Walk through a complete, production-grade pipeline for satellite image classification. We use EfficientNet-B0 and a two-phase fine-tuning strategy to achieve >95% accuracy on EuroSAT, all orchestrated by Flyte for cost-efficiency, reproducibility, and integrated experiment tracking with Weights & Biases.
Background
Remote sensing has transformed how we monitor our planet. From tracking deforestation to detecting urban sprawl, satellite imagery provides a bird's-eye view of land use change at global scale. But training a model that can reliably classify that imagery - across 10 distinct land-use categories, at production quality - requires more than just a good model. It requires a pipeline that handles data, compute, caching, experiment tracking, and reporting as first-class concerns.
In this post, we walk through a complete satellite image classification pipeline built on Flyte, using EfficientNet-B0, a two-phase training strategy, and Weights & Biases for experiment tracking.
Dataset
EuroSAT is a benchmark dataset of 27,000 labeled satellite images drawn from the Sentinel-2 satellite. Each image is 64×64 pixels across 10 land-use classes: Annual Crop, Forest, Herbaceous Vegetation, Highway, Industrial, Pasture, Permanent Crop, Residential, River, and Sea/Lake.
It's a well-structured dataset - balanced, clearly labeled - which makes it ideal for demonstrating a production-grade training pipeline without the overhead of massive data infrastructure.
Model
We use EfficientNet-B0 from timm, pretrained on ImageNet. EfficientNet was designed to scale depth, width, and resolution jointly using a compound coefficient, giving strong accuracy with a relatively small parameter count (~5.3M). The ImageNet pretraining means the backbone already understands edges, textures, and shapes - features that transfer well to satellite imagery.
Two-Phase Training
Fine-tuning a pretrained model naively by using all weights immediately often leads to catastrophic forgetting: the model destroys its learned representations before the new task-specific head has had a chance to stabilize.
Instead, we use a two-phase approach:
- Phase 1: Feature Extraction (frozen backbone). The EfficientNet backbone is frozen. Only the classification head is trained, at a relatively high learning rate (2e-3). This gives the head 7 epochs to learn to map ImageNet features to EuroSAT categories, without disturbing the pretrained weights.
- Phase 2: Fine-tuning (unfrozen backbone). The backbone is unfrozen and added to the optimizer with a 10× lower learning rate than the head (phase2_lr × 0.1). A fresh cosine annealing schedule is initialized over the remaining steps, so the learning rate doesn't arrive near-zero from Phase 1's schedule before Phase 2 even begins. This lets the backbone adapt to satellite-specific features while preserving the general representations it learned on ImageNet.
The transition happens automatically inside a PhaseChangeCallback:
This two-phase strategy consistently reaches >95% validation accuracy on EuroSAT within 17 total epochs.
Pipeline
Training a model is only part of the story. The real challenge is building a system that is reproducible, cost-efficient, and easy to iterate on. That's where Flyte’s `TaskEnvironment` model shines: each stage of the pipeline runs in the right compute environment, and results are cached so you never pay for work you've already done.
The pipeline has four components, each with its own environment defined in config.py.
Data Download
This task downloads the raw EuroSAT JPEG files via torchvision and packages them as a flyte.io.Dir. It runs on a lightweight CPU container (2 cores, 2 GB RAM) - no GPU needed. With `cache="auto"`, the result is stored and reused on every subsequent run. You pay for the download exactly once.
No preprocessing happens here. Raw images are passed directly to training so that all transforms - resize, normalize, augment. This happens per-batch with the full training context, giving the model properly prepared 224×224 input from the original pixels.
GPU Training
This task runs on a T4 GPU with 32 GB RAM. It receives the dataset Dir from Task 1, downloads it locally, then runs the two-phase training loop using PyTorch Lightning.
Two things worth noting:
- With `cache="auto"` training results are cached based on the input data and config. If you rerun the pipeline with the same dataset and hyperparameters, Flyte skips training entirely and returns the cached metrics. This makes hyperparameter search much cheaper: only configurations you haven't tried before actually execute.
- `@wandb_init` — the flyteplugins-wandb integration initializes a W&B run automatically and makes it available via get_wandb_run(). This means every training run automatically logs metrics, learning rate curves, and t-SNE visualizations of the learned feature space to your W&B project.
The W&B integration will link runs from the Flyte cluster so that you can persist and view training metrics in your W&B account:
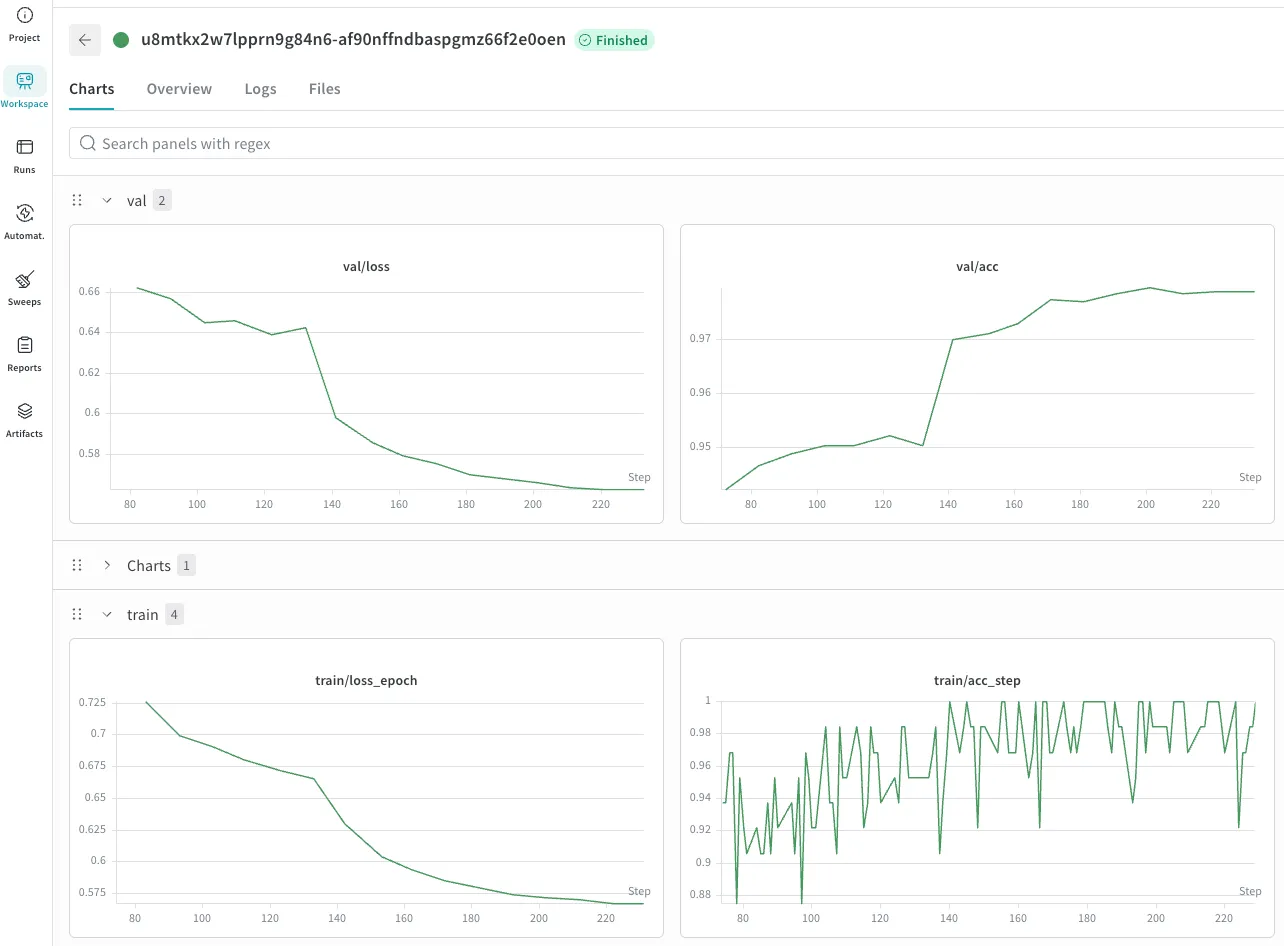
Embedding evolution over time
Using t-SNE to reduce the dimensionality of the image embeddings over time, we can also visualize how the embedding representation for the different labels in the dataset form more distinct clusters as training progresses. Intuitively, this corresponds to how well the model can accurately predict the land use label given an image:

Report Generation
This task reads the `metrics.json` produced by training and renders interactive Plotly charts — validation accuracy and train/val loss curves - directly in the UI. The report=True flag tells Flyte to render the task output as a rich report panel. A dashed vertical line marks the Phase 1 → Phase 2 transition, making it easy to see how much the backbone fine-tuning contributes.
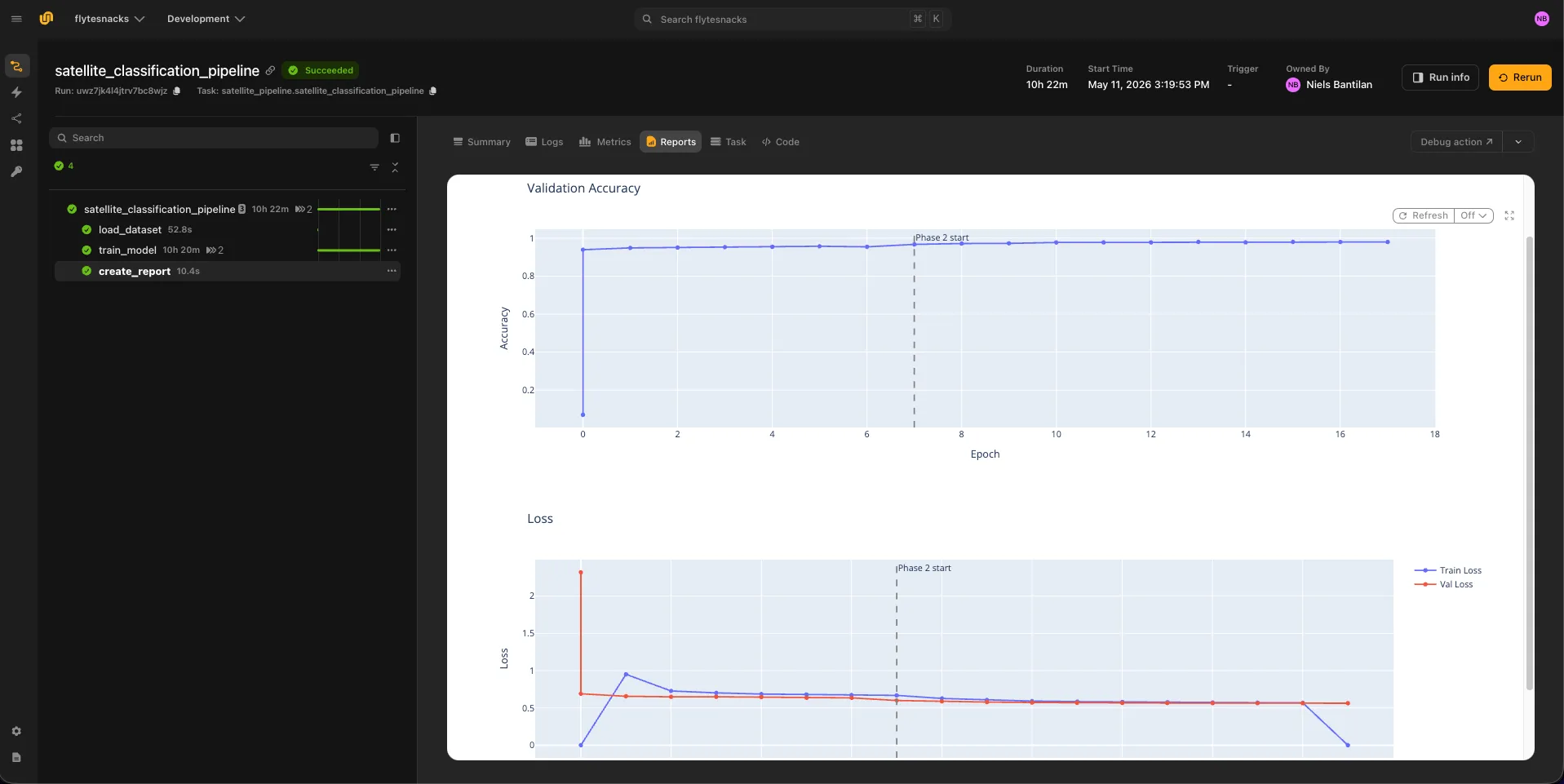
With flyte reports, you can track metrics like validation accuracy as training progresses
Workflow Orchestration
The pipeline task is a lightweight orchestrator. It has no heavy dependencies of its own, just enough to call the three tasks above in sequence. depends_on ensures the container image is built after all its dependencies are resolved. The async/await pattern means each task handoff is non-blocking: Flyte manages scheduling, retries, and data movement between tasks transparently.
Running the Pipeline
Submit the pipeline with a single command from the project directory:
The W&B project and entity are wired in at submission time. Flyte handles spinning up the right containers, routing data between tasks, and surfacing results in the UI.
Conclusion
Building a high-accuracy classification model is only half the battle; the real challenge lies in making the process reproducible, cost-efficient, and easy to analyze. Orchestrating this pipeline with Flyte and Weights & Biases (W&B) provides a system that addresses these production challenges directly:
- Cost-Efficiency and Reproducibility with Flyte: Flyte's TaskEnvironment model ensures that compute is optimized for the task, using lightweight CPU containers for tasks like data download and powerful T4 GPUs only for training. Crucially, its automatic `caching (cache="auto")` means that if you rerun the pipeline with the same inputs, tasks like data download and training are skipped, preventing you from paying for work you've already completed.
- Integrated Experiment Tracking with W&B: The tight integration with W&B automatically logs every training run, providing a complete record of per-step metrics and the learning rate schedule.
- Visualization and Analysis: W&B allows for deep analysis, including t-SNE visualizations of the model's learned embeddings that show how feature representations evolve and classes pull apart into well-separated clusters during training.
- Unified Reporting: Flyte enhances visibility by using the report=True flag to render interactive Plotly reports—complete with accuracy and loss curves—directly in the UI alongside the full task logs.
By combining a robust training strategy (two-phase fine-tuning) with a powerful MLOps platform, this pipeline transforms a machine learning experiment into a production-ready, repeatable, and transparent system.
Find the full code for this tutorial here.
.webp)
