Multi-agent trading simulation
Code available here; based on work by TauricResearch.
This example walks you through building a multi-agent trading simulation, modeling how agents within a firm might interact, strategize, and make trades collaboratively.
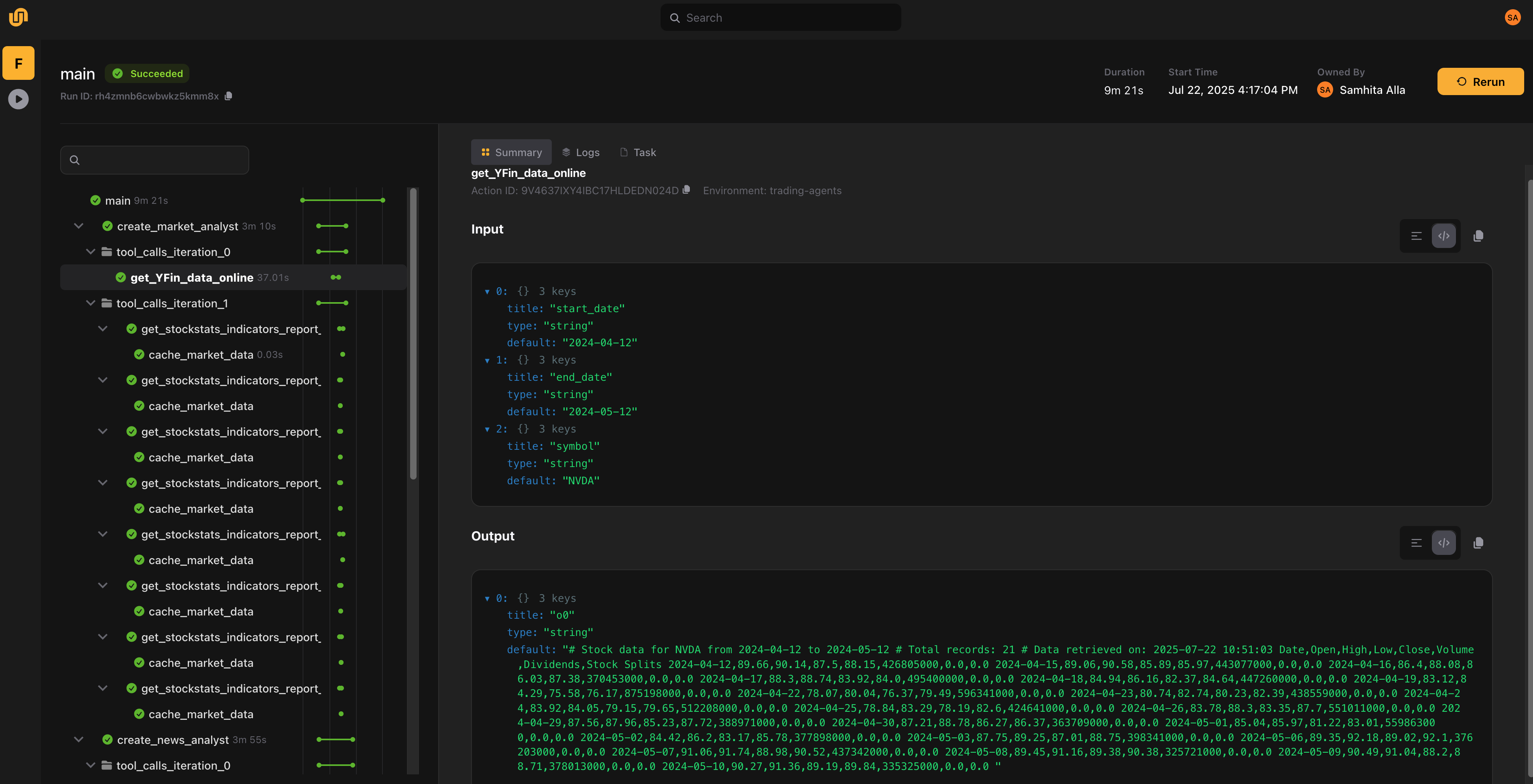 Trading agents execution visualization
Trading agents execution visualization
TL;DR
- You’ll build a trading firm made up of agents that analyze, argue, and act, modeled with Python functions.
- You’ll use the Flyte SDK to orchestrate this world — giving you visibility, retries, caching, and durability.
- You’ll learn how to plug in tools, structure conversations, and track decisions across agents.
- You’ll see how agents debate, use context, generate reports, and retain memory via vector DBs.
What is an agent, anyway?
Agentic workflows are a rising pattern for complex problem-solving with LLMs. Think of agents as:
- An LLM (like GPT-4 or Mistral)
- A loop that keeps them thinking until a goal is met
- A set of optional tools they can call (APIs, search, calculators, etc.)
- Enough tokens to reason about the problem at hand
That’s it.
You define tools, bind them to an agent, and let it run, reasoning step-by-step, optionally using those tools, until it finishes.
What’s different here?
We’re not building yet another agent framework. You’re free to use LangChain, custom code, or whatever setup you like.
What we’re giving you is the missing piece: a way to run these workflows reliably, observably, and at scale, with zero rewrites.
With Flyte, you get:
- Prompt + tool traceability and full state retention
- Built-in retries, caching, and failure recovery
- A native way to plug in your agents; no magic syntax required
How it works: step-by-step walkthrough
This simulation is powered by a Flyte task that orchestrates multiple intelligent agents working together to analyze a company’s stock and make informed trading decisions.
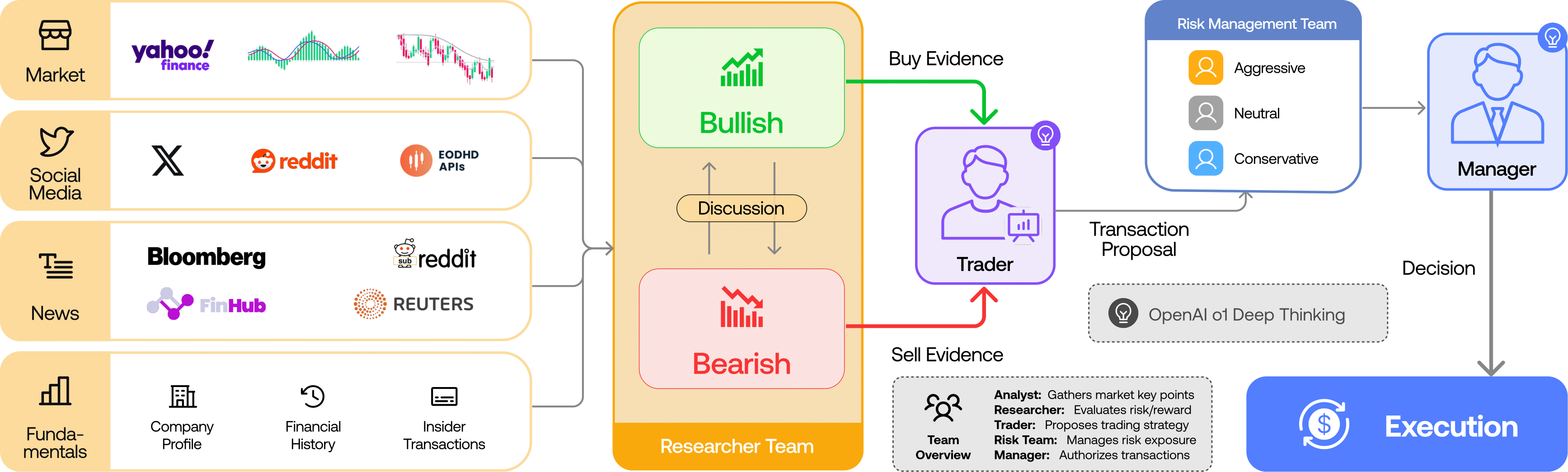 Trading agents schema
Trading agents schema
Entry point
Everything begins with a top-level Flyte task called main, which serves as the entry point to the workflow.
@env.task
async def main(
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> tuple[str, AgentState]:
if not selected_analysts:
raise ValueError(
"No analysts selected. Please select at least one analyst from market, fundamentals, news, or social_media."
)
state = AgentState(
messages=[{"role": "human", "content": company_name}],
company_of_interest=company_name,
trade_date=str(trade_date),
)
# Run all analysts concurrently
results = await asyncio.gather(
*[
run_analyst(analyst, deepcopy(state), online_tools)
for analyst in selected_analysts
]
)
# Flatten and append all resulting messages into the shared state
for messages, report_attr, report in results:
state.messages.extend(messages)
setattr(state, report_attr, report)
# Bull/Bear debate loop
state = await create_bull_researcher(QUICK_THINKING_LLM, state) # Start with bull
while state.investment_debate_state.count < 2 * max_debate_rounds:
current = state.investment_debate_state.current_response
if current.startswith("Bull"):
state = await create_bear_researcher(QUICK_THINKING_LLM, state)
else:
state = await create_bull_researcher(QUICK_THINKING_LLM, state)
state = await create_research_manager(DEEP_THINKING_LLM, state)
state = await create_trader(QUICK_THINKING_LLM, state)
# Risk debate loop
state = await create_risky_debator(QUICK_THINKING_LLM, state) # Start with risky
while state.risk_debate_state.count < 3 * max_risk_discuss_rounds:
speaker = state.risk_debate_state.latest_speaker
if speaker == "Risky":
state = await create_safe_debator(QUICK_THINKING_LLM, state)
elif speaker == "Safe":
state = await create_neutral_debator(QUICK_THINKING_LLM, state)
else:
state = await create_risky_debator(QUICK_THINKING_LLM, state)
state = await create_risk_manager(DEEP_THINKING_LLM, state)
decision = await process_signal(state.final_trade_decision, QUICK_THINKING_LLM)
return decision, state
This task accepts several inputs:
- the list of analysts to run,
- the number of debate and risk discussion rounds,
- a flag to enable online tools,
- the company you’re evaluating,
- and the target trading date.
The most interesting parameter here is the list of analysts to run. It determines which analyst agents will be invoked and shapes the overall structure of the simulation. Based on this input, the task dynamically launches agent tasks, running them in parallel.
The main task is written as a regular asynchronous Python function wrapped with Flyte’s task decorator. No domain-specific language or orchestration glue is needed — just idiomatic Python, optionally using async for better performance. The task environment is configured once and shared across all tasks for consistency.
import flyte
QUICK_THINKING_LLM = "gpt-4o-mini"
DEEP_THINKING_LLM = "o4-mini"
env = flyte.TaskEnvironment(
name="trading-agents",
secrets=[
flyte.Secret(key="finnhub_api_key", as_env_var="FINNHUB_API_KEY"),
flyte.Secret(key="openai_api_key", as_env_var="OPENAI_API_KEY"),
],
image=flyte.Image.from_uv_script("main.py", name="trading-agents", pre=True),
resources=flyte.Resources(cpu="1"),
cache="auto",
)
Analyst agents
Each analyst agent comes equipped with a set of tools and a carefully designed prompt tailored to its specific domain. These tools are modular Flyte tasks — for example, downloading financial reports or computing technical indicators — and benefit from Flyte’s built-in caching to avoid redundant computation.
@env.task
async def get_stockstats_indicators_report_online(
symbol: str, # ticker symbol of the company
indicator: str, # technical indicator to get the analysis and report of
curr_date: str, # The current trading date you are trading on, YYYY-mm-dd"
look_back_days: int = 30, # "how many days to look back"
) -> str:
"""
Retrieve stock stats indicators for a given ticker symbol and indicator.
Args:
symbol (str): Ticker symbol of the company, e.g. AAPL, TSM
indicator (str): Technical indicator to get the analysis and report of
curr_date (str): The current trading date you are trading on, YYYY-mm-dd
look_back_days (int): How many days to look back, default is 30
Returns:
str: A formatted dataframe containing the stock stats indicators
for the specified ticker symbol and indicator.
"""
today_date = pd.Timestamp.today()
end_date = today_date
start_date = today_date - pd.DateOffset(years=15)
start_date = start_date.strftime("%Y-%m-%d")
end_date = end_date.strftime("%Y-%m-%d")
data_file = await cache_market_data(symbol, start_date, end_date)
local_data_file = await data_file.download()
result_stockstats = interface.get_stock_stats_indicators_window(
symbol, indicator, curr_date, look_back_days, True, local_data_file
)
return result_stockstats
When initialized, an analyst enters a structured reasoning loop (via LangChain), where it can call tools, observe outputs, and refine its internal state before generating a final report. These reports are later consumed by downstream agents.
Here’s an example of a news analyst that interprets global events and macroeconomic signals. We specify the tools accessible to the analyst, and the LLM selects which ones to use based on context.
@env.task
async def create_news_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [
toolkit.get_global_news_openai,
toolkit.get_google_news,
]
else:
tools = [
toolkit.get_finnhub_news,
toolkit.get_reddit_news,
toolkit.get_google_news,
]
system_message = (
"You are a news researcher tasked with analyzing recent news and trends over the past week. "
"Please write a comprehensive report of the current state of the world that is relevant for "
"trading and macroeconomics. "
"Look at news from EODHD, and finnhub to be comprehensive. Do not simply state the trends are mixed, "
"provide detailed and finegrained analysis and insights that may help traders make decisions."
""" Make sure to append a Markdown table at the end of the report to organize key points in the report,
organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools("news", state, llm, system_message, tool_names)
Each analyst agent uses a helper function to bind tools, iterate through reasoning steps (up to a configurable maximum), and produce an answer. Setting a max iteration count is crucial to prevent runaway loops. As agents reason, their message history is preserved in their internal state and passed along to the next agent in the chain.
async def run_chain_with_tools(
type: str, state: AgentState, llm: str, system_message: str, tool_names: list[str]
) -> AgentState:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful AI assistant, collaborating with other assistants."
" Use the provided tools to progress towards answering the question."
" If you are unable to fully answer, that's OK; another assistant with different tools"
" will help where you left off. Execute what you can to make progress."
" If you or any other assistant has the FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** or deliverable,"
" prefix your response with FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** so the team knows to stop."
" You have access to the following tools: {tool_names}.\n{system_message}"
" For your reference, the current date is {current_date}. The company we want to look at is {ticker}.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
prompt = prompt.partial(system_message=system_message)
prompt = prompt.partial(tool_names=", ".join(tool_names))
prompt = prompt.partial(current_date=state.trade_date)
prompt = prompt.partial(ticker=state.company_of_interest)
chain = prompt | ChatOpenAI(model=llm).bind_tools(
[getattr(toolkit, tool_name).func for tool_name in tool_names]
)
iteration = 0
while iteration < MAX_ITERATIONS:
result = await chain.ainvoke(state.messages)
state.messages.append(convert_to_openai_messages(result))
if not result.tool_calls:
# Final response — no tools required
setattr(state, f"{type}_report", result.content or "")
break
# Run all tool calls in parallel
async def run_single_tool(tool_call):
tool_name = tool_call["name"]
tool_args = tool_call["args"]
tool = getattr(toolkit, tool_name, None)
if not tool:
return None
content = await tool(**tool_args)
return ToolMessage(
tool_call_id=tool_call["id"], name=tool_name, content=content
)
with flyte.group(f"tool_calls_iteration_{iteration}"):
tool_messages = await asyncio.gather(
*[run_single_tool(tc) for tc in result.tool_calls]
)
# Add valid tool results to state
tool_messages = [msg for msg in tool_messages if msg]
state.messages.extend(convert_to_openai_messages(tool_messages))
iteration += 1
else:
# Reached iteration cap — optionally raise or log
print(f"Max iterations ({MAX_ITERATIONS}) reached for {type}")
return state
Once all analyst reports are complete, their outputs are collected and passed to the next stage of the workflow.
Research agents
The research phase consists of two agents: a bullish researcher and a bearish one. They evaluate the company from opposing viewpoints, drawing on the analysts’ reports. Unlike analysts, they don’t use tools. Their role is to interpret, critique, and develop positions based on the evidence.
@env.task
async def create_bear_researcher(llm: str, state: AgentState) -> AgentState:
investment_debate_state = state.investment_debate_state
history = investment_debate_state.history
bear_history = investment_debate_state.bear_history
current_response = investment_debate_state.current_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="bear-researcher")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
prompt = f"""You are a Bear Analyst making the case against investing in the stock.
Your goal is to present a well-reasoned argument emphasizing risks, challenges, and negative indicators.
Leverage the provided research and data to highlight potential downsides and counter bullish arguments effectively.
Key points to focus on:
- Risks and Challenges: Highlight factors like market saturation, financial instability,
or macroeconomic threats that could hinder the stock's performance.
- Competitive Weaknesses: Emphasize vulnerabilities such as weaker market positioning, declining innovation,
or threats from competitors.
- Negative Indicators: Use evidence from financial data, market trends, or recent adverse news to support your position.
- Bull Counterpoints: Critically analyze the bull argument with specific data and sound reasoning,
exposing weaknesses or over-optimistic assumptions.
- Engagement: Present your argument in a conversational style, directly engaging with the bull analyst's points
and debating effectively rather than simply listing facts.
Resources available:
Market research report: {market_research_report}
Social media sentiment report: {sentiment_report}
Latest world affairs news: {news_report}
Company fundamentals report: {fundamentals_report}
Conversation history of the debate: {history}
Last bull argument: {current_response}
Reflections from similar situations and lessons learned: {past_memory_str}
Use this information to deliver a compelling bear argument, refute the bull's claims, and engage in a dynamic debate
that demonstrates the risks and weaknesses of investing in the stock.
You must also address reflections and learn from lessons and mistakes you made in the past.
"""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Bear Analyst: {response.content}"
new_investment_debate_state = InvestmentDebateState(
history=history + "\n" + argument,
bear_history=bear_history + "\n" + argument,
bull_history=investment_debate_state.bull_history,
current_response=argument,
count=investment_debate_state.count + 1,
)
state.investment_debate_state = new_investment_debate_state
return state
To aid reasoning, the agents can also retrieve relevant “memories” from a vector database, giving them richer historical context. The number of debate rounds is configurable, and after a few iterations of back-and-forth between the bull and bear, a research manager agent reviews their arguments and makes a final investment decision.
@env.task
async def create_research_manager(llm: str, state: AgentState) -> AgentState:
history = state.investment_debate_state.history
investment_debate_state = state.investment_debate_state
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="research-manager")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
prompt = f"""As the portfolio manager and debate facilitator, your role is to critically evaluate
this round of debate and make a definitive decision:
align with the bear analyst, the bull analyst,
or choose Hold only if it is strongly justified based on the arguments presented.
Summarize the key points from both sides concisely, focusing on the most compelling evidence or reasoning.
Your recommendation—Buy, Sell, or Hold—must be clear and actionable.
Avoid defaulting to Hold simply because both sides have valid points;
commit to a stance grounded in the debate's strongest arguments.
Additionally, develop a detailed investment plan for the trader. This should include:
Your Recommendation: A decisive stance supported by the most convincing arguments.
Rationale: An explanation of why these arguments lead to your conclusion.
Strategic Actions: Concrete steps for implementing the recommendation.
Take into account your past mistakes on similar situations.
Use these insights to refine your decision-making and ensure you are learning and improving.
Present your analysis conversationally, as if speaking naturally, without special formatting.
Here are your past reflections on mistakes:
\"{past_memory_str}\"
Here is the debate:
Debate History:
{history}"""
response = ChatOpenAI(model=llm).invoke(prompt)
new_investment_debate_state = InvestmentDebateState(
judge_decision=response.content,
history=investment_debate_state.history,
bear_history=investment_debate_state.bear_history,
bull_history=investment_debate_state.bull_history,
current_response=response.content,
count=investment_debate_state.count,
)
state.investment_debate_state = new_investment_debate_state
state.investment_plan = response.content
return state
Trading agent
The trader agent consolidates the insights from analysts and researchers to generate a final recommendation. It synthesizes competing signals and produces a conclusion such as Buy for long-term growth despite short-term volatility.
@env.task
async def create_trader(llm: str, state: AgentState) -> AgentState:
company_name = state.company_of_interest
investment_plan = state.investment_plan
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="trader")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
context = {
"role": "user",
"content": f"Based on a comprehensive analysis by a team of analysts, "
f"here is an investment plan tailored for {company_name}. "
"This plan incorporates insights from current technical market trends, "
"macroeconomic indicators, and social media sentiment. "
"Use this plan as a foundation for evaluating your next trading decision.\n\n"
f"Proposed Investment Plan: {investment_plan}\n\n"
"Leverage these insights to make an informed and strategic decision.",
}
messages = [
{
"role": "system",
"content": f"""You are a trading agent analyzing market data to make investment decisions.
Based on your analysis, provide a specific recommendation to buy, sell, or hold.
End with a firm decision and always conclude your response with 'FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL**'
to confirm your recommendation.
Do not forget to utilize lessons from past decisions to learn from your mistakes.
Here is some reflections from similar situatiosn you traded in and the lessons learned: {past_memory_str}""",
},
context,
]
result = ChatOpenAI(model=llm).invoke(messages)
state.messages.append(convert_to_openai_messages(result))
state.trader_investment_plan = result.content
state.sender = "Trader"
return state
Risk agents
Risk agents comprise agents with different risk tolerances: a risky debater, a neutral one, and a conservative one. They assess the portfolio through lenses like market volatility, liquidity, and systemic risk. Similar to the bull-bear debate, these agents engage in internal discussion, after which a risk manager makes the final call.
@env.task
async def create_risky_debator(llm: str, state: AgentState) -> AgentState:
risk_debate_state = state.risk_debate_state
history = risk_debate_state.history
risky_history = risk_debate_state.risky_history
current_safe_response = risk_debate_state.current_safe_response
current_neutral_response = risk_debate_state.current_neutral_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
trader_decision = state.trader_investment_plan
prompt = f"""As the Risky Risk Analyst, your role is to actively champion high-reward, high-risk opportunities,
emphasizing bold strategies and competitive advantages.
When evaluating the trader's decision or plan, focus intently on the potential upside, growth potential,
and innovative benefits—even when these come with elevated risk.
Use the provided market data and sentiment analysis to strengthen your arguments and challenge the opposing views.
Specifically, respond directly to each point made by the conservative and neutral analysts,
countering with data-driven rebuttals and persuasive reasoning.
Highlight where their caution might miss critical opportunities or where their assumptions may be overly conservative.
Here is the trader's decision:
{trader_decision}
Your task is to create a compelling case for the trader's decision by questioning and critiquing the conservative
and neutral stances to demonstrate why your high-reward perspective offers the best path forward.
Incorporate insights from the following sources into your arguments:
Market Research Report: {market_research_report}
Social Media Sentiment Report: {sentiment_report}
Latest World Affairs Report: {news_report}
Company Fundamentals Report: {fundamentals_report}
Here is the current conversation history: {history}
Here are the last arguments from the conservative analyst: {current_safe_response}
Here are the last arguments from the neutral analyst: {current_neutral_response}.
If there are no responses from the other viewpoints, do not halluncinate and just present your point.
Engage actively by addressing any specific concerns raised, refuting the weaknesses in their logic,
and asserting the benefits of risk-taking to outpace market norms.
Maintain a focus on debating and persuading, not just presenting data.
Challenge each counterpoint to underscore why a high-risk approach is optimal.
Output conversationally as if you are speaking without any special formatting."""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Risky Analyst: {response.content}"
new_risk_debate_state = RiskDebateState(
history=history + "\n" + argument,
risky_history=risky_history + "\n" + argument,
safe_history=risk_debate_state.safe_history,
neutral_history=risk_debate_state.neutral_history,
latest_speaker="Risky",
current_risky_response=argument,
current_safe_response=current_safe_response,
current_neutral_response=current_neutral_response,
count=risk_debate_state.count + 1,
)
state.risk_debate_state = new_risk_debate_state
return state
The outcome of the risk manager — whether to proceed with the trade or not — is considered the final decision of the trading simulation.
You can visualize this full pipeline in the Flyte/Union UI, where every step is logged. You’ll see input/output metadata for each tool and agent task. Thanks to Flyte’s caching, repeated steps are skipped unless inputs change, saving time and compute resources.
Retaining agent memory with S3 vectors
To help agents learn from past decisions, we persist their memory in a vector store. In this example, we use an S3 vector bucket for their simplicity and tight integration with Flyte and Union, but any vector database can be used.
Note: To use the S3 vector store, make sure your IAM role has the following permissions configured:
s3vectors:CreateVectorBucket
s3vectors:CreateIndex
s3vectors:PutVectors
s3vectors:GetIndex
s3vectors:GetVectors
s3vectors:QueryVectors
s3vectors:GetVectorBucketAfter each trade decision, you can run a reflect_on_decisions task. This evaluates whether the final outcome aligned with the agent’s recommendation and stores that reflection in the vector store. These stored insights can later be retrieved to provide historical context and improve future decision-making.
@env.task
async def reflect_and_store(state: AgentState, returns: str) -> str:
await asyncio.gather(
reflect_bear_researcher(state, returns),
reflect_bull_researcher(state, returns),
reflect_trader(state, returns),
reflect_risk_manager(state, returns),
reflect_research_manager(state, returns),
)
return "Reflection completed."
# Run the reflection task after the main function
@env.task(cache="disable")
async def reflect_on_decisions(
returns: str,
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> str:
_, state = await main(
selected_analysts,
max_debate_rounds,
max_risk_discuss_rounds,
online_tools,
company_name,
trade_date,
)
return await reflect_and_store(state, returns)
Running the simulation
First, set up your OpenAI secret (from openai.com) and Finnhub API key (from finnhub.io):
flyte create secret openai_api_key <YOUR_OPENAI_API_KEY>
flyte create secret finnhub_api_key <YOUR_FINNHUB_API_KEY>Then
clone the repo, navigate to the tutorials-v2/trading_agents directory, and run the following commands:
flyte create config --endpoint <FLYTE_OR_UNION_ENDPOINT> --project <PROJECT_NAME> --domain <DOMAIN_NAME> --builder remote
uv run main.pyIf you’d like to run the reflect_on_decisions task instead, comment out the main function call and uncomment the reflect_on_decisions call in the __main__ block:
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(main)
print(run.url)
run.wait()
# run = flyte.run(reflect_on_decisions, "+3.2% gain over 5 days")
# print(run.url)
Then run:
uv run main.pyWhy Flyte? (A quick note before you go)
You might now be wondering: can’t I just build all this with Python and LangChain? Absolutely. But as your project grows, you’ll likely run into these challenges:
-
Observability: Agent workflows can feel opaque. You send a prompt, get a response, but what happened in between?
- Were the right tools used?
- Were correct arguments passed?
- How did the LLM reason through intermediate steps?
- Why did it fail?
Flyte gives you a window into each of these stages.
-
Multi-agent coordination: Real-world applications often require multiple agents with distinct roles and responsibilities. In such cases, you’ll need:
- Isolated state per agent,
- Shared context where needed,
- And coordination — sequential or parallel.
Managing this manually gets fragile, fast. Flyte handles it for you.
-
Scalability: Agents and tools might need to run in isolated or containerized environments. Whether you’re scaling out to more agents or more powerful hardware, Flyte lets you scale without taxing your local machine or racking up unnecessary cloud bills.
-
Durability & recovery: LLM-based workflows are often long-running and expensive. If something fails halfway:
- Do you lose all progress?
- Replay everything from scratch?
With Flyte, you get built-in caching, checkpointing, and recovery, so you can resume where you left off.