Made with Dreamstudio.
Do more with less: Refine the 70 billion parameter Llama 2 model on your dataset with a bunch of T4s.
Key Takeaway: Fine-tuning LLMs is feasible even when you’re compute-constrained. This is because dataset sizes tend to be much smaller than pre-training corpuses, which means faster convergence, and we also have a toolkit of techniques that enable us to fit larger models in smaller machines.
So you’ve looked into fine-tuning vs prompt engineering LLMs, and based on your own criteria and needs you’ve decided to go ahead and fine-tune a large language model. 👍 Great!
Now do you have a bunch of A100s just lying around your office? How about H100s or even V100s? If you’re like many of us ML practitioners, probably not. Maybe you have a Google Colab Pro+ or a Lambda Labs account where you can get access to some of these hardware accelerators – certainly a great start for your fine-tuning journey. However, once you get past a certain stage of development, you may want a way to fine-tune a model on your (perhaps proprietary) data in a way that’s reliable and reproducible. This is especially true in a production setting where you need a repeatable, reliable way to fine-tune. In this blog post, you’ll learn how to do just that using a few techniques that can help you do more with less. We’re going to fine-tune the three Llama 2 base model variants exclusively on T4s, using `g4dn.metal` instances on AWS orchestrated through Flyte.
🤔 Memory Requirements
A big consideration when trying to fine-tune a model: Will it fit on my machine? Let’s consider a training run using the Adam optimizer. As you can see from the diagram below, we’ll need to keep track of five sets of values: the model parameters; its activations; gradient updates; and optimizer states, which in this case are momentum and variance.

If we use 32-bit precision to represent the floating-point numbers – and keeping in mind that 32 bits equals 4 bytes – a model with a hundred parameters needs 100 x 4 x 5 = 2,000 bytes of memory. If we scale this up, a model with 1 billion parameters needs 1e9 x 4 x 5 = 2e10 bytes, or 20 gigabytes of memory per billion parameters.
These memory requirements depend on factors that include the choice of optimizer; the batch size; and whether or not you’re using methods like gradient accumulation, gradient checkpointing and many other methods that can improve the throughput or memory efficiency of the training system. In the rest of this post we’ll focus on two such methods: Zero-redundancy Optimization (ZeRO) with DeepSpeed, and QLoRA using `bitsandbytes` and `peft`.
🦾 Doing more with less
Improve memory efficiency with DeepSpeed
ZeRO is a technique that improves the memory efficiency of a distributed training system, which is based on the paper published by a team of researchers at Microsoft in 2019. The basic idea is that we can shard a model’s weights across `n` GPU devices such that each device owns a piece of the model — say, an attention module in a transformer network.
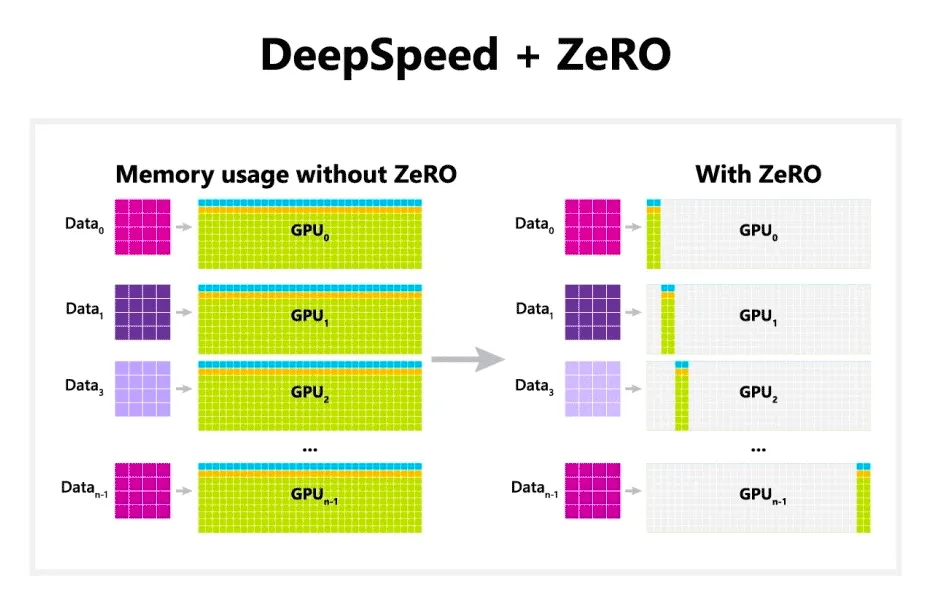
Then you can coordinate the communication of weights and gradients across your devices in a clever way that stores only the minimum information needed for a specific part of a forward or backward pass. In the pseudo-code below, we can see that for the forward pass, we iterate through each layer, do an all-gather operation to distribute the weights of that layer to all the GPUs in the system, run the forward pass for that layer, and then discard the weights in the non-owner devices. Similarly, in the backward pass, we do an all-gather operation to re-compute activations needed for the gradient update computation, then perform a reduce-scatter operation to aggregate all the gradients in the owner device.


Compared to regular data parallelism, where a copy of all the model states are distributed across all the GPUs, the memory reduction with ZeRO scales down linearly with the number of available GPUs while introducing a communication overhead for passing all of that data around.
Distributed Training with DeepSpeed on Flyte
Fortunately for us, we can use DeepSpeed, which has streamlined integrations with the 🤗 Hugging Face transformers library to do all of the heavy lifting for us. Our primary concern is provisioning the compute resources that we need to leverage DeepSpeed in a distributed training setting.
To do that, we’re going to use flytekit’s `Elastic` plugin, which automatically runs `torch run` distributed training jobs on the requested resources.
As you can see from the code snippet above:
- We’re using the `Resources` class to request for a node with 8 GPUs, 64 CPUs, 256 gigabytes of memory, and 200 gigabytes of ephemeral storage. Depending on how you configure GPUs on your Flyte cluster, this will map onto a specific instance in the cloud platform that you’re using to host the Flyte cluster. In the case of this blog post, we specified `g4dn.metal` instances on AWS.
- We specify the `Elastic` task configuration, requesting three such instances that fulfill the resource requirements outlined in (1). We also want to specify `nproc_per_node=8` so that we fully utilize all eight GPU devices on each node, and finally set a timeout on the rendezvous configuration, which allows enough time for the three nodes to discover each other when the task is initialized.
With this configuration, the code in the `train` function will execute automatically as a `torch run` distributed job. If you’re using Hugging Face transformers or pytorch lightning, the trainer should fully utilize all of the compute resources we’ve provisioned for this task. If you’re using pytorch, you’ll need to write your flytekit task code to conform to the conventions expected by torch run.
Multi-node distributed training, however, requires a lot of intercommunication of model state between devices throughout the training process and offloads some of that state to the disk to save on memory. To leverage it, we’re going to need to mount a shared volume to our task. Since Flyte is a Kubernetes-native orchestrator, we can easily do this by specifying a custom PodTemplate:
We can then plug this into our original task decorator:
Finally, we pass in the `deepspeed_config` to the `TrainingArguments` dataclass:
Boilerplate code for training an LLM using the transformers library. The deepspeed configuration can be passed into TrainingArguments class. You can find an example configuration here.
Based on our initial experiments, you can do full parameter fine-tuning on the Llama2-7b and Llama2-13b models using g4dn.metal instances, which has a total of 128 GiB of VRAM. You can try this out on your Flyte or Union Cloud cluster today using this script. As a simple trial run, you can fit this model almost perfectly on the wikipedia `20220301.simple` dataset in just about fifty gradient updates.

In order to train the Llama2-70b models, we’d need larger instances, or more `g4dn.metal` instances to fit all of the model states required for full parameter fine-tuning. Scaling up and out is always an option, but (continuing the theme of this blog post) what if we can do more with less?
Improve parameter and memory efficiency with QLoRA
QLoRA, or Quantized Low Rank Adaptors, is an extension of the original LoRA paper. The LoRA technique allows you to fine-tune a base model by freezing its weights and introducing two lower-rank matrices. When multiplied, these matrices produce a matrix with the same dimensionality as the base model. The lower-rank matrices essentially capture the patterns in the fine-tuning datasets and approximate the weight matrix update that’s applied on top of the base model.

QLoRA builds on top of this main idea by:
- Quantizing the LoRA weights to a 4-bit normal float representation, which improves the memory efficiency of the whole system.
- Performing double quantization, which quantizes the quantization constants to save about 0.37 bits per parameter.
- Paging optimizer states to CPU, which handles memory spikes and prevents out-of-memory errors.

The punchline? You can effectively fine-tune the Llama2-70b parameter model! Let’s see how we can do that in the next section.
Model Parallel Training with `peft` and `bitsandbytes` on Flyte
Using QLoRA is easy using the `peft` and `bitsandbytes` libraries, and running a fine-tuning job on Flyte simply requires requesting the resource on which you want to run your code. Note that we’re not using the `Elastic` plugin in this case, since the 70B parameter model won’t fit on the configured hardware and needs to be trained with model parallelism. The training script used in our experiments can be found here:
Then you can load your tokenizer and model with the following configuration in order to take advantage of the transformer library’s integrations with `peft` and `bitsandbytes`. During the model-loading step, we need to pass in a `BitsAndBytesConfig` class to make sure we load the model using 4-bit floating points. Note that we’re specifying `device_map=”auto”` to achieve Naive Pipeline Parallelism model parallel, which will evenly dispatch the model weights across all available GPUs:
Then we enable gradient checkpointing and prepare the model for QLoRA training by using `prepare_model_for_kbit_training`, `get_peft_model`, and `LoraConfig`:
Finally, we prepare the rest of your training setup by loading the data, the tokenizer, and training arguments and then kick off the training run:
We ran experiments with the 7b, 13b and 70b parameter Llama2 models, and we found that, while the loss curve might appear to be little more noisy than full parameter fine-tuning, we’re able to get fairly stable training signatures while fully utilizing all the devices on a node.


🌅 What’s next?
And there you have it! The main takeaway here is that ML practitioners have a massive incentive to do more with less, and the community is actively developing new techniques to make training more parameter-, memory- and compute-efficient. Future posts in this LLM series will tackle the following questions:
How do we evaluate these models at scale?
Unlike other ML settings, benchmarking LLMs itself also takes a lot of compute power. In this post, we’ll dive into how to use Flyte to evaluate LLMs with standard benchmarks.
How can we effectively leverage adaptor weights for inference?
If I have `k` fine-tuning tasks, how do I store and deploy those weights? There are a few ways of doing this depending on your use case, and in this post we’ll cover various usage patterns and the technologies that facilitate them.
📘 ML engineer’s log
For all you practitioners out there, in this section we’ll cover a few tips that you may want to know when developing and debugging your training setups, regardless of the compute platform or orchestrator that you’re using:
- Use a fast-iteration debugging environment: Google Colab is a great place to get access to GPUs cheaply, but your own company’s Jupyter Hub instance may work as well. If you don’t own a GPU, this is a useful environment for quickly familiarizing yourself with different libraries and state-of-the-art techniques.
- Training the 70B Llama2 model on a `g4dn.metal` instance requires model parallelism: Given the limited memory of a single GPU device on this instance, you’ll need to use `device_map=”auto”` to evenly dispatch the model across all available instances. If you want to do DataDistributedParallel (DDP) training, all of the model states need to fit on a single GPU. For more details, see this issue.
- Read system metric logs carefully: Logging with weights and biases collects metrics every 2 seconds and averages the metric over a 15 second window. This may not provide the complete picture of what’s going on, compared to the raw utilization metadata you might get from rolling your own GPU monitoring system, which is available via the Union Cloud Task-level Monitoring service.
- For multi-node torch run jobs, use gang scheduling or set a generous timeout: DeepSpeed works with multi-node, multi-GPU distributed training via `torch run` to make DDP more memory efficient. Just make sure you configure the timeouts to be large enough so the nodes have enough time to initialize at the beginning of the training run. You can also use gang scheduling to make sure all nodes are scheduled at the same time.
- Mount a shared volume for multi-node training: When doing multi-node training, you may need to specify a shared volume so that offloaded model states can be written to a shared disk. In a Kubernetes-native system, this involves specifying a volume mount on your `PodTemplate`.
- Pre-compile the DeepSpeed installation into your container: To control which DeepSpeed features you want to use, you’ll need to use a base image with the cuda compiler accessible. That way, you can install DeepSpeed with those features pre-compiled. Otherwise, they will be compiled at training time, which adds an unnecessary run-time cost everytime you run a training job (see an example image here).
- For multi-node training, ensure nodes are in the same availability zone: For multi-node training, ensure that the nodes that you’re provisioning are all in the same availability zone, so you don’t incur data transfer costs from your cloud provider.