
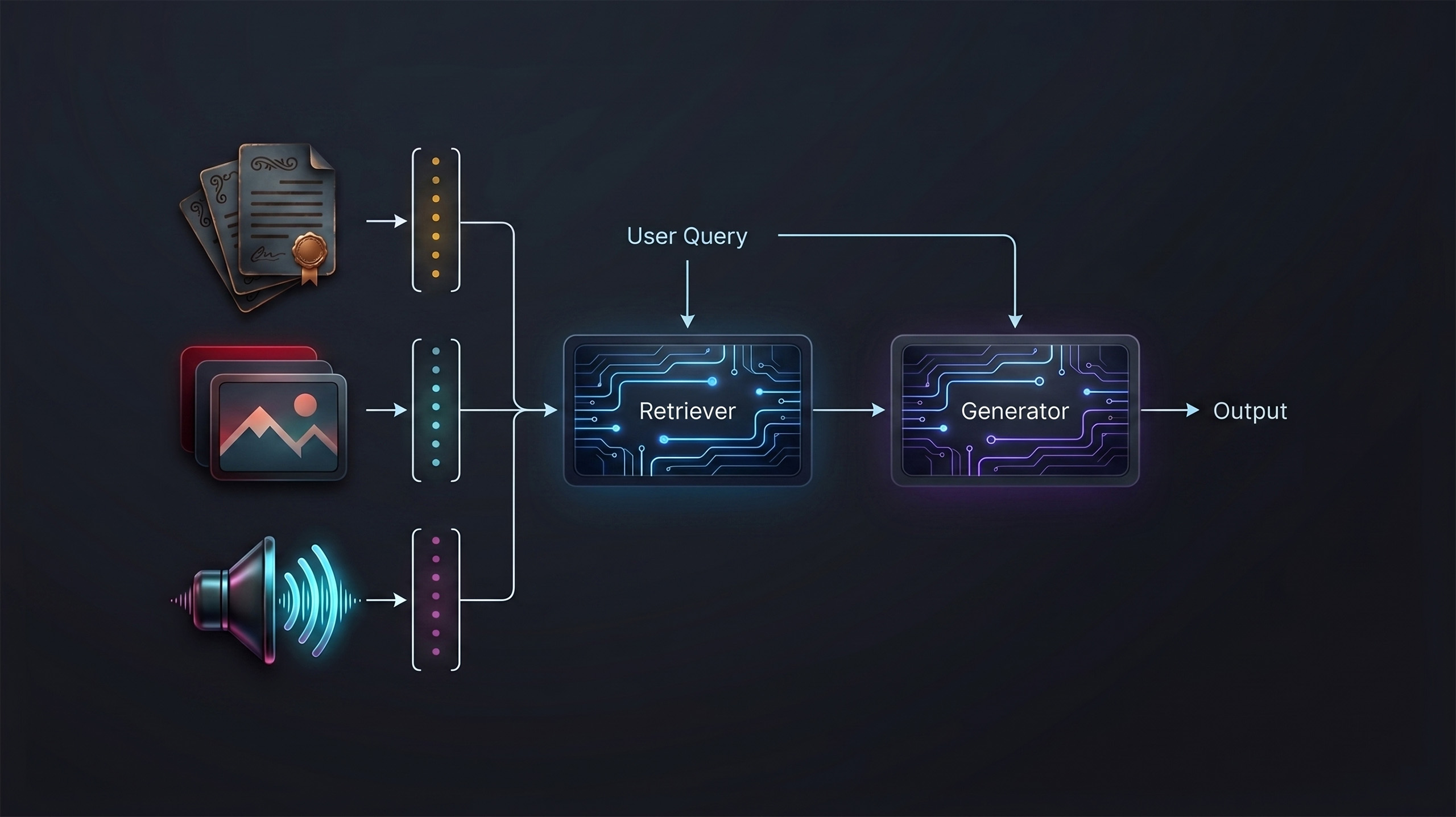
Most retrieval benchmarks are designed as fixed reference points. While models and datasets continue to grow, evaluation is often repeated against the same static setup.
We wanted something slightly different: a benchmark that functions not just as a reference, but a pipeline that can be used as a reusable system with a new model or dataset in minutes, without recomputing work that has already been done.
In this blog, we discuss how we built that framework and what we observed when running it across three fundamentally different retrieval approaches on the ViDoRe benchmark.
Problem
Visual document retrieval is the task of finding a page in a document corpus given a text query without OCR preprocessing, and operating directly over raw page images. Although it resembles a retrieval problem, it is fundamentally a representation problem: how should a page image and a text query be encoded so that the relevant page ranks highest?
We evaluated three approaches, each grounded in different design philosophies.
ColPali-v1.2 feeds the page image into PaliGemma, a vision-language model, and produces roughly 1024 embedding vectors per page (one per image patch). At query time, each token is matched to its most relevant patch via a MaxSim operation. This later interaction scoring allows the model to localize fine-grained regions of a page rather than compressing everything into a single representation.
SigLIP SO400M takes the opposite approach: one global embedding per page, one for the query, scored with cosine similarity. The architecture is simple and computationally efficient, and on many tasks competitive with patch-level models. The tradeoff here is that a single vector cannot localize specific pages. If we search for a particular segment in a page the dense global embeddings may dilute the signal.
OCR + BM25 removes natural representations entirely. Pages are processed with doctr (a GPU-accelerated OCR engine), extracted text is indexed and queries are scored with BM25. This remains as a strong baseline for text-dense documents, while being entirely insensitive to visual structure.
The Pipeline
The framework runs on Flyte, a workflow orchestration system for data and ML pipelines. This matters less for the orchestration itself and more for two specific properties: deterministic task-level caching and the ability to keep GPU containers warm between invocations. Both turn out to be load bearing for the design.
The framework consists of five stages:
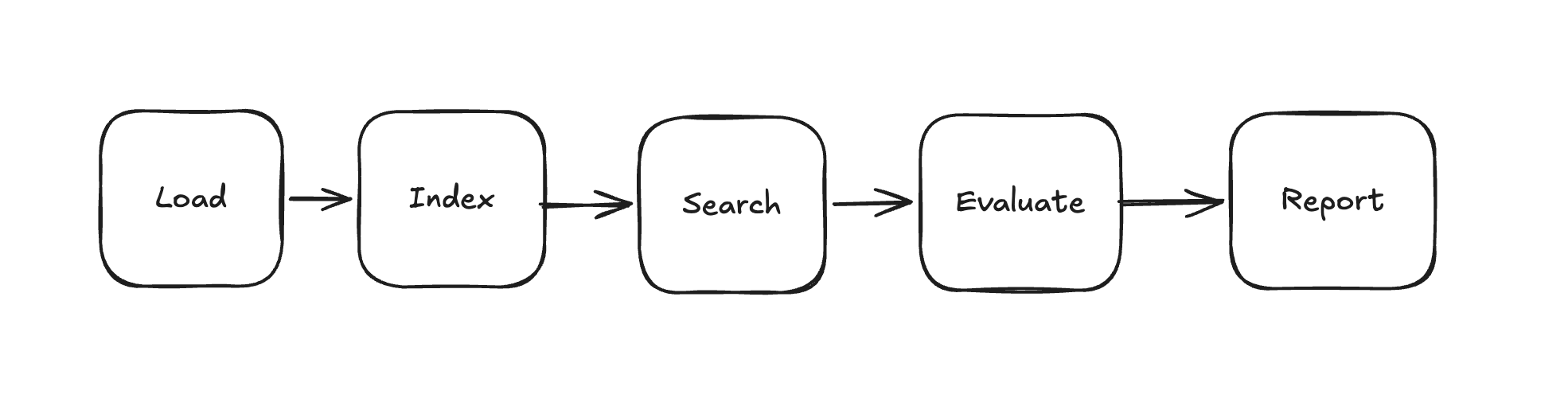
Each stage caches its output against its inputs. If the pipeline is rerun with a different top_k value, the indexing stage is skipped entirely. GPU time is only spent on genuinely new computations.
On the ViDoRe v3 finance subset (~2900 pages), ColPali indexing requires substantial GPU time. When configuring hyperparameters or comparing additional models, re-encoding the full corpus would take a massive amount of time. The pipeline avoids that cost by design cache=”auto”.
Similarly, the same principle applies to data loading. Page images are uploaded to blob storage and referenced by ID. Subsequent re-runs reuse the metadata rather than transferring raw files again.
To extend the framework to a new model, only two components must be implemented:
- An encoder that maps page images to embeddings.
- A scorer that evaluates query embeddings against the indexed corpus.
The surrounding infrastructure including caching, sharding, evaluation, reporting remains unchanged.
Effective GPU Utilization
If we attempt to run multiple experiments concurrently, ineffective GPU utilization often becomes a problem. Suppose you have 8 concurrent search calls and each trigger a GPU forward pass, the GPU does not see 8x the work, it sees 8 small, poorly utilized batches in rapid succession.
The root cause is a lack of coordination across task invocations. Without aggregation, concurrent calls result in fragmented workloads.
The solution is a DynamicBatcher – a process-level singleton that aggregates queries from concurrent callers into a shared queue. Batches are assembled according to a cost budget and timeout, then dispatched as a single GPU workload.
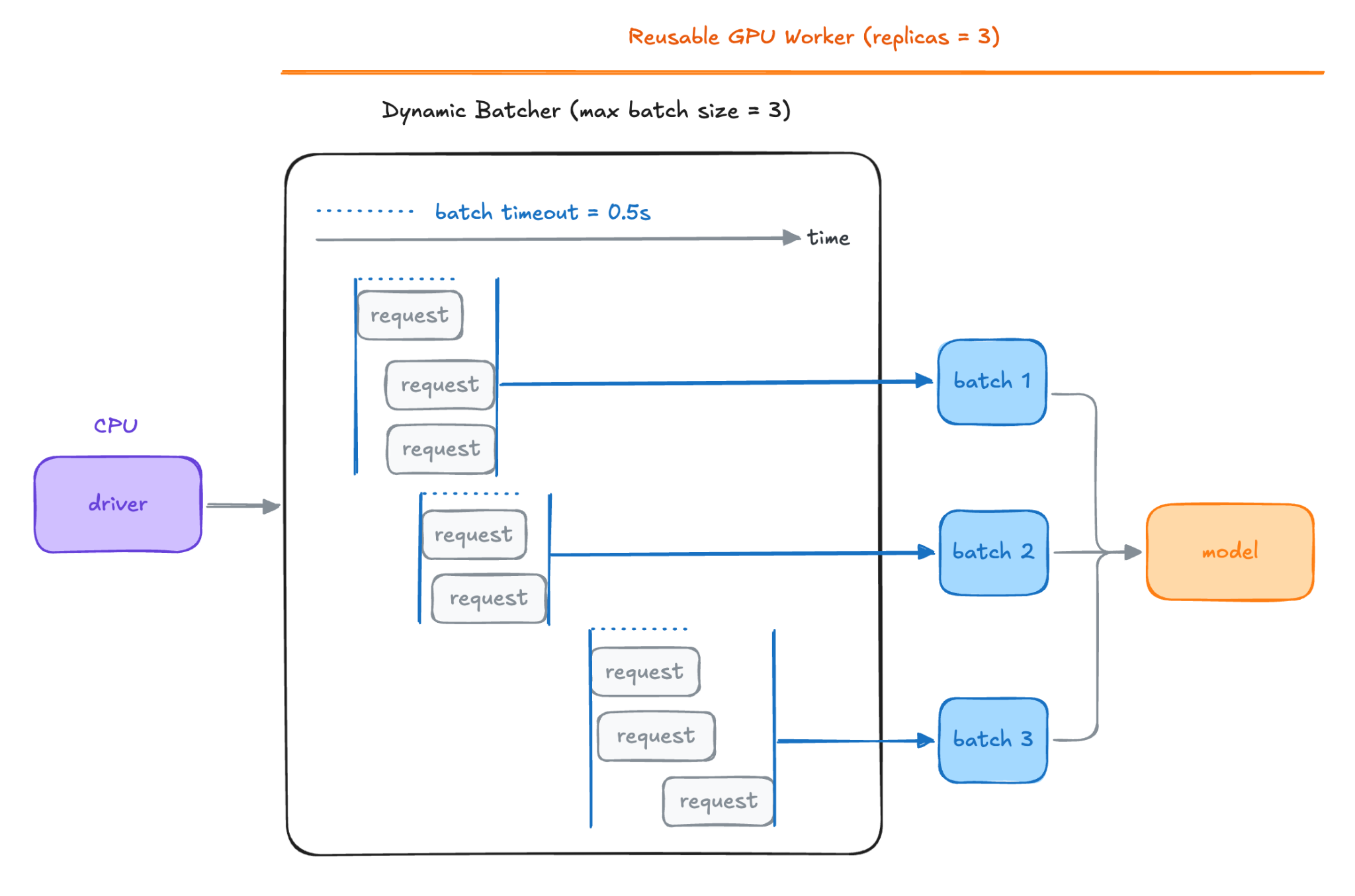
The pattern is enabled by Flyte’s ReusePolicy, which keeps a single GPU container alive between task dispatches rather than cold starting a fresh container per invocation. Without it, each `search_colpali` call would land in a new process with a new batcher and there would be nothing to aggregate across. The singleton only works because the container is shared.
Each `search_colpali` invocation `calls _get_colpali_search_batcher` gets the same batcher, and submits its queries. The GPU receives curated batches designed for high-utilization.
A subtle implementation detail is that the GPU forward pass must execute in a thread pool `(asyncio.to_thread)` rather than directly in the event loop. Running it inline would block the event loop during the forward pass thereby preventing the batcher from aggregating additional queries. By offloading GPU work to a separate thread, the aggregation loop remains responsive.
While one batch is executing on the GPU, the next is already being assembled.
GPU Behavior Across Models
The three experiments produce meaningfully different GPU utilization profiles, reflecting their architectural differences as much as their accuracy differences.
ColPali-v1.2
OCR + BM25
SigLIP SO400M
Indexing
During indexing, there is only one caller, so batching across concurrent invocations is unnecessary. Instead, parallelism occurs between image download and GPU execution.
The implementation uses explicit prefetching. Before the GPU processes batch N, images for batch N+1 are downloaded in a thread pool. When the forward pass completes, the next batch’s inputs are ready.
The result is a steady pipeline: the GPU does not wait on I/O, and I/O does not wait on the GPU.
Results
We evaluated the pipeline on the ViDoRe v3 finance subset with 2,000 corpus pages and 1854 queries.
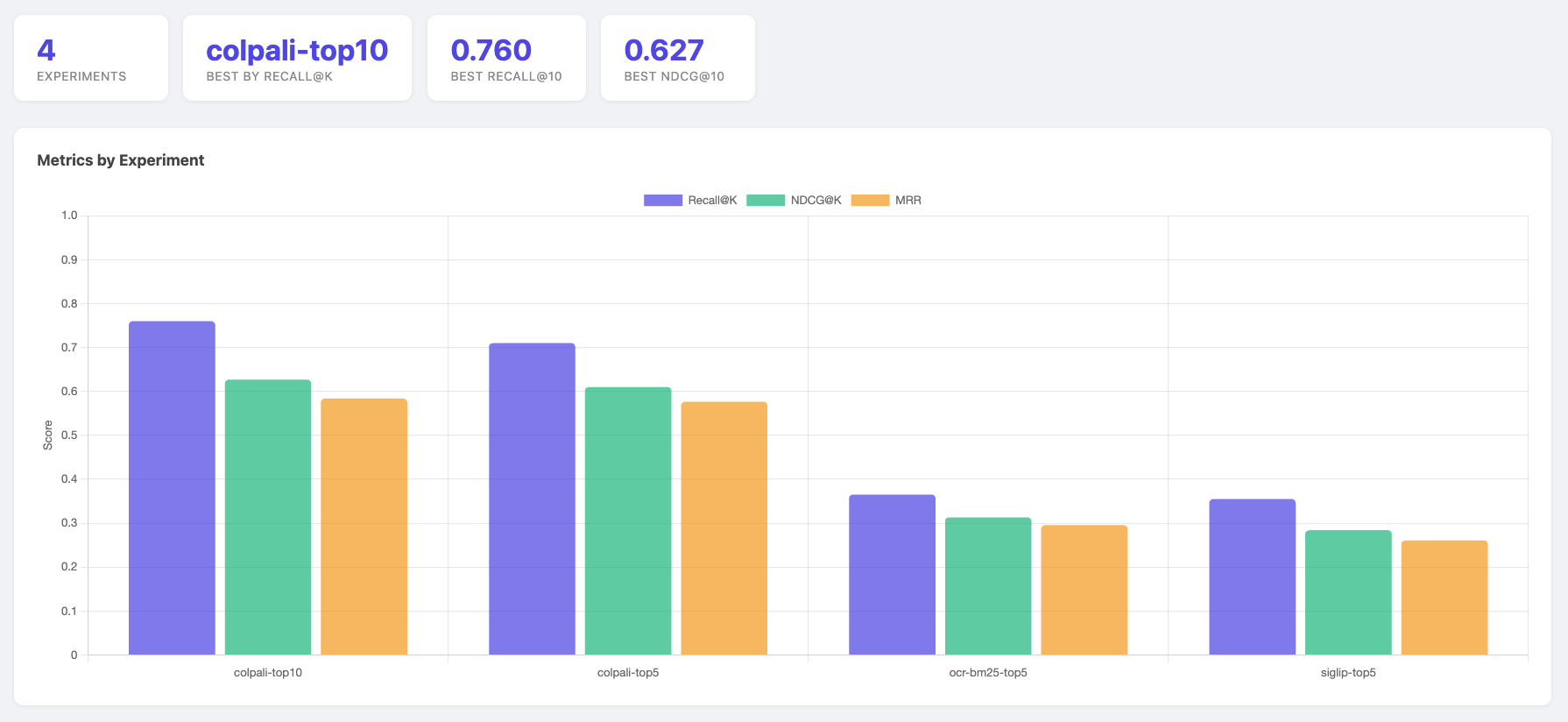
Colapali achieved the strongest results, which is consistent with the structure of financial documents. Patch-level representations can localize tables, figures, and dense numerical regions that global embeddings may smooth over.
The BM25 baseline is also informative. Despite having no neural components, it significantly outperformed SigLIP on Recall@5. Finance documents are text-dense and keyword overlap remains a strong signal in such settings. SigLIP’s global embedding struggled to compete without fine-tuning.
One takeaway is not that global embeddings are ineffective, but that the document heavy retrieval tasks may reward localized or token-aware representations.
Takeaways
It’s noteworthy to point out that SigLIP, a neural model trained on hundreds of millions of image-text pairs, producing richer representations than any keyword index, scored a Recall@5 of 0.022, worse than BM25 by a factor of six. On financial documents, keyword overlap is a stronger signal than global semantic similarity. The architecture that wins on a natural image retrieval can fail badly in a document heavy domain without fine-tuning.
That kind of finding is easy to miss when benchmarking is expensive. If running one model costs significant GPU time and manual setup, you run fewer experiments and rely more on intuition about which approach would work. The point of a reusable pipeline is that it lowers the cost of being wrong. You run the experiment instead of reasoning about it.
For the full implementation, see here.
.png)

