Papermill
The Papermill plugin lets you run Jupyter notebooks as Flyte tasks. It uses
papermill to parameterize and execute .ipynb files, capture their outputs as typed Flyte values, and render the executed notebook as an HTML report visible in the Flyte UI.
A NotebookTask behaves like any other Flyte task: it has typed inputs and outputs, participates in workflows, runs remotely, integrates with the Flyte type system (including File, Dir, and DataFrame), and can call other Flyte tasks from within the notebook.
When to use this plugin
- Productionizing exploratory notebooks without rewriting them as Python modules
- Generating cell-by-cell HTML reports as task artifacts (charts, tables, narrative analysis)
- Letting data scientists iterate in notebooks while platform teams orchestrate them
- Running notebooks on Spark or with GPU/CPU resources configured on the task environment
Installation
pip install flyteplugins-papermillThe plugin must also be installed in the task image. For example:
import flyte
image = flyte.Image.from_debian_base(name="papermill-env").with_pip_packages(
"flyteplugins-papermill"
)
env = flyte.TaskEnvironment(name="papermill_env", image=image)Quick start
from flyteplugins.papermill import NotebookTask
import flyte
env = flyte.TaskEnvironment(
name="my_env",
image=flyte.Image.from_debian_base(name="my-env").with_pip_packages("flyteplugins-papermill"),
)
add_numbers = NotebookTask(
name="add_numbers",
notebook_path="notebooks/basic_math.ipynb",
task_environment=env,
inputs={"x": int, "y": float},
outputs={"result": float},
)
@env.task
def workflow(x: int = 5, y: float = 3.14) -> float:
return add_numbers(x=x, y=y)notebook_path may be relative (resolved against the calling file’s directory) or absolute.
Notebook setup
Each notebook driven by a NotebookTask needs two specially tagged cells.
parameters cell
Tag a cell with parameters and assign default values matching the names declared in inputs={...}. Papermill injects the actual values into a cell appended right after this one at execution time.
# tagged: parameters
x = 0
y = 0.0outputs cell
Tag a cell with outputs and call record_outputs(...) as the last expression of the cell. The function returns a serialized representation of the values, which Jupyter captures as the cell’s displayed output. NotebookTask then reads that captured output from the executed notebook to recover the typed values.
# tagged: outputs
from flyteplugins.papermill import record_outputs
record_outputs(result=x + y)record_outputs accepts any value that the Flyte type system supports such as primitives, File, Dir, DataFrame, dataclasses, etc. The output names and types must match the outputs={...} declaration on the NotebookTask.
Inputs and outputs have different type rules. Inputs are restricted to JSON-serializable primitives plus File/Dir/DataFrame because papermill’s parameter mechanism is JSON-only. Outputs go through the full Flyte type engine inside the notebook via record_outputs, so dataclasses and any other Flyte-supported type work there.
If a notebook has no outputs, omit the outputs cell and don’t pass outputs to NotebookTask. The notebook still runs and its HTML report is rendered, but no values are returned.
Inputs and outputs
Supported input types
Notebook parameters are passed through papermill, which only accepts JSON-serializable values. The plugin allows:
- Primitives:
int,float,str,bool,list,dict,None - Flyte I/O types:
flyte.io.File,flyte.io.Dir,flyte.io.DataFrame(serialized to their path/URI strings)
Passing any other type raises TypeError at call time. Wrap unsupported values in a dataclass and serialize them to a primitive container, or write them to a File/Dir first.
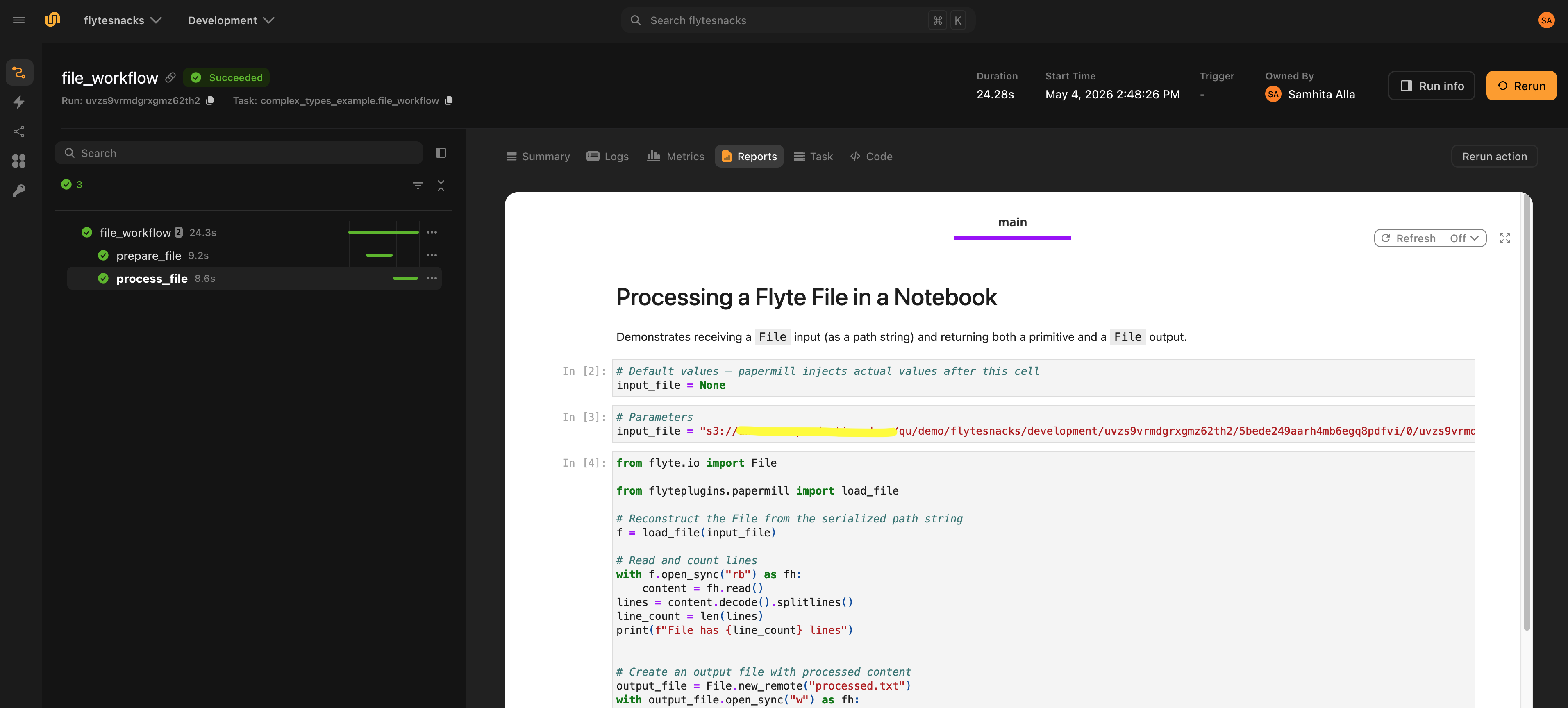
Complex types: File, Dir, DataFrame
File, Dir and DataFrame are passed to the notebook as plain path/URI strings. Reconstruct them inside the notebook with the provided helpers:
from flyteplugins.papermill import load_file, load_dir, load_dataframe
# input_file, input_dir, input_df were injected as strings by papermill
f = load_file(input_file) # -> flyte.io.File
d = load_dir(input_dir) # -> flyte.io.Dir
df = load_dataframe(input_df) # -> flyte.io.DataFrame (parquet by default)load_dataframe accepts a fmt argument (default "parquet") for non-parquet storage formats.
Jupyter supports top-level await, so use it directly for async I/O:
import pandas as pd
from flyte.io import DataFrame
pdf = await df.open(pd.DataFrame).all()
output_df = await DataFrame.from_local(pdf)To return a DataFrame from a notebook, materialize it as a flyte.io.DataFrame and pass it to record_outputs:
# tagged: outputs
import pandas as pd
from flyte.io import DataFrame
from flyteplugins.papermill import record_outputs
result_df = pd.DataFrame({"name": ["alice", "bob"], "score": [90, 75]})
output = await DataFrame.from_local(result_df)
record_outputs(filtered_df=output, row_count=len(result_df))The same pattern applies to File (await File.from_local(...)) and Dir (await Dir.from_local(...)).
Outputs: single, multiple, none
A NotebookTask returns:
- A single value when
outputshas one entry - A tuple in the order declared in
outputswhen there are multiple entries Nonewhenoutputsis omitted
# Multiple outputs
text_analysis = NotebookTask(
name="text_analysis",
notebook_path="notebooks/text.ipynb",
task_environment=env,
inputs={"text": str, "n": int},
outputs={"repeated": str, "word_count": int, "char_count": int},
)
@env.task
def workflow(text: str, n: int) -> tuple[str, int, int]:
repeated, word_count, char_count = text_analysis(text=text, n=n)
return repeated, word_count, char_count# No outputs — useful for side-effect-only notebooks (reports, exports)
printer = NotebookTask(
name="printer",
notebook_path="notebooks/print_report.ipynb",
task_environment=env,
inputs={"message": str},
)
@env.task
def report_workflow(message: str = "hello"):
printer(message=message)If a declared output is missing from record_outputs(...), NotebookTask raises TypeError listing the missing names.
Calling Flyte tasks from notebooks
You can call other Flyte tasks directly from inside a notebook. The plugin injects the parent task’s runtime context into the notebook kernel at the start of execution, so task calls are routed through the Flyte controller automatically, so no manual setup required.
When running remotely, each task call is submitted to Flyte and appears as a separate node in the run graph. When running locally, the calls execute in-process as regular Python functions.
# Inside a notebook cell
from my_tasks import expensive_task
result = await expensive_task(data=42)Sync tasks can be called the same way:
from my_tasks import compute_total
total = compute_total(values=[1, 2, 3])The setup cell that initializes the runtime context is injected automatically and stripped from the rendered HTML report and the uploaded .ipynb files, so it never shows up to users.
Workflow patterns
Chaining notebooks
Outputs from one NotebookTask can feed directly into another:
@env.task
def chained_workflow(a: int, b: float, c: float) -> float:
intermediate = step1_add(x=a, y=b)
final = step2_add(x=int(intermediate), y=c)
return finalMixing notebooks with regular tasks
NotebookTask composes with @env.task functions in either direction:
@env.task
def mixed_workflow(n: int) -> float:
doubled = double(n=n) # regular task
nb_result = notebook_add(x=doubled, y=100.0) # notebook task
return add(a=nb_result, b=0.5) # regular taskInline definition
NotebookTask can be created inside a task function rather than at module scope. The resolver bakes the notebook path and type schemas into the task spec at registration time, so no module-level reference is required at execution.
@env.task
def workflow(x: int = 3, y: float = 1.5) -> int:
from flyteplugins.papermill import NotebookTask
nb = NotebookTask(
name="add_numbers",
notebook_path="notebooks/basic_math.ipynb",
task_environment=env,
inputs={"x": int, "y": float},
outputs={"result": float},
)
return nb(x=x, y=y)Calling from sync vs. async tasks
NotebookTask is internally synchronous. Papermill blocks while the notebook runs. Call it directly from a sync task or use .aio() from an async task:
@env.task
def sync_parent(x: int) -> float:
return notebook(x=x)
@env.task
async def async_parent(x: int) -> float:
return await notebook.aio(x=x)Running a NotebookTask directly as the entrypoint
A NotebookTask can be the workflow entrypoint without wrapping it in another task:
nb = NotebookTask(
name="add_numbers",
notebook_path="notebooks/basic_math.ipynb",
task_environment=env,
inputs={"x": int, "y": float},
outputs={"result": float},
)
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.with_runcontext(mode="remote", copy_style="all").run(nb, x=3, y=1.5)
print(run.url)Reports and notebook artifacts
HTML report (default)
Every NotebookTask execution renders the executed notebook to HTML and logs it to the Flyte Report tab for that task. This happens whether the notebook succeeds or fails — see
Failure reports below. The report is on by default and requires no configuration.
Notebook artifacts
By default the executed notebook lives only inside the rendered HTML report. To get the source and executed .ipynb files as typed Flyte outputs (so downstream tasks can read them or so they show up as artifacts in the run UI), set output_notebooks=True:
notebook = NotebookTask(
name="analysis",
notebook_path="notebooks/analysis.ipynb",
task_environment=env,
inputs={"x": int},
outputs={"result": float},
output_notebooks=True,
)
@env.task
def workflow(x: int = 5) -> tuple[float, File, File]:
result, source_nb, executed_nb = notebook(x=x)
return result, source_nb, executed_nbWhen enabled, two outputs are appended to the task’s interface automatically:
output_notebook: The source.ipynb(no executed cell outputs)output_notebook_executed: The executed.ipynb(with cell outputs)
The names output_notebook and output_notebook_executed are reserved when output_notebooks=True. Don’t use them as your own user output names.
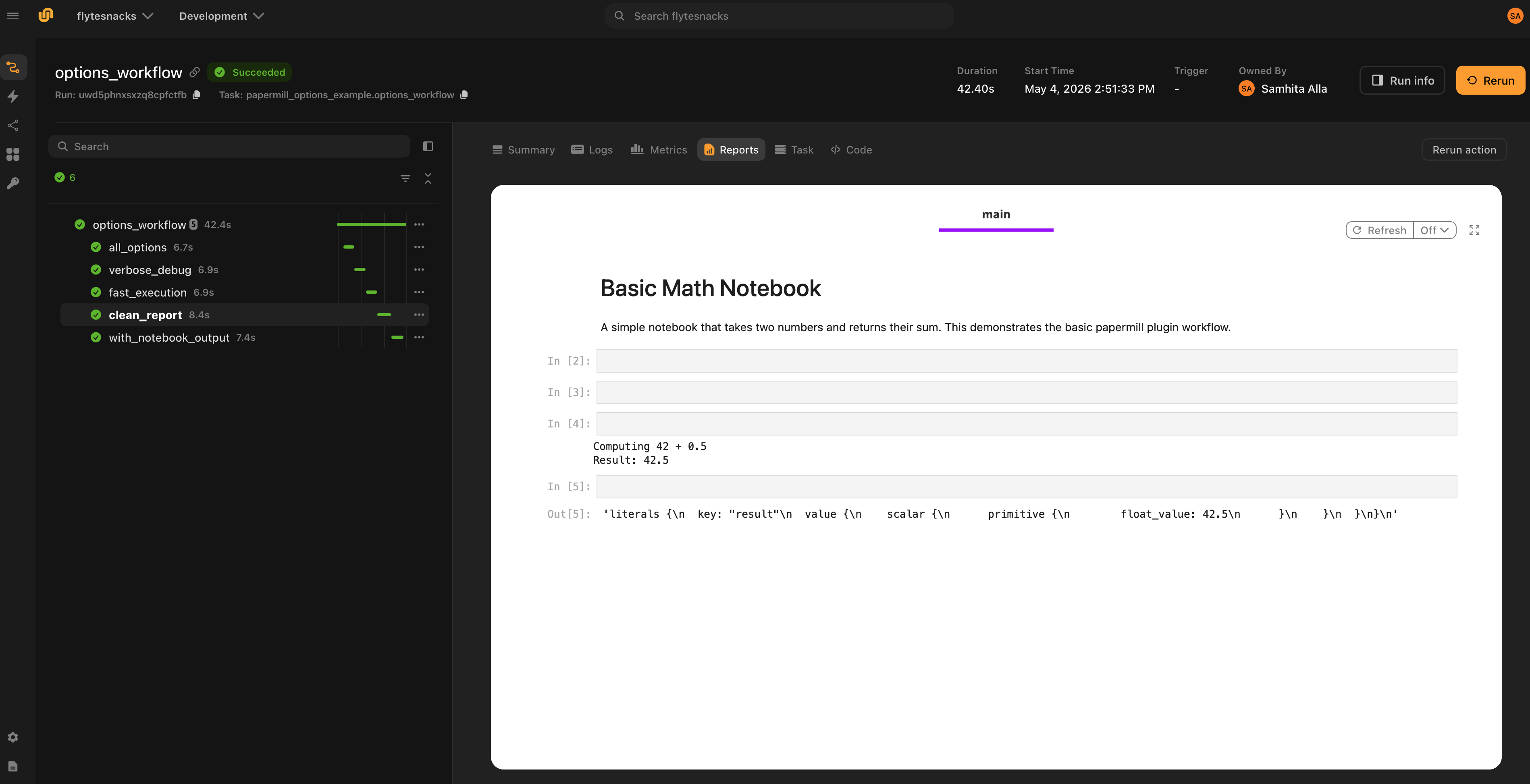
Clean reports
report_mode=True tells papermill to mark input cells with a source_hidden flag during execution. The plugin then strips those input cells from both the rendered HTML report and the uploaded .ipynb files, so only cell outputs (charts, tables, text) remain. This produces a clean stakeholder-facing report without exposing the underlying code.
notebook = NotebookTask(
...
report_mode=True,
output_notebooks=True,
)
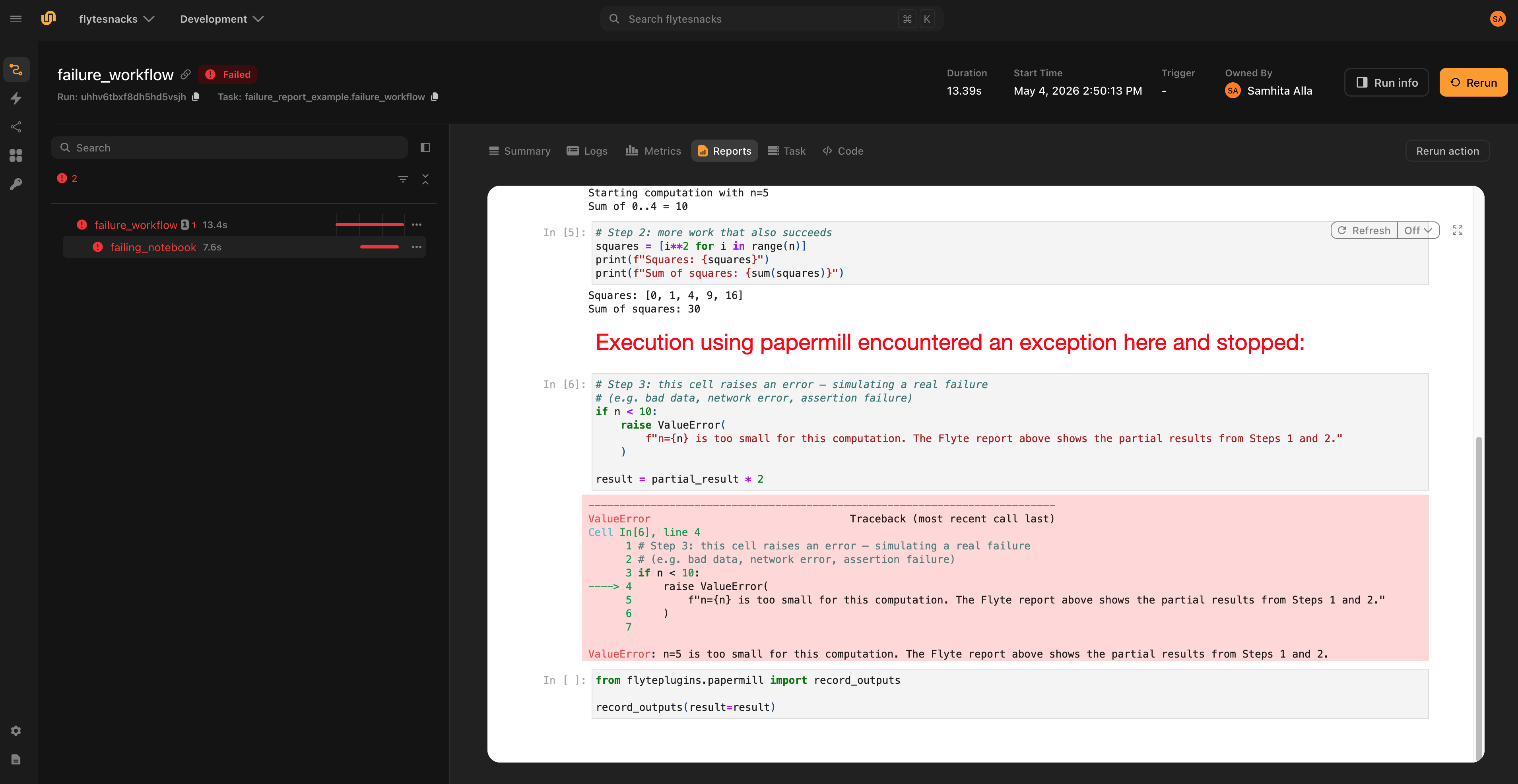
Failure reports
The HTML report is rendered even when the notebook fails. Papermill writes the output notebook cell-by-cell as it executes, so the partial notebook is on disk when an exception propagates out. The plugin renders this partial notebook to HTML and flushes it to the Flyte Report before re-raising the error, giving full visibility into which cell failed and what output the earlier cells produced.
This is especially useful for long-running notebooks: you can inspect partial results without re-running the whole pipeline.
Spark notebooks
Pass plugin_config=Spark(...) to run a notebook inside a Spark driver pod managed by the Spark on Kubernetes Operator:
from flyteplugins.papermill import NotebookTask
from flyteplugins.spark import Spark
spark_nb = NotebookTask(
name="spark_analysis",
notebook_path="notebooks/spark_analysis.ipynb",
task_environment=env,
plugin_config=Spark(
spark_conf={
"spark.executor.instances": "2",
"spark.executor.memory": "2g",
"spark.executor.cores": "1",
"spark.driver.memory": "1g",
"spark.driver.cores": "1",
},
),
inputs={"data": list},
outputs={"total": int, "count": int},
)Inside the notebook, build the SparkSession directly:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("FlyteSpark").getOrCreate()SparkContext.addPyFile() is not called for notebook tasks. The notebook kernel runs in a subprocess that cannot share state with the parent task process, so dynamic code distribution via addPyFile is not supported. Executor pods use the same Docker image as the driver, so any package needed in UDFs must be installed in the image.
See the
Spark plugin page for the full Spark configuration reference.
Local testing
Calling a NotebookTask as a regular Python function outside any Flyte runner executes the notebook synchronously through papermill and returns Python values:
result = add_numbers(x=1, y=2.5)In this mode:
- The notebook runs in-process (no remote submission)
- No HTML report is rendered (no task context)
FileandDiroutputs created inside the notebook resolve to local paths- No plugin lifecycle hooks fire (so no Spark cluster is provisioned, etc.)
This makes iteration on notebook logic fast. You can run the task from a script, REPL or test without going through Flyte at all.
Execution options
NotebookTask exposes the full set of papermill execution knobs. The snippet below shows example values. See
the reference table for defaults.
NotebookTask(
name="all_options",
notebook_path="notebooks/basic_math.ipynb",
task_environment=env,
inputs={"x": int, "y": float},
outputs={"result": float},
kernel_name="python3", # default None - use kernel from notebook metadata
language=None, # rarely needed; overrides notebook language
execution_timeout=300, # default None - no per-cell timeout
start_timeout=120, # default 60 seconds to wait for kernel startup
log_output=True, # default False; stream cell output to task log
progress_bar=True, # default True; tqdm-style progress in logs
report_mode=False, # default False; True hides input cells in report
request_save_on_cell_execute=True, # default True; save after every cell (nbclient)
engine_name=None, # default None - nbclient
engine_kwargs={"autosave_cell_every": 30}, # extra kwargs forwarded to engine
)request_save_on_cell_execute is largely redundant in remote execution: the plugin always renders and uploads the partial notebook on failure, so crash diagnostics don’t depend on it. Leave it on its default unless using a custom engine that requires it.
NotebookTask reference
| Parameter | Default | Description |
|---|---|---|
name |
— | Task name |
notebook_path |
— | Path to the .ipynb, relative to the calling file or absolute |
task_environment |
— | TaskEnvironment for registration and remote execution |
inputs |
None |
{name: type} dict of notebook inputs |
outputs |
None |
{name: type} dict of notebook outputs |
plugin_config |
None |
Plugin config — currently only Spark(...) is supported. Sets the task type accordingly. |
kernel_name |
None |
Jupyter kernel name; None uses the kernel from notebook metadata |
engine_name |
None |
Papermill engine; None uses the default nbclient engine |
log_output |
False |
Stream cell output to the task log |
start_timeout |
60 |
Seconds to wait for kernel startup |
execution_timeout |
None |
Per-cell timeout in seconds; None means no timeout |
report_mode |
False |
Strip input cells from the report and uploaded .ipynb |
request_save_on_cell_execute |
True |
Save notebook after every cell (nbclient engine only) |
progress_bar |
True |
Show a tqdm-style progress bar during execution |
language |
None |
Override notebook language (rarely needed) |
engine_kwargs |
{} |
Extra kwargs forwarded to the papermill engine |
output_notebooks |
False |
Upload source and executed .ipynb as File task outputs |
Helper functions
These are imported from flyteplugins.papermill and called from inside the notebook.
| Function | Purpose |
|---|---|
record_outputs(**kwargs) |
Records outputs from the outputs-tagged cell. Must be the cell’s last expression. Accepts any Flyte-typed values. |
load_file(path) |
Reconstructs a flyte.io.File from the path string injected by papermill. |
load_dir(path) |
Reconstructs a flyte.io.Dir from the path string injected by papermill. |
load_dataframe(uri, fmt="parquet") |
Reconstructs a flyte.io.DataFrame from the URI string injected by papermill. |