: a global validation on/off switch that you can set through the `PANDERA_VALIDATION_ENABLED` environment variable, and granular control of schema and data validation that you can set through the `PANDERA_VALIDATION_DEPTH` environment variable. These settings were first introduced in version 0.16.0 but were only available in the pyspark validation engine. Release 0.18 ports these settings to the pandas validation engine.
Before now, a call to `schema.validate(dataframe)` would perform run-time validation on the `dataframe` based on the schema specification:
This runtime validation also applies to functions that are called with the `pandera.check_types` decorator:
Global validation on/off switch
With export `PANDERA_VALIDATION_ENABLED=False`, you can turn off validation altogether with a simple switch, no code changes necessary! You might want to do this in production contexts where you don’t want to incur the additional runtime cost of validating data, which can be substantial with very large datasets. In these cases, you may have development and/or staging pipelines where you set `PANDERA_VALIDATION_ENABLED=True` to perform Pandera validation on realistic-looking data or samples of your real data, while you set `PANDERA_VALIDATION_ENABLED=False` in your production environment to shut off validation there.

While this does somewhat defeat the point of making sure your actual data is valid, one pattern that may make sense for you would be to perform validation on your production data at rest. In other words, run your data ingestion pipeline, which may produce a dataset that you persist in some blob store, and then have a separate workload that runs the validation procedure (perhaps as a scheduled job). This way, you don’t have to hold up the production pipelines, especially when you do find data errors.
Granular control of schema and data validation
An orthogonal approach to streamlined data validation is to only perform checks that can be done on the dataframe’s metadata and skip the checks that have to inspect the actual data values.
Pandera provides a way for you to do this through the `PANDERA_VALIDATION_DEPTH` configuration setting, which differentiates between schema-level validations and data-level validations.
Schema-level validations are checks on metadata:
- Checking for column presence
- Verifying column data types
- Ensuring column ordering
Data-level validations, as the name suggests, are checks that inspect actual data values, for example:
- Checking that integer values of a column are positive numbers
- Making sure that string values are drawn from a set, e.g. `{“Apple”, “Orange”, “Banana”}`
- Checking that float point values are probabilities between 0.0 and 1.0
If we look at the schema below, we can see that it’s specified to perform all of the validations above:
With the `PANDERA_VALIDATION_DEPTH` environment variable, you can determine what kinds of validations to perform:

Wrapping up
The 0.18.* releases also deliver bug fixes, improved docs, and housekeeping changes; see the full changelogs here and here.
What’s next for Pandera? I’m happy to announce that the pandera-polars integration beta release 0.19.0b0 is now available for early testing! Just `pip install pandera[polars]==0.19.0b` and check out the preview docs here. If you have any feedback, please feel free to join the #pandera-polars channel on our discord.
Thanks for reading, and if you’re new to Pandera, you can try it out quickly ▶️ here.