# Financial research agent
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/financial_research_agent).
This example demonstrates how to build a financial research and earnings-cycle agent on Flyte. For each company, the agent runs grounded, source-cited research and fresh news, then synthesizes an analyst-ready equity briefing.
Financial research benefits from **low-latency, ranked, source-cited results** across both the general web and news streams. The [You.com Research API](https://you.com/docs/research/overview) produces a grounded, citation-backed synthesis, and the [You.com Search API](https://you.com/docs/search/overview) adds a fresh-news layer. [Claude](https://docs.anthropic.com/) via [LiteLLM](https://docs.litellm.ai/) turns that evidence into an analyst-ready briefing. Flyte's `cache="auto"` reuses prior results when runs converge on the same companies.
Flyte provides:
- **Fan-out parallelism** across companies
- **`cache="auto"`** to reuse prior You.com and LLM results across converging runs
- **`@flyte.trace`** on every external call for full prompt → citation lineage
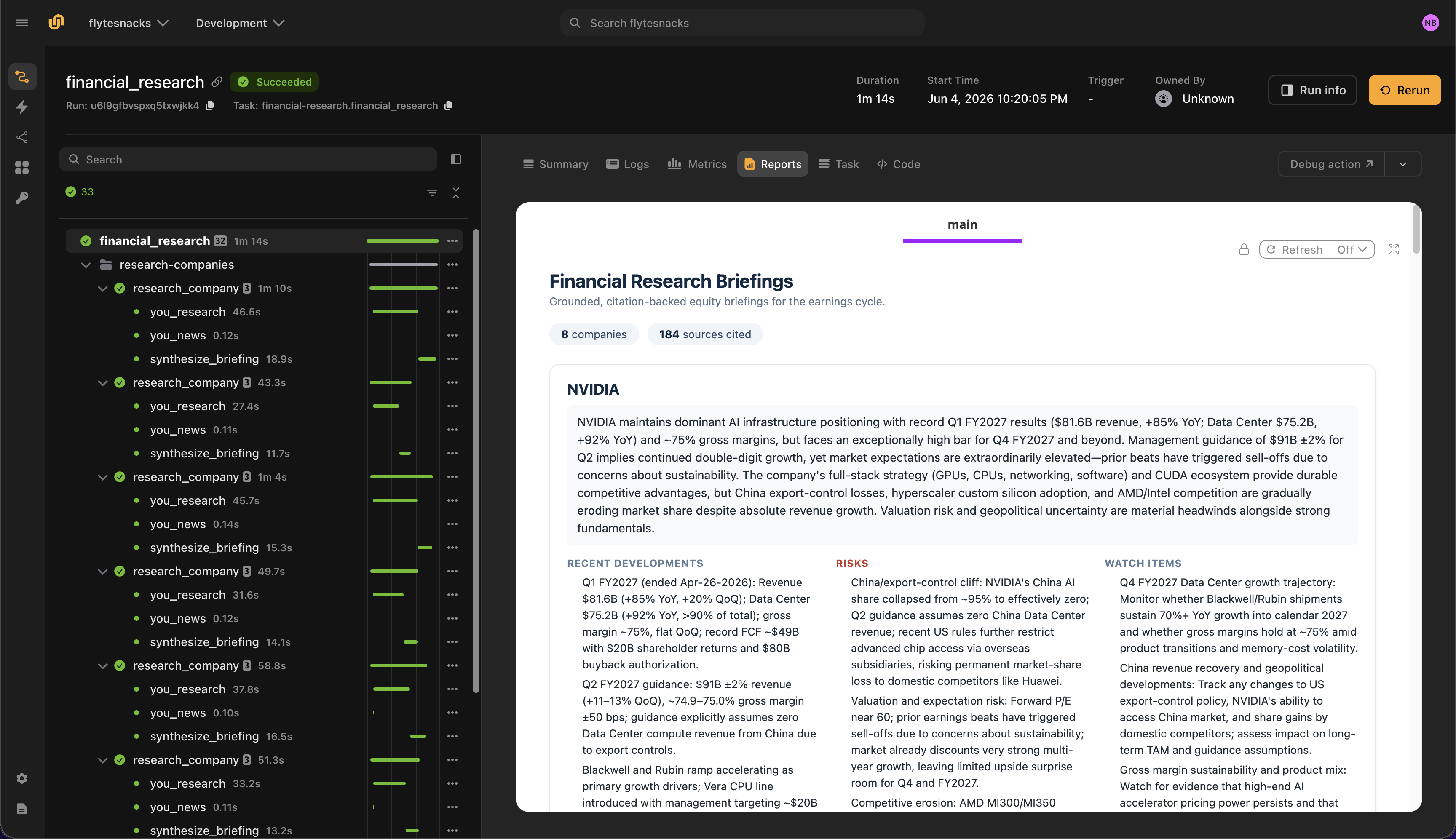
- **Flyte reports** with thesis, risks, watch items, and source citations per company
## Setting up the environment
The agent runs in a `TaskEnvironment` with secrets for the You.com and Anthropic API keys, automatic caching, and a container image built from the `uv` script dependencies.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"“{s.snippet}”
" if s.snippet else ""
return (
f"
"
f"
None reported.
"
return "" + "".join(f"- {x}
" for x in items) + "
"
cards = []
for b in report.briefings:
src = "".join(_cite(s) for s in b.sources[:10])
cards.append(
f"{b.company}
"
f"
{b.thesis or 'No thesis generated.'}
"
f"
"
f"
Recent developments
{_ul(b.recent_developments)}"
f"
Risks
{_ul(b.risks)}"
f"
Watch items
{_ul(b.watch_items)}"
f"
"
+ (f"
You.com sources ({len(b.sources)})
{src}" if src else "")
+ "
Financial Research Briefings
Grounded, citation-backed equity briefings — each company
backed by You.com Research synthesis plus fresh Search news.
{len(report.briefings)} companies
{total_sources} You.com sources cited
{''.join(cards) or "
No briefings generated.
"}
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
The Python packages are declared at the top of the file using the `uv` script style:
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# ///
```
## Data types
Each `Briefing` carries a thesis, recent developments, risks, watch items, and a list of `Source` objects from both the Research and Search APIs.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"“{s.snippet}”
" if s.snippet else ""
return (
f""
f"
None reported.
"
return "" + "".join(f"- {x}
" for x in items) + "
"
cards = []
for b in report.briefings:
src = "".join(_cite(s) for s in b.sources[:10])
cards.append(
f"{b.company}
"
f"
{b.thesis or 'No thesis generated.'}
"
f"
"
f"
Recent developments
{_ul(b.recent_developments)}"
f"
Risks
{_ul(b.risks)}"
f"
Watch items
{_ul(b.watch_items)}"
f"
"
+ (f"
You.com sources ({len(b.sources)})
{src}" if src else "")
+ "
Financial Research Briefings
Grounded, citation-backed equity briefings — each company
backed by You.com Research synthesis plus fresh Search news.
{len(report.briefings)} companies
{total_sources} You.com sources cited
{''.join(cards) or "
No briefings generated.
"}
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## You.com Research and Search APIs
The agent uses both You.com APIs in parallel for each company:
- **Research API** (`https://api.you.com/v1/research`) — grounded, citation-backed analysis with configurable `research_effort` (`lite`, `standard`, `deep`, `exhaustive`). See the [Research API reference](https://you.com/docs/api-reference/research/v1-research).
- **Search API** (`https://ydc-index.io/v1/search`) — fresh news headlines with `freshness` filtering. See the [Search API reference](https://you.com/docs/api-reference/search/v1-search).
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"“{s.snippet}”
" if s.snippet else ""
return (
f""
f"
None reported.
"
return "" + "".join(f"- {x}
" for x in items) + "
"
cards = []
for b in report.briefings:
src = "".join(_cite(s) for s in b.sources[:10])
cards.append(
f"{b.company}
"
f"
{b.thesis or 'No thesis generated.'}
"
f"
"
f"
Recent developments
{_ul(b.recent_developments)}"
f"
Risks
{_ul(b.risks)}"
f"
Watch items
{_ul(b.watch_items)}"
f"
"
+ (f"
You.com sources ({len(b.sources)})
{src}" if src else "")
+ "
Financial Research Briefings
Grounded, citation-backed equity briefings — each company
backed by You.com Research synthesis plus fresh Search news.
{len(report.briefings)} companies
{total_sources} You.com sources cited
{''.join(cards) or "
No briefings generated.
"}
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Synthesize briefings with Claude
Claude, routed through LiteLLM, turns the grounded research answer and news headlines into a structured equity briefing grounded in the evidence provided.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"“{s.snippet}”
" if s.snippet else ""
return (
f""
f"
None reported.
"
return "" + "".join(f"- {x}
" for x in items) + "
"
cards = []
for b in report.briefings:
src = "".join(_cite(s) for s in b.sources[:10])
cards.append(
f"{b.company}
"
f"
{b.thesis or 'No thesis generated.'}
"
f"
"
f"
Recent developments
{_ul(b.recent_developments)}"
f"
Risks
{_ul(b.risks)}"
f"
Watch items
{_ul(b.watch_items)}"
f"
"
+ (f"
You.com sources ({len(b.sources)})
{src}" if src else "")
+ "
Financial Research Briefings
Grounded, citation-backed equity briefings — each company
backed by You.com Research synthesis plus fresh Search news.
{len(report.briefings)} companies
{total_sources} You.com sources cited
{''.join(cards) or "
No briefings generated.
"}
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Research one company
The `research_company` task calls both You.com APIs in parallel, collects sources, and synthesizes a structured briefing.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"“{s.snippet}”
" if s.snippet else ""
return (
f""
f"
None reported.
"
return "" + "".join(f"- {x}
" for x in items) + "
"
cards = []
for b in report.briefings:
src = "".join(_cite(s) for s in b.sources[:10])
cards.append(
f"{b.company}
"
f"
{b.thesis or 'No thesis generated.'}
"
f"
"
f"
Recent developments
{_ul(b.recent_developments)}"
f"
Risks
{_ul(b.risks)}"
f"
Watch items
{_ul(b.watch_items)}"
f"
"
+ (f"
You.com sources ({len(b.sources)})
{src}" if src else "")
+ "
Financial Research Briefings
Grounded, citation-backed equity briefings — each company
backed by You.com Research synthesis plus fresh Search news.
{len(report.briefings)} companies
{total_sources} You.com sources cited
{''.join(cards) or "
No briefings generated.
"}
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Orchestration
The `financial_research` driver task fans out across all companies and renders a Flyte report with per-company briefings and citations.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"“{s.snippet}”
" if s.snippet else ""
return (
f""
f"
None reported.
"
return "" + "".join(f"- {x}
" for x in items) + "
"
cards = []
for b in report.briefings:
src = "".join(_cite(s) for s in b.sources[:10])
cards.append(
f"{b.company}
"
f"
{b.thesis or 'No thesis generated.'}
"
f"
"
f"
Recent developments
{_ul(b.recent_developments)}"
f"
Risks
{_ul(b.risks)}"
f"
Watch items
{_ul(b.watch_items)}"
f"
"
+ (f"
You.com sources ({len(b.sources)})
{src}" if src else "")
+ "
Financial Research Briefings
Grounded, citation-backed equity briefings — each company
backed by You.com Research synthesis plus fresh Search news.
{len(report.briefings)} companies
{total_sources} You.com sources cited
{''.join(cards) or "
No briefings generated.
"}
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Run the agent
### Create secrets
Get a You.com API key from the [You.com platform](https://you.com/platform) (see the [quickstart guide](https://you.com/docs/quickstart)). Get an Anthropic API key from the [Anthropic console](https://console.anthropic.com/).
Register both keys as Flyte secrets. The secret key names must match those declared in the `TaskEnvironment`:
```
flyte create secret youdotcom-api-key
flyte create secret internal-anthropic-api-key
```
See [Secrets](https://www.union.ai/docs/v2/union/user-guide/task-configuration/secrets/page.md) for scoping and file-based secrets.
### Run locally or remotely
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/financial_research_agent):
```
cd v2/tutorials/financial_research_agent
uv run --script main.py
```
To test locally without Flyte secrets:
```
export YOU_API_KEY=
export ANTHROPIC_API_KEY=
uv run --script main.py
```
When the run completes, open the Flyte report to review equity briefings with thesis, risks, and You.com source citations for each company.
---
**Source**: https://github.com/unionai/unionai-docs/blob/main/content/tutorials/financial-services/financial-research-agent/_index.md
**HTML**: https://www.union.ai/docs/v2/union/tutorials/financial-services/financial-research-agent/